Документация и уроки (старая версия)
- Ядро системы - Маршрутизатор и RAG
- Создание простого агента
- Документация по LLMClient
- Создание ClickHouse - SQL агента
- Руководство по работе с базой знаний (RAG)
- Документация по LLMTracer
- Аналитика и нагрузки
- LLMTracer - Плагин для трассировки запросов к LLM
- Конфигурация
- Ошибки и отладка
- Eval - Тестирование
Ядро системы - Маршрутизатор и RAG
Создание основы мультиагентной системы
Архитектура системы
В основе нашей мультиагентной системы лежит Маршрутизатор - это "диспетчер", который анализирует вопрос пользователя и решает, какой именно агент должен его обработать. По умолчанию система использует RAG для поиска информации в базе знаний.
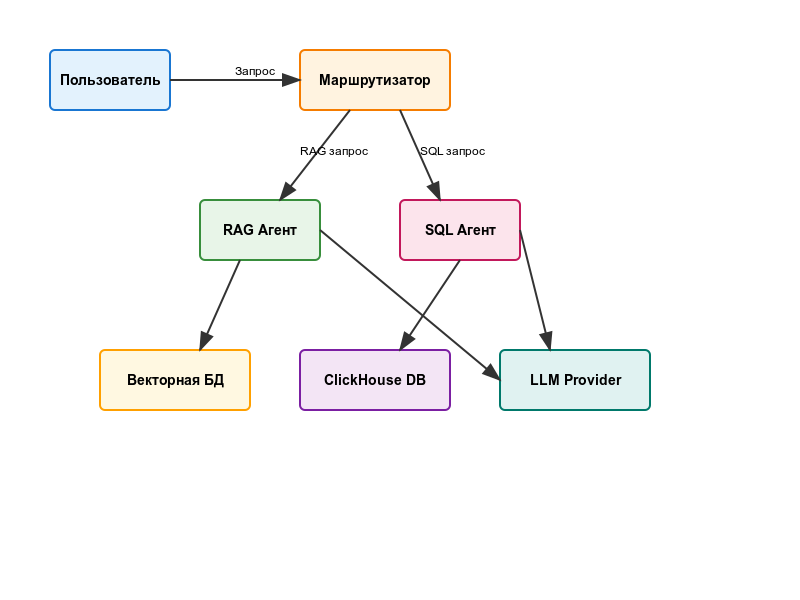
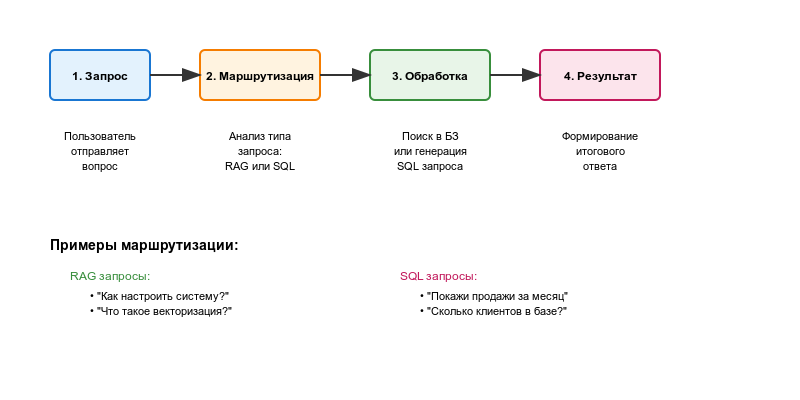
Каждый агент выполняет свою специализированную задачу:
- CompanyInfo - отвечает на вопросы о компании
- SQL-агент - работает с базами данных
Часть 1: Установка и настройка основного агента
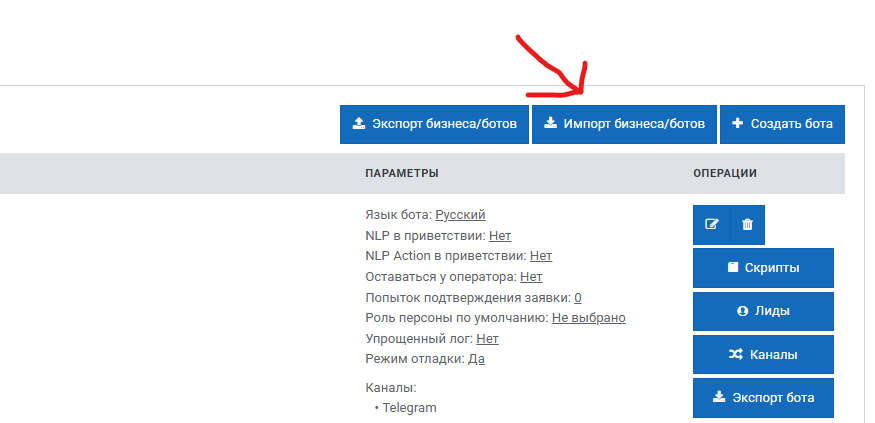
Шаг 1: Импорт готового решения
Мы подготовили готовую конфигурацию, которую можно быстро развернуть:
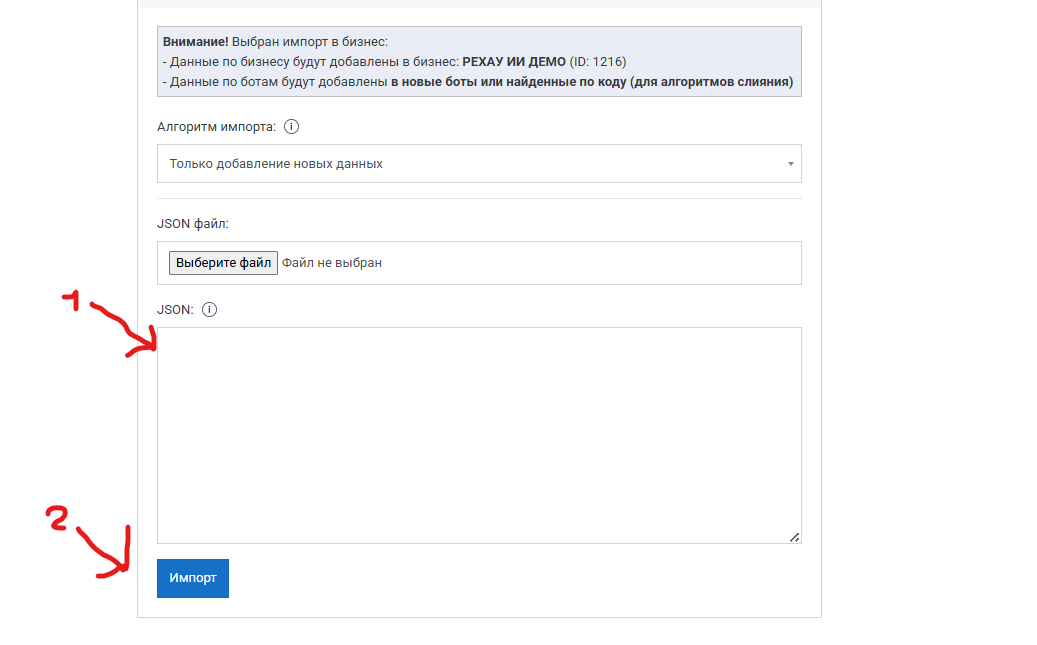
- Перейдите по предоставленной ссылке для скачивания конфигурации
- Скопируйте JSON-код конфигурации
- В интерфейсе Метабот откройте раздел "Импорт бизнеса/ботов"
- Вставьте скопированный JSON и нажмите "Импорт"
Шаг 2: Проверка установленных компонентов
После успешного импорта в вашем боте должны появиться следующие элементы:
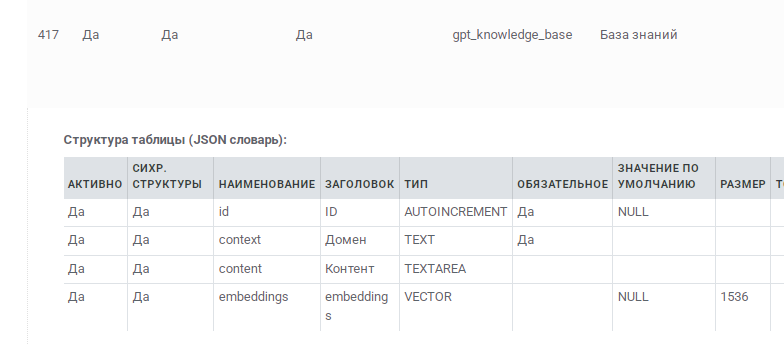
1. Системный раздел MRAG Это ядро системы, которое обрабатывает запросы и управляет агентами.

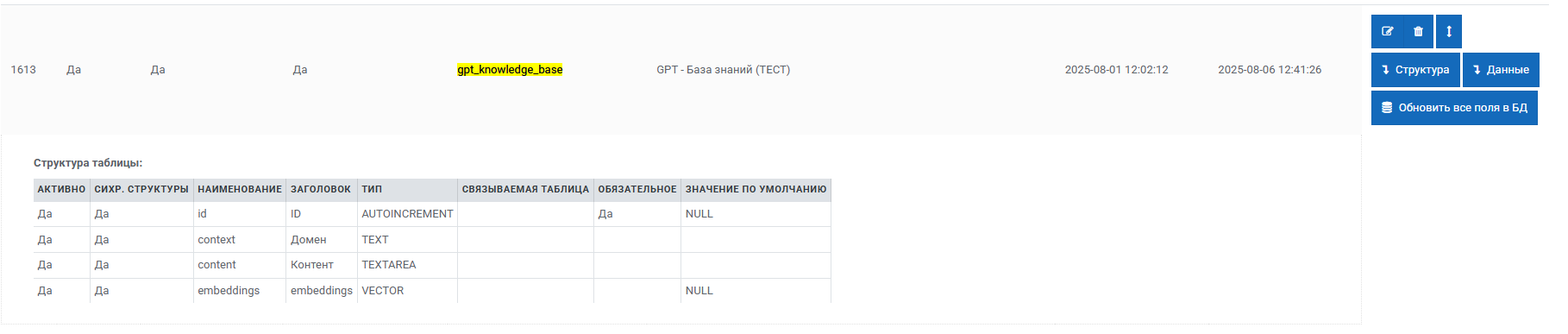
2. Базовые таблицы данных:
gpt_knowledge_base- хранилище знаний для RAGgpt_prompts- коллекция промптов для разных агентов
3. Плагин управления "AgentsParams" Центр управления всеми настройками агентов.

Шаг 3: Настройка конфигурации агентов
Мы создали систему конфигураций, которая позволяет управлять агентами без глубокого понимания кода. Все настройки вынесены в понятные конфигурационные файлы.
Совет для работы: В конфигурации есть множество параметров. Используйте поиск по документации, чтобы быстро найти описание нужного параметра и понять, как он работает.
Основные поля конфигурации:
let activeAgent = lead.getAttr("activeAgent") // Устанавливается при вызове скрипта
let agentCFG = {} // Объект с настройками текущего агента
if (activeAgent === "MainFlow") {
agentCFG = {
common: {
title: "Основной Flow c маршрутизатором", // Понятное название агента
agentName: "MainFlow", // Техническое имя для системы
promptTable: "gpt_prompts", // Таблица с промптами
userQueryAttibName: "user_query", // Атрибут для вопроса пользователя
historyMaxLength: 4, // Сколько сообщений помнить в истории
exitScript: "KB:FollowUp", // Что выполнить после завершения диалога
},
detectRoute: { // Настройки маршрутизатора
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
prompt: "$route_prompt", // Промпт для определения маршрута
routerTools: [{
tools: "RAG_Tools", // Набор доступных инструментов
route: "RAG:DetectIntent_and_FindChunks", // Скрипт для RAG
}],
errorScript: "RAG:ErrorFallback", // Обработка ошибок
},
detectIntent: { // Детектор намерений пользователя
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
prompt: "$rag_intent_prompt", // Промпт для анализа намерений
errorScript: "RAG:ErrorFallback",
kbName: "defKnowBase", // База знаний
kbDomain: "main", // Домен знаний
},
userReply: { // Генератор ответов пользователю
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
errorScript: "RAG:ErrorFallback",
useHistory: 1, // Использовать контекст диалога
addUserQuery: 1, // Добавлять вопрос в промпт
sendBotAnwser: 1, // Отправлять ответ пользователю
systemPrompts: { // Структура промптов
start: [["$start_prompt", "$rag_prompt"]], // Начальные промпты
final: ["$final_prompt"] // Финальные промпты
// Между start и final автоматически вставляется история диалога
},
}
}
} else if (activeAgent === "newAgent") {
// Здесь описываются конфигурации других агентов
// Поля могут отличаться в зависимости от специализации агента
} else {
bot.sendMessage(`MainConfig:snippet - неизвестный activeAgent: ${activeAgent}`)
bot.stop()
}
Шаг 4: Настройка таблицы промптов
Промпты - это инструкции для ИИ. Они определяют, как агент будет вести себя и отвечать на вопросы.
Процедура настройки:
- Откройте таблицу
gpt_promptsв интерфейсе Метабот - Создайте промпт для каждого агента с уникальным именем
- Заполните три обязательных поля:
agent_name- имя агента (например: "MainFlow")name- название промпта (например: "route_prompt")prompt- содержание промпта с макропеременными
Пример настройки промпта маршрутизатора в таблице:
agent_name: MainFlow
name: route_prompt
prompt: Ты агент ИИ который отвечает на вопросы о компании {{@company_name}}.
У тебя есть инструменты в распоряжении:
<tools>
**RAG_Tools** - Используется, когда нужно ответить на вопросы об услугах
и продукции компании, об условиях эксплуатации продукции, об используемых
инструментах для монтажа продукции и т.д.
</tools>
Учитывая историю и запрос пользователя, сделай вывод о реальном намерении
пользователя. Отвечай на русском языке без лишних рассуждений и вопросов.
История чата:
"""{{$chat_history_str}}"""
Запрос пользователя:
"""{{$user_query}}"""
Пожалуйста, отвечай как можно точнее и всегда обязательно указывай инструмент (Tools).
Ответ всегда должен быть представлен в виде JSON-объекта, в котором выводятся
указанные ниже поля. JSON в самом конце! Без пояснений.
{
"tools": "", string: название выбранных вами инструментов
"user_intent": "", string: подробное намерение пользователя для системы RAG
"request": "" "полученный вами запрос"
}
Система макросов в промптах
Для динамической подстановки данных используйте макросы:
Данные из лида: {{$lead_attr}} - любой атрибут лида
Данные из бота: {{@bot_attr}} - любой атрибут бота
Системные макросы:
{{$chat_history_str}}- история диалога в текстовом виде{{$user_query}}- текущий вопрос пользователя
Часть 2: Настройка API-доступа
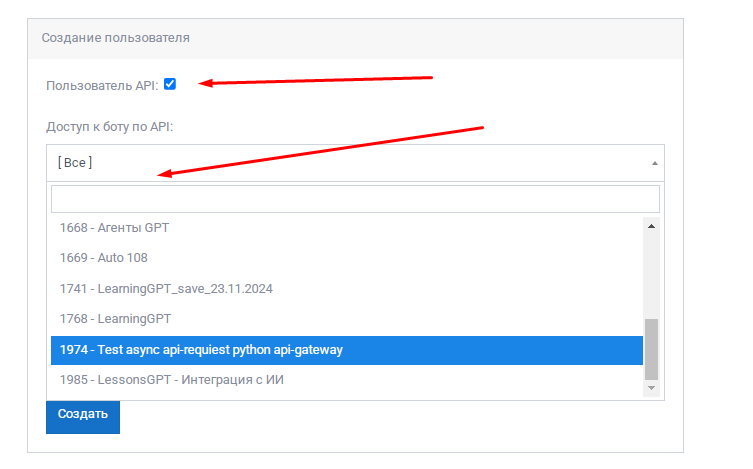
Шаг 5: Создание API-пользователя
Для работы мультиагентной системы необходимо настроить API-доступ:
- В настройках бизнеса создайте нового пользователя
- Установите галочку "Пользователь API"
- Предоставьте доступ к нужным ботам (всем или выбранным)
- Назначьте соответствующую роль доступа
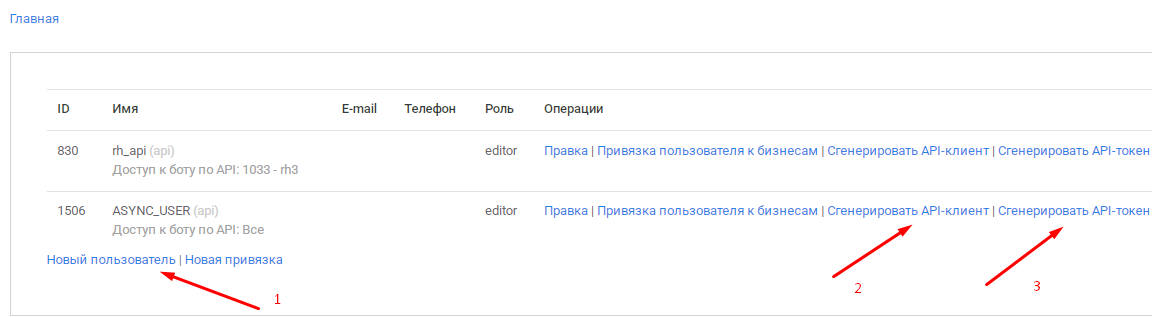
Генерация токена доступа:
- Создайте API-клиента для пользователя
- Сгенерируйте токен доступа
- Важно: Сохраните токен - он потребуется для подключения к API-шлюзу
- Обязательно: Используйте токен в режиме 3
Шаг 6: Регистрация в API-шлюзе
API-шлюз обеспечивает асинхронное взаимодействие между компонентами системы.
- Обратитесь в поддержку. Сейчас регистрация производится специалистами Метабот.
- Сообщите им параметры регистрации:
bot_id- идентификатор вашего ботаtoken- токен API, полученный на предыдущем шагеdomain- доменное имя сервера, где размещен бот. Напримерhttps://app.metabot24.com
Часть 3: Запуск и тестирование
Шаг 7: Создание пользовательского интерфейса
Создайте скрипт, который позволит пользователям взаимодействовать с системой:
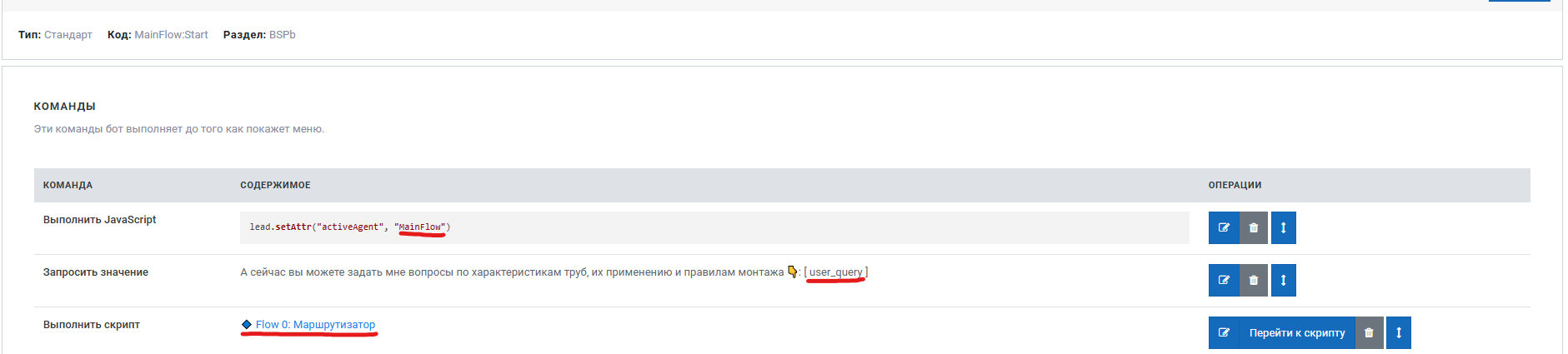
Ключевые параметры запуска:
- MainFlow - выбор основного агента для обработки запроса
- user_query - атрибут для сохранения вопроса пользователя
- Flow 0 - запуск скрипта маршрутизатора
Результат работы системы
При правильной настройке ваша мультиагентная система будет:
- Понимать контекст диалога и поддерживать связную беседу
- Автоматически определять наиболее подходящий агент для каждого вопроса
- Использовать базу знаний для предоставления точных ответов
- Обращаться к специализированным агентам при необходимости (SQL-агент, CompanyInfo и др.)
Система готова к работе и может быть расширена дополнительными агентами в зависимости от ваших потребностей.
Создание простого агента
Введение
После того как основная мультиагентная система запущена и работает, добавление новых агентов становится простой задачей. Мы создаем специализированных помощников, каждый из которых решает определенный круг задач.
В этом разделе мы создадим агента CompanyInfo, который будет отвечать исключительно на вопросы о компании - контакты, адреса офисов, время работы. Особенность этого агента в том, что он не обращается к RAG базе знаний, а хранит всю информацию прямо в промпте. Это упрощает работу модели и ускоряет получение ответов.
Этап 1: Подготовка информации о компании
Создание промпта с данными компании
Первым делом подготовим базовый промпт с информацией о компании. Назовем его about_prompt:
_**ЦЕНТРАЛЬНЫЙ ОФИС**_
**Контакты**
Адрес: 123456, г. Примерск, ул. Центральная, дом 10А
Горячая линия: 8 800 000 00 00 (бесплатно по России)
Часы работы: пн-вс с 9:00 до 21:00
**Отдел качества:** +7 (900) 123-45-67
Часы работы: пн-вс с 9:00 до 21:00
**Интернет-банк:** 8 804 000 11 11
**Главный офис обслуживания, пос. Банковский**
Адрес: 140000, Примерская область, г. Финансск, д. Кредитное,
ул. Сберегательная, д.1, стр. 1
Телефон: +7 (900) 765-43-21
Часы работы: пн-пт c 9:00 до 18:00
**Склад документов «ПримерБанк»**
Адрес: Россия, 140001, Примерская область, рп. Храновск,
ул. Архивная, д. 5
Телефон: +7 (900) 111-22-33
Часы работы: пн-чт 9.00-18.00, пт 9.00-16.30
Подробнее: https://primerbank.ru/contacts
---
_**ОФИСЫ В РЕГИОНАХ**_
**Воронеж**
394000, г. Примероград, ул. Финансовая, 8, оф. 101
Тел.: +7 (902) 234-56-78
**Екатеринбург**
620000, г. Примерск-Урал, ул. Сибирская, 22, оф. 5
Тел.: +7 (903) 345-67-89
**Краснодар**
350000, г. Примеродар, ул. Южная, 50
Тел.: +7 (904) 456-78-90
Добавление промпта в систему
Откройте таблицу gpt_prompts и создайте новую запись:
- agent_name:
CompanyInfo - name:
about_prompt - prompt: вставьте текст выше
Этап 2: Интеграция агента в систему
Для подключения нового агента нужно выполнить три шага в строгом порядке:
- Конфигурация - описать параметры агента
- Скрипт - создать логику обработки
- Маршрутизация - добавить в систему выбора агентов
Шаг 1: Обновление конфигурации
Откройте плагин AgentsParams и найдите секцию с основным агентом. Нам нужно:
А) Добавить новый инструмент в маршрутизатор
В секции detectRoute найдите routerTools и дополните массив:
detectRoute: {
// ... остальные параметры остаются без изменений
routerTools: [{
tools: "RAG_Tools", // Существующий инструмент
route: "RAG:DetectIntent_and_FindChunks"
}, {
tools: "INFO_Tools", // Новый инструмент для информации о компании
route: "CompanyInfo" // Имя скрипта, который создадим далее
}],
// ... остальные параметры остаются без изменений
}
Б) Создать конфигурацию для нового агента
Добавьте новое условие после основного блока MainFlow:
else if (activeAgent === "CompanyInfo") { // Агент для работы с информацией о компании
agentCFG = {
common: {
title: "About Agent", // Понятное имя агента
agentName: "CompanyInfo", // Техническое имя
promptTable: "gpt_prompts", // Таблица с промптами
userQueryAttibName: "user_query", // Атрибут с вопросом пользователя
historyMaxLength: 4, // Длина истории диалога
exitScript: "MainFlow:FollowUp" // Скрипт завершения
},
userReply: { // Настройки генерации ответов
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
errorScript: "RAG:ErrorFallback", // Обработка ошибок
useHistory: 1, // Использовать историю диалога
addUserQuery: 1, // Добавлять вопрос пользователя
sendBotAnwser: 1, // Отправлять ответ пользователю
systemPrompts: {
start: ["$about_prompt"], // Промпт с информацией о компании
final: [] // Финальные промпты (пустой массив)
// Структура: about_prompt + история диалога
},
}
}
}
Шаг 2: Создание скрипта агента
Создайте новый скрипт с именем CompanyInfo (как указано в конфигурации выше):
// Устанавливаем активного агента
lead.setAttr('activeAgent', 'CompanyInfo')
// Загружаем конфигурацию агента
snippet("Business.AgentsParams.MainConfig")
// Подключаем библиотеку для работы с ИИ
const LLMClient = require("Common.MetabotAI.LLMClient")
// Создаем сессию для генерации ответа
const llm = new LLMClient("UserReply", agentCFG.common.agentName)
// Передаем вопрос пользователя в обработку
llm.addUserQuery(lead.getAttr(agentCFG.common.userQueryAttibName))
// Запускаем генерацию и отправку ответа пользователю
llm.nextFlow("RAG:UserReply")
Как работает этот скрипт:
- Устанавливает режим работы с агентом CompanyInfo
- Загружает его настройки из конфигурации
- Берет вопрос пользователя и передает в ИИ
- Генерирует ответ на основе промпта с информацией о компании
- Запускает скрипт UserReply для отправки ответа пользователю
Шаг 3: Обновление системы маршрутизации
Откройте таблицу gpt_prompts, найдите промпт route_prompt для агента MainFlow и обновите секцию с инструментами:
<tools>
**RAG_Tools** - Используется, когда нужно ответить на вопросы об услугах
и продукции компании, об условиях эксплуатации продукции, об используемых
инструментах для монтажа продукции и т.д.
**INFO_Tools** - Используется когда пользователь хочет узнать о филиалах
компании, контактных данных или времени их работы
</tools>
Этап 3: Тестирование и результат
Запуск системы
После внесения всех изменений запустите бота так же, как в основном примере. Система теперь автоматически:
- Анализирует вопрос пользователя
- Определяет подходящий инструмент (RAG_Tools или INFO_Tools)
- Направляет запрос соответствующему агенту
- Получает точный ответ из подготовленной информации
Примеры работы
Вопросы для CompanyInfo агента:
- "Где находится ваш филиал в Екатеринбурге?"
- "Время работы горячей линии?"
- "Телефон кредитного отдела?"
- "Часы работы московского филиала?"
Вопросы для RAG агента:
- "Какие у вас условия по ипотеке?"
- "Как оформить депозит?"
- "Тарифы на обслуживание карт"
Преимущества такого подхода
- Скорость ответа - информация о компании доступна мгновенно
- Точность - данные всегда актуальные и не зависят от поиска в базе знаний
- Простота поддержки - легко обновить информацию в одном промпте
- Масштабируемость - можно добавить любое количество таких агентов
Ваша мультиагентная система теперь умеет не только искать информацию в документах, но и давать быстрые ответы по заранее подготовленным данным.
Документация по LLMClient
Как работает
LLMClient реализует ключевой паттерн Metabot Agent System (MAS) — фреймворк для построения мультиагентных систем через композицию простых, понятных блоков кода.
MAS следует принципу "сложное через простое":
- Декларативность: Сложные AI-операции описываются простыми, читаемыми выражениями
- Модульность: Каждый flow — независимая единица работы с собственным контекстом
- Прозрачность: Вся логика работы агента видна в коде скрипта/плагина
- Композиция: Сложные мультиагентные сценарии собираются из простых блоков
Методы класса LLMClient
new LLMClient(sessionName, agentName = "", apiFormat = "")
Создаёт новый экземпляр клиента для работы с LLM.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| sessionName | String | Уникальное имя сессии |
| agentName | String | Имя агента (опционально) |
| apiFormat | String | Формат API (опционально) |
Возвращает
LLMClient — экземпляр клиента.
setPromptTable(tableName, agentName)
Устанавливает таблицу промптов и имя агента.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| tableName | String | Имя таблицы промптов |
| agentName | String | Имя агента |
addUserQuery(content)
Сохраняет пользовательский запрос для текущей сессии.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Пользовательский запрос |
getUserQuery()
Получает последний пользовательский запрос.
Параметры
Нет
Возвращает
String — последний пользовательский запрос.
addPrompt(role, content)
Добавляет промпт с указанной ролью.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| role | String | Роль: 'system', 'user', 'assistant' |
| content | String/Array | Текст или массив строк |
addRawPrompts(prompts)
Добавляет массив промптов без обработки.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| prompts | Array | Массив объектов {role, content} |
addSystemPrompt(content)
Добавляет системный промпт.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Системный промпт |
addUserPrompt(content)
Добавляет пользовательский промпт.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Пользовательский промпт |
addAssistantPrompt(content)
Добавляет промпт ассистента.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Промпт ассистента |
addHistoryToPrompts(historyOverride = null)
Добавляет историю сообщений к промптам.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| historyOverride | Array/Null | Массив сообщений или null |
clearPrompts()
Очищает все промпты текущей сессии.
Параметры
Нет
setHistoryMaxLength(lmax)
Устанавливает максимальную длину истории сообщений.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| lmax | Number | Максимальная длина истории |
setHistory(messages)
Сохраняет историю сообщений.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| messages | Array | Массив объектов {role, content} |
getHistory()
Получает историю сообщений.
Параметры
Нет
Возвращает
Array — история сообщений.
addToHistory(message)
Добавляет сообщение в историю.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| message | Object | Объект {role, content} |
disableHistory()
Отключает сохранение истории сообщений.
Параметры
Нет
clearHistory()
Очищает историю сообщений.
Параметры
Нет
getHistoryStr()
Получает историю сообщений в виде строки.
Параметры
Нет
Возвращает
String — история сообщений.
setModel(model)
Устанавливает модель для генерации ответа.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| model | String | Название модели |
setProvider(providerName)
Устанавливает провайдера LLM.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| providerName | String | Название провайдера |
getProvider()
Получает текущего провайдера.
Параметры
Нет
Возвращает
String — название провайдера.
setApiFormat(apiFormat)
Устанавливает формат API.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| apiFormat | String | Формат API |
setModelParams(params)
Устанавливает параметры модели.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| params | Object | Объект с параметрами модели |
setTemperature(temp)
Устанавливает температуру генерации.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| temp | Number | Температура генерации |
getParams()
Получает параметры модели.
Параметры
Нет
Возвращает
Object — параметры модели.
getMessages()
Получает промпты запроса.
Параметры
Нет
Возвращает
Array — промпты запроса.
deleteMessages()
Удаляет промпты запроса.
Параметры
Нет
prepareRequest(callbackScript = null)
Сохраняет промпты и задаёт callback-скрипт.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| callbackScript | String | Код скрипта для обработки ответа (опц.) |
sendRequest()
Отправляет асинхронный запрос к LLM.
Параметры
Нет
Пример
const llm = new LLMClient("DetectIntent")
llm.setModel("gpt-3.5-turbo")
llm.setProvider("OpenAI")
llm.setPromptTable("gpt_prompts", "MyAgent")
llm.addSystemPrompt("$start")
llm.addUserPrompt(`Запрос пользователя: ${lead.getAttr("user_input")}`)
llm.prepareRequest("MyAgent:MyScript")
return llm.sendRequest()
handleResponse()
Обрабатывает ответ от LLM, сохраняет результат и историю.
Параметры
Нет
setErrorScript(scriptCode)
Назначает fallback-скрипт при ошибке.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| scriptCode | String | Код скрипта для обработки ошибки |
getErrorScript()
Получает fallback-скрипт.
Параметры
Нет
Возвращает
String — код fallback-скрипта.
setFallbackConfig(scriptCode, timeout)
Настраивает резервный сценарий и таймаут.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| scriptCode | String | Код резервного скрипта |
| timeout | Number | Таймаут в секундах |
scheduleFallback()
Запланировать отложенный запуск fallback-скрипта.
Параметры
Нет
unscheduleFallback()
Удалить отложенный запуск fallback-скрипта.
Параметры
Нет
getResponseResult()
Получает результат запроса (объект ответа провайдера).
Параметры
Нет
Возвращает
Object — объект ответа провайдера.
getProviderResult()
Получает "сырые" данные от провайдера.
Параметры
Нет
Возвращает
Object — исходные данные от провайдера.
getResponseText()
Извлекает текст ответа из результата.
Параметры
Нет
Возвращает
String — текст ответа.
extractAnswerForModel(content)
Извлекает ответ по формату модели.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | Object | Объект ответа провайдера |
getModelContextSize(modelName = null)
Получает максимальный размер контекста модели.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| modelName | String | Название модели или null |
Возвращает
Number — максимальный размер контекста.
getLastJSON(text = null)
Извлекает JSON из текста ответа.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| text | String | Текст ответа или null |
Возвращает
Object — найденный JSON.
extractTextWithoutJSON(text = null)
Удаляет JSON из текста и возвращает чистый текст.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| text | String | Текст ответа или null |
Возвращает
String — текст без JSON.
removeMarkdownHeaders(text = null)
Удаляет заголовки Markdown из текста.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| text | String | Текст ответа или null |
Возвращает
String — текст без заголовков.
getAgentAnswer(agentName)
Получает ответ агента по имени.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| agentName | String | Имя агента |
Возвращает
String — ответ агента.
getLastTokenUsage()
Получает статистику токенов последнего запроса.
Параметры
Нет
Возвращает
Object — статистика токенов.
setStatus(status)
Устанавливает статус сессии.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| status | String | Статус: 'IDLE', 'PREPARED', ... |
getStatus()
Получает текущий статус.
Параметры
Нет
Возвращает
String — текущий статус.
clearStatus()
Очищает статус.
Параметры
Нет
nextFlow(scriptCode)
Переходит к следующему flow-скрипту.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| scriptCode | String | Код следующего flow-скрипта |
sendResponse()
Отправляет ответ в лог админа.
Параметры
Нет
sendFormattedResponse(format = 'Markdown')
Отправляет ответ в заданном формате.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| format | String | Формат: 'Markdown', 'HTML', ... |
finishFlow()
Завершает работу сессии.
Параметры
Нет
Примеры использования
const LLMClient = require("Common.MetabotAI.LLMClient")
const llm = new LLMClient("DetectIntent")
llm.setModel("gpt-3.5-turbo")
llm.setProvider("OpenAI")
llm.setPromptTable("gpt_prompts", "MyAgent")
llm.addSystemPrompt("$start")
llm.addUserPrompt(`Запрос пользователя: ${lead.getAttr("user_input")}`)
llm.prepareRequest("MyAgent:MyScript")
llm.setErrorScript("MyAgent:ErrorFlow")
return llm.sendRequest()
Жизненный цикл и статусы
| Статус | Когда устанавливается | Описание |
|---|---|---|
IDLE |
new LLMClient(...) |
Клиент создан, ничего не сделано. |
PREPARED |
prepareRequest() |
Промпты собраны, запрос готов. |
WAITING |
sendRequest() |
Запрос отправлен, ожидаем ответ. |
SUCCESS |
handleResponse() (200) |
Ответ успешно получен. |
ERROR |
handleResponse() (≠200) |
Ошибка при получении ответа. |
ERROR_HANDLED |
handleResponse() → fallback |
Сработал обработчик ошибки. |
DONE |
вручную | Не используется напрямую. |
Отладка и переменные
| Переменная | Пример значения | Описание |
|---|---|---|
llm_<session>_status |
WAITING |
Текущий статус запроса |
llm_<session>_provider |
OpenAI |
Название LLM-провайдера |
llm_<session>_params |
{ model: "gpt-3.5-turbo", temperature: 0.7 } |
Параметры модели |
llm_<session>_messages |
[{"role": "system", ...}, ...] |
Все промпты запроса |
llm_<session>_history |
[{"role": "user", ...}, ...] |
История переписки |
llm_<session>_callback_script |
MyAgent:NextStep |
Скрипт для ответа |
llm_<session>_error_script |
MyAgent:Fallback |
Скрипт для ошибки |
llm_<session>_raw_response |
Вот ваш ответ... |
Текст ответа до форматирования |
llm_<session>_user_query |
Сколько лет космосу? |
Последний пользовательский запрос |
FAQ
Вопрос: Как добавить свой промпт?
Ответ: Используйте addSystemPrompt, addUserPrompt или addAssistantPrompt. Можно ссылаться на промпты из таблицы через $name или @common_name.
Вопрос: Как обработать ошибку?
Ответ: Назначьте обработчик через setErrorScript(scriptCode) или используйте резервный сценарий через setFallbackConfig(scriptCode, timeout).
Вопрос: Как получить статистику токенов?
Ответ: Вызовите getLastTokenUsage() после получения ответа.
Вопрос: Как интегрировать с другими компонентами?
Ответ: Используйте методы перехода (nextFlow), отправки (sendResponse, sendFormattedResponse) и работы с историей.
Создание ClickHouse - SQL агента
Введение
Обычные LLM модели плохо справляются с числовыми данными - придумывают несуществующие цифры, неточно считают и не могут обрабатывать большие объемы информации. Для решения этой проблемы мы соединим возможности ИИ с профессиональными инструментами работы с данными.
В этом руководстве мы создадим специализированного агента для работы с базой данных ClickHouse, который сможет:
- Точно отвечать на вопросы с числовыми данными
- Выполнять сложные расчеты и сравнения
- Искать минимальные и максимальные значения
- Анализировать тарифы и условия
Пример использования: Банк собрал данные о конкурентах в одну таблицу и хочет, чтобы бот мог отвечать на вопросы типа "У какого банка самая низкая комиссия за перевод 25 000 долларов?"
Этап 1: Подключение к ClickHouse
Настройка подключения к базе данных
Первым шагом необходимо развернуть собственный кластер ClickHouse. После развертывания:
- Переходим в атрибуты бота
- Создаем атрибут
CLICK_HOUSE_CREDENTIALS - Заполняем данные подключения в формате JSON:
{
"host": "http://111.1111.11.101:8000",
"user": "admin",
"password": "12345",
"database": "test"
}
Тестирование соединения
Создайте новый скрипт в боте для проверки подключения:
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// 1. ПРОВЕРКА СОЕДИНЕНИЯ
const ping = ch.ping()
bot.sendMessage('PING → ' + ping.result)
// 2. ПРОСМОТР СУЩЕСТВУЮЩИХ ТАБЛИЦ
const tablesList = ch.select('SHOW TABLES')
bot.sendMessage('TABLES → ' + JSON.stringify(tablesList))
Запустите скрипт и проверьте результат. Если возникают ошибки - проверьте доступы к кластеру и правильность данных подключения.
Этап 2: Проектирование структуры таблицы
Подготовка исходных данных
Для примера используем таблицу сравнения банковских тарифов:
| Банк | Мин. сумма | Сроки | До 20k USD | 20–50k USD | 50–100k USD | Валютный контроль | Мин. руб. | Макс. руб. | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Кофейный | нет | 3–4 дня | 3% | 1,2% | 0,6% | 0,36% | 0,36% | нет | н/д | 0,15% | 750 | нет |
| Жёлтый | нет | 1–3 дня | 3% | 2,5% | 2,5% | 2% | 2,5% | нет | курс ЦБ | 0,16% | 360 | 29000 |
| Салатовый | нет | до 5 дней | 3,5% | 3,5% | 3,5% | 2,8% | 2,5% | нет | курс ЦБ | 0,15% | 2000 | нет |
| Зелёный | нет | 3–5 дней | 3% | 3% | 2,7% | 2,3–2,5% | 2,2% | 130 USD за SWIFT до 50k | банк/ЦБ/Investing | 0,24% | 2000 | — |
| Розовый | нет | 5 дней | 3,5–4,5% | 3,3–3,9% | 3–3,5% | 2,3–2,5% | 2,2% | 70–150 USD за SWIFT до 15k | Investing/ЦБ (макс ставка) | 0,15% | 750 | нет |
| Охра | нет | 3 дня | 55000 руб. | 2,65% | 2,2% | 2,1% | 2,1% | нет | курс ЦБ | 0,1% | 700 | 20000 |
| Малиновый | 20 тыс. | 3 дня | — | 2–3% | 2–3% | 2–3% | 2–3% | нет | ЦБ/Investing | 0,12% | 500 | 60000 |
| Синий | 50 тыс. | 2–4 дня | Китай: 2,5% | Иные: 2–4% | — | — | — | нет | Investing | 0,15% | 1000 | 20000 |
| Бирюзовый | 10 тыс. | 3–4 дня | 2–4% | 2–4% | 2–4% | 2–4% | 2–4% | нет | ЦБ/profinance | 0,12% | — | 60000 |
| Оранжевый | — | 1–6 дней | 4,5% мин. 80k руб. | 4,5% мин. 80k руб. | 2,5–4% | 2,5–4% | 2,5–4% | нет | курс ЦБ | 0,15% | 1000 | 20000 |
| Бурый | 50 тыс. | 3 дня | нет | нет | 2–3,5% | 2–3,5% | 2–3,5% | нет | Investing | 0,15% | 600 | 50000 |
| Среднее | 30 тыс. | 3 дня | 3,7% | 3,1% | 3,1% | 2,7% | 2,4% | нет | нет | 0,14% | 750 | 45000 |
| Красный | — | 3 дня | 3% мин. 500 USD / 1,5–2% мин. 400 USD | то же | то же | 2,5% / 1,5–2% мин. 400 USD | 2% / 1,5–2% мин. 400 USD | нет | банк/ЦБ | 0,22% | 1000 | нет |
Генерация оптимальной структуры с помощью ИИ
Чтобы создать правильную структуру базы данных, воспользуемся специальным промптом:
- Переходим на https://console.anthropic.com
- Используем проверенный промпт:
You are an AI agent (Data Engineer) tasked with building ClickHouse database tables for a bank's calculation purposes. Your goal is to analyze JSON data and create an optimal table structure that allows for easy querying in ClickHouse.
Here are some important guidelines:
- Always split percentages into minimum and maximum values.
- Never store percentages as STRING or in quotes like "0.3-0.5".
- Use appropriate data types: FLOAT for percentages and decimals, INT for whole numbers.
- Design the structure carefully, thinking like a database engineer.
Analyze the following JSON data:
<json_data>
{{JSON_DATA}}
</json_data>
Your task is to:
1. Carefully examine the JSON structure and its contents.
2. Design an appropriate database structure that will allow for efficient querying in ClickHouse. Consider:
- What fields should be created?
- What data types should be used for each field?
- How to handle nested structures or arrays if present?
- How to split percentage ranges into separate minimum and maximum fields?
3. Write a SQL query to create the database table(s) based on your designed structure. Ensure that:
- All field names are clear and descriptive
- Appropriate data types are used (FLOAT for percentages and decimals, INT for whole numbers, etc.)
- The structure allows for easy and efficient querying
Remember: The goal is to create a structure that will enable straightforward and performant queries in ClickHouse. Think carefully about how the data will be used and queried in the future.
Provide your response in the following format:
<database_design>
[Explain your thought process and the rationale behind your database design here]
</database_design>
<sql_query>
[Write the SQL query to create the database table(s) here]
</sql_query>
If you need to make any assumptions or have any questions about the data structure, state them clearly in your explanation.
- В параметр JSON_DATA подставляете несколько строк из вашей таблицы
- Получаете готовый SQL для создания оптимальной структуры
Создание таблицы в ClickHouse
Создайте скрипт с полученным SQL-запросом:
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// 1. ПРОВЕРКА СОЕДИНЕНИЯ
const ping = ch.ping()
bot.sendMessage('PING → ' + ping.result)
// 2. УДАЛЕНИЕ СТАРОЙ ТАБЛИЦЫ (если существует)
const dropResult = ch.query(`DROP TABLE IF EXISTS bank_commissions`)
bot.sendMessage('DROP → DONE')
// 3. СОЗДАНИЕ НОВОЙ ТАБЛИЦЫ (Сюда подставляем SQL из прошлого шага)
const createResult = ch.createTable(`
CREATE TABLE bank_commissions
(
bank_name String,
min_payment Nullable(Int32),
delivery_days_min UInt8,
delivery_days_max UInt8,
commission_under_20k_min Float32,
commission_under_20k_max Float32,
commission_20k_50k_min Float32,
commission_20k_50k_max Float32,
commission_50k_100k_min Float32,
commission_50k_100k_max Float32,
currency_control_min Float32,
currency_control_max Float32,
min_rub Nullable(Int32),
max_rub Nullable(Int32)
)
ENGINE = MergeTree
ORDER BY bank_name`)
bot.sendMessage('CREATE → DONE')
Этап 3: Загрузка данных
Подготовка данных в JSON формате
Преобразуйте табличные данные в структурированный JSON с полями соответствующими полученной таблице:
[{
"bank_name": "Кофейный",
"min_payment": null,
"delivery_days_min": 3,
"delivery_days_max": 4,
"commission_under_20k_min": 3.0,
"commission_under_20k_max": 3.0,
"commission_20k_50k_min": 1.2,
"commission_20k_50k_max": 1.2,
"commission_50k_100k_min": 0.6,
"commission_50k_100k_max": 0.6,
"currency_control_min": 0.15,
"currency_control_max": 0.15,
"min_rub": 750,
"max_rub": null
}, {
"bank_name": "Жёлтый",
"min_payment": null,
"delivery_days_min": 1,
"delivery_days_max": 3,
"commission_under_20k_min": 3.0,
"commission_under_20k_max": 3.0,
"commission_20k_50k_min": 2.5,
"commission_20k_50k_max": 2.5,
"commission_50k_100k_min": 2.5,
"commission_50k_100k_max": 2.5,
"currency_control_min": 0.16,
"currency_control_max": 0.16,
"min_rub": 360,
"max_rub": 29000
}]
Загрузка через Метабот
Создайте скрипт для загрузки данных:
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// 1. ПРОВЕРКА СОЕДИНЕНИЯ
const ping = ch.ping()
bot.sendMessage('PING → ' + ping.result)
// 2. ОЧИСТКА СТАРЫХ ДАННЫХ
const truncateResult = ch.query('TRUNCATE TABLE bank_commissions')
bot.sendMessage('TRUNCATE → DONE')
// 3. ПОДГОТОВКА ДАННЫХ
const banksData = [
// Вставьте здесь ваш JSON массив с данными банков
]
// 4. ЗАГРУЗКА В БАЗУ
const insertResult = ch.insert('bank_commissions', banksData)
bot.sendMessage('INSERT → DONE')
Этап 4: Интеграция SQL-агента в систему
Теперь создадим специализированного агента, который будет генерировать SQL-запросы и возвращать точные ответы на основе данных из ClickHouse.
Шаг 1: Обновление конфигурации
Откройте плагин AgentsParams.MainConfig и дополните конфигурацию:
А) Добавить новый инструмент в маршрутизатор
detectRoute: {
// ... остальные параметры остаются без изменений
routerTools: [{
tools: "RAG_Tools",
route: "RAG:DetectIntent_and_FindChunks"
}, {
tools: "INFO_Tools",
route: "CompanyInfo"
}, {
tools: "TABLE1_Tools", // Новый инструмент для работы с данными
route: "ClickHouse:GenerateSQL"
}]
// ... остальные параметры остаются без изменений
}
Б) Создать конфигурацию для ClickHouse агента
else if (activeAgent === "ClickHouse") { // Агент для работы с SQL таблицами ClickHouse
agentCFG = {
common: {
title: "ClickHouse Query Agent",
agentName: "ClickHouse",
promptTable: "gpt_prompts",
userQueryAttibName: "user_query",
historyMaxLength: 2,
exitScript: "MainFlow:FollowUp"
},
generateSQL: {
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
prompt: "$clickhouse_sql_prompt",
errorScript: "RAG:ErrorFallback",
exitScript: "RAG:UserReply",
useHistory: 1,
addUserQuery: 1,
sendBotAnwser: 1
},
userReply: {
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
errorScript: "RAG:ErrorFallback",
useHistory: 1,
addUserQuery: 1,
sendBotAnwser: 1,
systemPrompts: {
start: [
["$clickhouse_result_prompt"]
],
final: []
},
}
}
}
Шаг 2: Создание скрипта агента
Создайте новый скрипт с именем ClickHouse:GenerateSQL:
Код создавайте в блоке "Выполнить асинхронный API-запрос"
const LLMClient = require("Common.MetabotAI.LLMClient")
// Установка активного агента ClickHouse
lead.setAttr('activeAgent', 'ClickHouse')
snippet("Business.AgentsParams.MainConfig")
const llm = new LLMClient("UserReply", agentCFG.common.agentName)
// Настройка истории диалога
if (!agentCFG.generateSQL.useHistory) {
llm.disableHistory()
}
if (isFirstImmediateCall) {
// Настройка LLM клиента
llm.setProvider(agentCFG.generateSQL.provider)
llm.setModel(agentCFG.generateSQL.model)
llm.setModelParams(agentCFG.generateSQL.modelParams)
llm.addSystemPrompt(agentCFG.generateSQL.prompt)
llm.addUserQuery(lead.getAttr(agentCFG.common.userQueryAttibName))
llm.prepareRequest()
return llm.sendRequest()
}
// Обработка ответа LLM
llm.handleResponse()
// Извлечение SQL-запроса из ответа
let sqlQuery = extractContentBetweenTags("sql_query")
// Проверка корректности SQL
if (!sqlQuery) {
return llm.nextFlow(agentCFG.generateSQL.errorScript)
}
// Подключение к ClickHouse
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// Выполнение SQL-запроса
const queryResult = ch.query(sqlQuery)
// Добавление результата в историю
llm.addToHistory({
role: "assistant",
content: JSON.stringify(queryResult)
})
// Переход к формированию ответа пользователю
return llm.nextFlow(agentCFG.generateSQL.exitScript)
// Функция извлечения контента между тегами
function extractContentBetweenTags(tagName, text = null) {
text = text || llm.getResponseText()
const openTag = `<${tagName}>`
const closeTag = `</${tagName}>`
const startIndex = text.indexOf(openTag)
if (startIndex === -1) return null
const endIndex = text.indexOf(closeTag, startIndex + openTag.length)
if (endIndex === -1) return null
return text.substring(startIndex + openTag.length, endIndex).trim()
}
Шаг 3: Создание промптов
1. Откройте таблицу gpt_prompts, cоздайте промпт clickhouse_sql_prompt для агента ClickHouse:
You are a Data Engineer who communicates exclusively through SQL queries. Your task is to interpret requests from a senior agent and formulate appropriate SQL queries for a ClickHouse database. Here's how you should proceed:
First, familiarize yourself with the structure of the ClickHouse table:
<table_structure>
{{@click_house_tables}}
</table_structure>
When you receive a query from the senior agent, it will be in simple language. Your job is to interpret this query and create an SQL statement that will retrieve the requested information from the ClickHouse database.
The user's query will be provided in the following format:
<user_query>
{{$user_query}}
</user_query>
Based on this query and your knowledge of the table structure, formulate an SQL query that will retrieve the requested information. Your query should be as detailed as possible, providing comprehensive data for the senior agent to analyze and make decisions.
Remember:
1. You should only output SQL code. Do not provide any explanations, comments, or additional text.
2. Strive to create complex queries when necessary to calculate the required data.
3. Always aim to provide detailed data in your query results.
4. Do not use any functions or features that are not standard SQL or specific to ClickHouse.
Your response should consist solely of the SQL query, enclosed in <sql_query> tags. For example:
<sql_query>
SELECT column1, column2, COUNT(*) as count
FROM table_name
WHERE condition
GROUP BY column1, column2
ORDER BY count DESC
LIMIT 10
</sql_query>
Do not include any text before or after the SQL query. Your entire response should be contained within the <sql_query> tags.
2. Создайте промпт clickhouse_result_prompt для агента ClickHouse:
Вы являетесь Помощником банка. Ваша задача - проанализировать историю диалога, получить из неё запрос пользователя, проанализировать ответ SQL агента и дать понятный ответ, соответствующий запросу пользователя. Отвечайте четко и по существу, представляя числовые данные в удобном для восприятия формате.
3. Создайте атрибут бота click_house_tables с описанием структуры таблицы:
TABLE: bank_commissions
COLUMNS:
- bank_name (String): Название банка
- min_payment (Nullable Int32): Минимальная сумма платежа в рублях
- delivery_days_min (UInt8): Минимальное время доставки в днях
- delivery_days_max (UInt8): Максимальное время доставки в днях
- commission_under_20k_min (Float32): Минимальная комиссия до 20k USD в процентах
- commission_under_20k_max (Float32): Максимальная комиссия до 20k USD в процентах
- commission_20k_50k_min (Float32): Минимальная комиссия 20-50k USD в процентах
- commission_20k_50k_max (Float32): Максимальная комиссия 20-50k USD в процентах
- commission_50k_100k_min (Float32): Минимальная комиссия 50-100k USD в процентах
- commission_50k_100k_max (Float32): Максимальная комиссия 50-100k USD в процентах
- currency_control_min (Float32): Минимальная комиссия валютного контроля в процентах
- currency_control_max (Float32): Максимальная комиссия валютного контроля в процентах
- min_rub (Nullable Int32): Минимальная сумма в рублях
- max_rub (Nullable Int32): Максимальная сумма в рублях
Шаг 4: Обновление маршрутизации
Откройте таблицу gpt_prompts, найдите промпт route_prompt для агента MainFlow и обновите секцию с инструментами:
<tools>
**RAG_Tools** - Используется, когда нужно ответить на вопросы об услугах
и продукции компании, об условиях эксплуатации продукции, об используемых
инструментах для монтажа продукции и т.д.
**INFO_Tools** - Используется когда пользователь хочет узнать о филиалах
компании, контактных данных или времени их работы
**TABLE1_Tools** используется для поиска информации и ответов на вопросы о:
- Ценах и стоимости переводов
- Комиссиях за переводы и платежи
- Точных цифрах и числовых данных, хранящихся в локальной базе данных
- Сравнении различных параметров (цены, комиссии, характеристики)
- Поиске минимальных/максимальных значений (самая низкая комиссия, самая высокая цена и т.д.)
- Условиях и тарифах банков-партнеров
- Расчетах и вычислениях на основе имеющихся данных
</tools>
Этап 5: Тестирование и результат
Примеры работы системы
После настройки система сможет отвечать на сложные вопросы с числовыми данными:
Простые запросы:
- "Какая комиссия у банка Кофейный?"
- "Сколько дней занимает перевод в Желтом банке?"
Сложные аналитические запросы:
- "В каком банке дешевле всего обменять 10 000 долларов?"
- "Покажи банки с минимальной комиссией валютного контроля"
- "Какой банк предлагает самые быстрые переводы?"
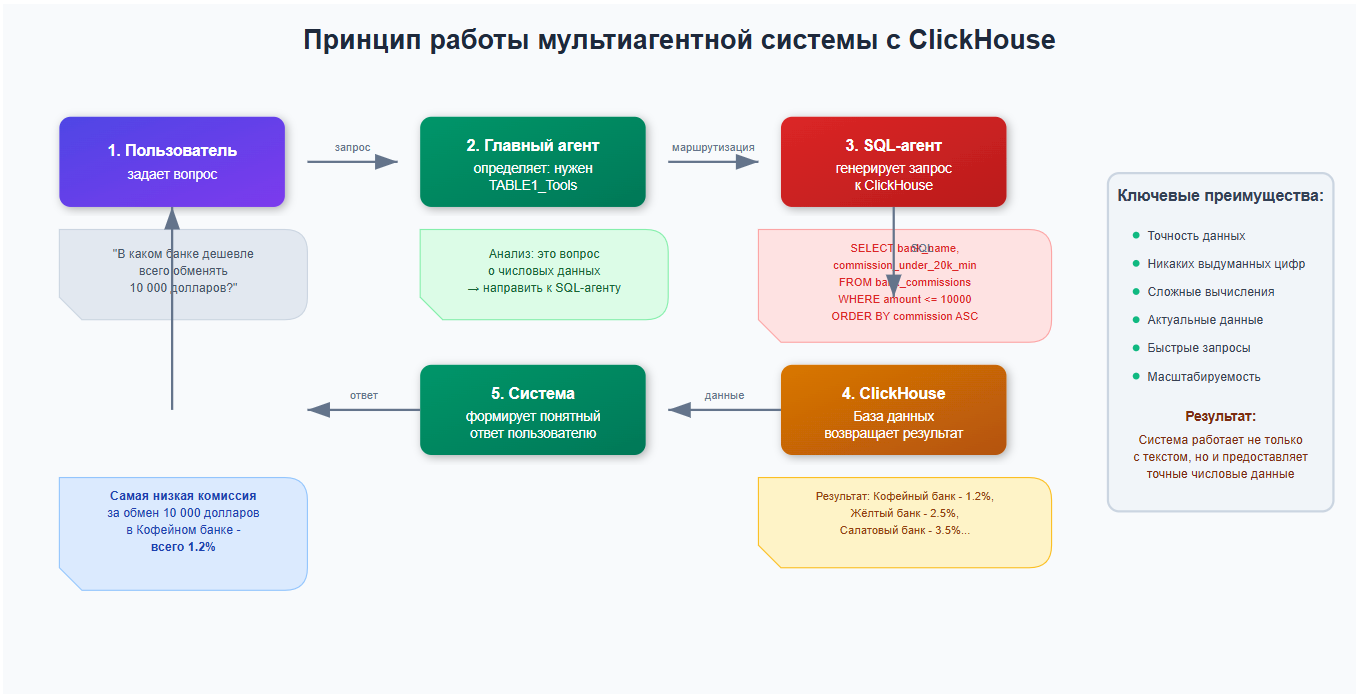
Принцип работы
- Пользователь задает вопрос о числовых данных
- Главный агент определяет - нужен TABLE1_Tools
- SQL-агент генерирует соответствующий запрос к ClickHouse
- База данных возвращает точные результаты
- Система формирует понятный ответ для пользователя
Преимущества решения
- Точность данных - никаких выдуманных цифр
- Сложные вычисления - система может выполнять расчеты любой сложности
- Масштабируемость - легко добавлять новые таблицы и данные
- Актуальность - данные всегда свежие из базы
- Производительность - ClickHouse обеспечивает быстрые запросы
Ваша мультиагентная система теперь может работать не только с текстовой информацией, но и предоставлять точные числовые данные и выполнять сложные аналитические запросы.
Руководство по работе с базой знаний (RAG)
Структура таблицы базы знаний
Представьте базу знаний как умный склад информации. Когда нужно полностью "перезагрузить" этот склад, мы поступаем просто:
-
Полная очистка базы знаний: удаляем старую таблицу и создаём точно такую же заново
- Это как снести старый склад и построить новый по тому же чертежу
- Гарантирует, что не останется "мусора" от предыдущих данных
-
Размер вектора (embedding): может изменяться в зависимости от выбранного алгоритма векторизации
- Вектор — это числовое представление смысла текста
- Разные алгоритмы создают векторы разной длины (как разные форматы фотографий)
Создание компонента базы знаний
Важно: всегда создавайте компонент для базы знаний, на который будут ссылаться агенты.
Думайте о компоненте как о "визитной карточке" вашей базы знаний:
После создания в атрибутах появится компонент с описанием базы знаний:

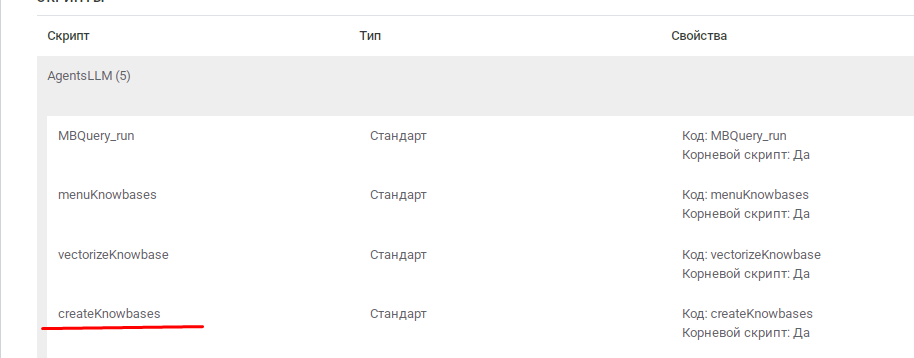
Подготовка текстового файла
Перед загрузкой файл нужно правильно "подписать" — добавить служебную информацию в начало:
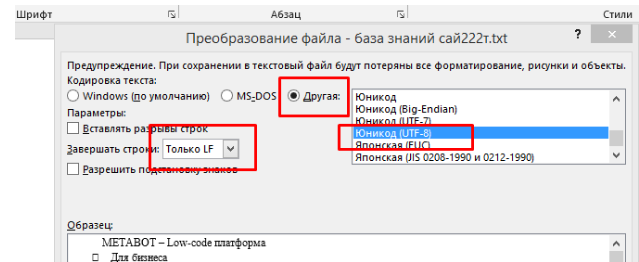
Обязательная служебная строка в начале файла:
{{Domain: METABOT33}}{{Table: gpt_knowledge_base}}{{chunk_size: 250}}{{chunk_overlap: 160}}
Эта строка работает как "инструкция по применению":
Domain— область применения (как адрес склада)Table— название таблицы (как название полки на складе)chunk_size— размер кусочка текста для обработки (250 символов)chunk_overlap— перекрытие между кусочками (160 символов для связности)

Загрузка и векторизация
Процесс состоит из двух этапов:
Этап 1: Загрузка файла
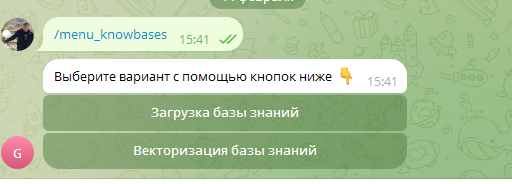
Система принимает подготовленный файл и сохраняет его содержимое.
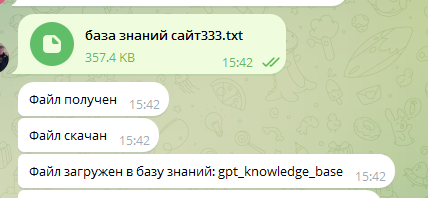
Этап 2: Векторизация
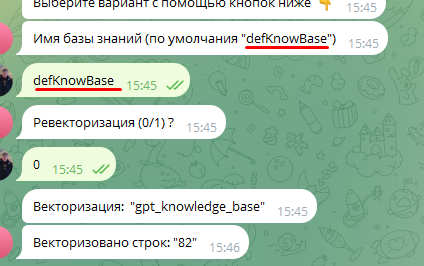
Система превращает текст в числовые векторы для быстрого поиска по смыслу.
Важно: сохраните имя defKnowBase — оно понадобится в конфигурации в параметре kbName.
Совет: процесс загрузки и векторизации похож на работу переводчика — сначала он читает текст (загрузка), потом переводит его на "язык чисел" (векторизация), чтобы компьютер мог быстро найти нужную информацию по смыслу, а не только по точным словам.
Документация по LLMTracer
Модуль LLMTracer предназначен для трассировки запросов к LLM, а также для сбора статистики по токенам, времени выполнения и ошибкам. Все данные записываются в таблицу llm_tracer.
Класс: Session
Подключается через
let LLMTracer = require("Common.AIHelpers.LLMTracer")createSession(options)
Создаёт новую сессию трассировки.
Пример:
let session = LLMTracer.createSession({
business_id: "123",
bot_id: "456",
lead_id: "789",
script_id: "script_1",
command_id: "cmd_1",
agent_name: "MyAgent",
provider: "OpenAI",
model: "gpt-4"
})Параметры:
| Имя | Тип | Описание |
|---|---|---|
| business_id | String | Идентификатор бизнеса |
| bot_id | String | Идентификатор бота |
| lead_id | String | Идентификатор лида |
| script_id | String | Идентификатор скрипта |
| command_id | String | Идентификатор команды |
| agent_name | String | Имя агента |
| provider | String | Название провайдера LLM |
| model | String | Название модели LLM |
Return
Session — Экземпляр сессии трассировки.
getCurrentSession()
Получает текущую сессию из атрибута лида.
Пример:
let session = LLMTracer.getCurrentSession()Параметры:
Нет
Return
Session | null — Текущий объект сессии или null, если не найден.
prepareRecordData(data)
Преобразует данные в безопасный формат для записи в таблицу.
Пример:
let safeData = LLMTracer.prepareRecordData({ message: "Тест", status: "ok" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| data | Object | Объект с исходными данными |
Return
Object — Объект с преобразованными значениями.
recordTrace(traceData)
Записывает трассировку в таблицу llm_tracer.
Пример:
LLMTracer.recordTrace({
agent_name: "MyAgent",
outclient_name: "ClientA",
step: "step1",
outclient_time: 120,
provider: "OpenAI",
model: "gpt-4",
type: "info",
message: "Запрос выполнен",
record: {},
params: {},
status: "ok",
input_tokens: 100,
output_tokens: 50
})Параметры:
| Имя | Тип | Описание |
|---|---|---|
| agent_name | String | Имя агента |
| outclient_name | String | Имя внешнего клиента |
| step | String | Название шага |
| outclient_time | Number | Время выполнения шага (мс) |
| provider | String | Название провайдера LLM |
| model | String | Название модели LLM |
| type | String | Тип трассировки (info, error и др.) |
| message | String | Сообщение |
| record | Object | Дополнительные данные |
| params | Object | Параметры запроса |
| status | String | Статус выполнения |
| input_tokens | Number | Количество входных токенов |
| output_tokens | Number | Количество выходных токенов |
Return
Boolean — true при успехе, false при ошибке.
recordTraceLLM(llm, timerCtrl, traceData)
Записывает трассировку по активному LLMClient.
Пример:
LLMTracer.recordTraceLLM(llmClient, "START_TIME", { message: "Старт" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| llm | Object | Экземпляр LLMClient |
| timerCtrl | String | Контроллер времени ("", "START_TIME", "END_TIME") |
| traceData | Object | Дополнительные параметры трассировки |
Return
Boolean — true при успехе, false при ошибке.
recordTraceQuery(llm, timerCtrl, traceData)
Записывает трассировку для запросов к внешним сервисам.
Пример:
LLMTracer.recordTraceQuery(llmClient, "END_TIME", { message: "Финиш" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| llm | Object | Экземпляр LLMClient |
| timerCtrl | String | Контроллер времени ("", "START_TIME", "END_TIME") |
| traceData | Object | Дополнительные параметры трассировки |
Return
Boolean — true при успехе, false при ошибке.
info(message, data)
Записывает информационную трассировку.
Пример:
LLMTracer.info("Запрос выполнен", { step: "step1" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| message | String | Текст сообщения |
| data | Object | Дополнительные данные |
Return
Boolean — true при успехе, false при ошибке.
error(message, data)
Записывает ошибку в трассировку и отправляет сообщение админу.
Пример:
LLMTracer.error("Ошибка запроса", { code: 500 })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| message | String | Текст ошибки |
| data | Object | Дополнительные данные |
Return
Boolean — true при успехе, false при ошибке.
countTokens(dateRange)
Подсчитывает количество токенов за указанный период.
Пример:
LLMTracer.countTokens({ from: "2024-06-01 00:00:00", to: "2024-06-30 23:59:59" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| from | String | Начальная дата ("YYYY-MM-DD HH:MM:SS") |
| to | String | Конечная дата |
Return
Object — { input_tokens, output_tokens, total_tokens }
getActiveSessionsCount(minutes)
Подсчитывает количество активных сессий за последние N минут.
Пример:
LLMTracer.getActiveSessionsCount(10)Параметры:
| Имя | Тип | Описание |
|---|---|---|
| minutes | Number | Глубина окна в минутах (по умолчанию 5) |
Return
Number — Количество активных сессий.
Быстрый старт
- Создайте сессию:
LLMTracer.createSession({ ... }) - Запишите шаг:
LLMTracer.recordTrace({ ... }) - Для LLM: используйте
recordTraceLLM() - Для ошибок: используйте
error() - Для статистики: используйте
countTokens()
Аналитика и нагрузки
В стандартный шаблон MA_Router входит модуль, который отвечает за контроль нагрузки, лимитов и доступности моделей LLM.
Основные проверки
- Суточный лимит диалогов:
LLMDialogCounter.canStartNewDialog(limit=25)— ограничивает количество диалогов на пользователя. - Текущая нагрузка:
LLMTracer.getActiveSessionsCount(5)— если слишком много активных сессий, диалог откладывается. - Активность ИИ:
bot.getBoolAttr("ai_is_active")— если ИИ выключен, переводит на резервный сценарий.
Логика работы
- Перед стартом диалога — проверяются лимиты и нагрузка.
- Если лимит превышен — пользователю отправляется уведомление, диалог переносится.
- Если нагрузка высокая — диалог откладывается на несколько секунд.
- При старте диалога — увеличивается счётчик, открывается сессия в LLMTracer.
- При завершении — сессия закрывается.
Метрики и отчёты
/aistatsдля получения аналитики по текущему состоянию системы- Пример отчёта:
📊 Статистика LLM Tracer
🕒 За последние 7 дней:
• Токены входящие: 2 533 129
• Токены исходящие: 313 036
• Всего токенов: 2 846 165
• Уникальных лидов: 3
• Уникальных сессий: 29
• Среднее вопросов на пользователя: 9.7
• Превышений 20 запросов в сутки: 1
📈 За всё время:
• Токены входящие: 3 861 082
• Токены исходящие: 351 484
• Всего токенов: 4 212 566
• Уникальных лидов: 3
• Уникальных сессий: 38
• Среднее вопросов на пользователя: 12.7
• Превышений 20 запросов в сутки: 1
Обновлено: 2025-10-06 18:53:52
Таймауты
Для каждого запроса к LLM настраиваются таймауты в конфигурации. При превышении времени ожидания:
- Фиксация проблемы — информация об ошибке отправляется через Notifier
- Fallback — сценарий не блокируется, автоматически запускается Fallback-скрипт
- Продолжение работы — пользователь получает альтернативный ответ без прерывания диалога
Таймауты защищают систему от зависаний при проблемах на стороне LLM-провайдера.
Быстрые ответы на вопросы
- Как узнать текущую нагрузку? — Вызвать
LLMTracer.getActiveSessionsCount(5). - Как фиксируются ошибки? — Через Notifier и запись в LLMTracer.
LLMTracer - Плагин для трассировки запросов к LLM
Описание
LLMTracer - это модуль для трассировки запросов к языковым моделям (LLM) и внешним сервисам. Он позволяет записывать данные о запросах, ответах, ошибках и использовании токенов в таблицу llm_tracer.
Установка
Импортируйте модуль в ваш код:
const LLMTracer = require('Common.Platform.LLMTracer');
Основные возможности
- Создание сессий трассировки
- Запись информационных сообщений
- Запись ошибок
- Подсчет использованных токенов за указанный период
Быстрый старт
1. Создание сессии трассировки
// Создание сессии с параметрами по умолчанию
const session = LLMTracer.createSession();
// Создание сессии с указанием параметров
const session = LLMTracer.createSession({
agent_name: "ChatGPT Assistant",
provider: "OpenAI",
model: "gpt-4"
});
Параметры:
options(Object) - Параметры сессииbusiness_id(string|number) - ID бизнесаbot_id(string|number) - ID ботаlead_id(string|number) - ID лидаscript_id(string|number) - ID скриптаcommand_id(string|number) - ID командыagent_name(string) - Имя агентаprovider(string) - Провайдер LLMmodel(string) - Модель LLM
2. Прямая запись трассировки
// Прямая запись трассировки с указанием всех параметров
LLMTracer.recordTrace({
outclient_name: "OpenAI API",
step: 1,
outclient_time_sec: 2.5,
provider: "OpenAI",
model: "gpt-4",
type: "info",
message: "Запрос выполнен",
status: "success",
input_tokens: 150,
output_tokens: 50
});
Параметры:
traceData(Object) - Данные для записи в таблицуoutclient_name(string) - Имя внешнего клиентаstep(number|string) - Шаг выполненияoutclient_time_sec(number) - Время выполнения запроса в секундахprovider(string) - Провайдер LLMmodel(string) - Модель LLMtype(string) - Тип записи (info, error)message(string) - Сообщениеrecord(string) - Дополнительные данные в формате JSONstatus(string|number) - Статус выполненияinput_tokens(number) - Количество входных токеновoutput_tokens(number) - Количество выходных токенов
3. Запись информационных сообщений
// Запись простого сообщения
LLMTracer.info("Запрос к LLM выполнен успешно");
// Запись сообщения с дополнительными данными
LLMTracer.info("Запрос к LLM выполнен успешно", {
outclient_name: "OpenAI API",
input_tokens: 150,
output_tokens: 50,
outclient_time_sec: 2.5
});
Параметры:
message(string) - Информационное сообщениеdata(Object) - Дополнительные данные для записиoutclient_name(string) - Имя внешнего клиентаstep(number|string) - Шаг выполненияoutclient_time_sec(number) - Время выполнения запроса в секундахprovider(string) - Провайдер LLMmodel(string) - Модель LLMstatus(string|number) - Статус выполненияinput_tokens(number) - Количество входных токеновoutput_tokens(number) - Количество выходных токенов
3. Запись ошибок
try {
// Ваш код...
} catch (error) {
LLMTracer.error("Ошибка при запросе к LLM", {
error_message: error.message,
outclient_name: "OpenAI API"
});
}
4. Подсчет токенов
// Подсчет токенов за все время
const allTokens = LLMTracer.countTokens();
debug(`Всего использовано токенов: ${allTokens.total_tokens}`);
// Подсчет токенов за определенный период
const tokensForPeriod = LLMTracer.countTokens({
from: "2023-01-01 00:00:00",
to: "2023-01-31 23:59:59"
});
debug(`Входящие токены: ${tokensForPeriod.input_tokens}`);
debug(`Исходящие токены: ${tokensForPeriod.output_tokens}`);
debug(`Всего токенов: ${tokensForPeriod.total_tokens}`);
Параметры:
dateRange(Object) - Объект с параметрами временного диапазонаfrom(string) - Начальная дата в формате "YYYY-MM-DD HH:MM:SS"to(string) - Конечная дата в формате "YYYY-MM-DD HH:MM:SS"
Возвращает: Объект с количеством токенов
input_tokens(number) - Количество входных токеновoutput_tokens(number) - Количество выходных токеновtotal_tokens(number) - Общее количество токенов
Структура таблицы llm_tracer
Модуль записывает данные в таблицу llm_tracer со следующими полями:
business_id- ID бизнесаlead_id- ID лидаscript_id- ID скриптаsession_id- ID сессииagent_name- Имя агентаoutclient_name- Имя внешнего клиентаstep- Шаг выполненияoutclient_time- Время выполнения запроса в секундахprovider- Провайдер LLMmodel- Модель LLMtype- Тип записи (info, error)message- Сообщениеrecord- Дополнительные данные в формате JSONstatus- Статус выполненияinput_tokens- Количество входных токеновoutput_tokens- Количество выходных токеновcreated_at- Дата и время создания записи (автоматически)
Импортировать таблицу можно по ссылке: https://stage.metabot.dev/business/export/1216/show?bots=&b_c=0&b_o=0&b_i=0&b_ls=0&b_r=0&b_s=0&b_li=0&b_t=0&b_br=0&b_aie=0&b_aee=0&b_sa=0&cts_llm_tracer=1&b_llm_tracer=1
Конфигурация
Конфигурационный плагин бизнеса (snippet Business.AgentsParams.BSPbConfig) используется для централизованного управления параметрами агентов в системе MAS. Он определяет настройки для различных сценариев работы агентов, включая маршрутизацию, выбор моделей, параметры генерации, обработку ошибок и интеграцию с внешними инструментами.
Структура файла
Файл представляет собой JavaScript-объект, где каждая ветка соответствует определённому агенту или сценарию. Основные разделы:
- common — общие параметры агента (имя, таблица промптов, максимальная длина истории, сценарий выхода и др.)
- detectRoute — параметры для маршрутизации запросов (провайдер, модель, промпт, инструменты маршрутизации, обработчик ошибок)
- detectIntent — параметры для определения намерения пользователя (провайдер, модель, промпт, обработчик ошибок, база знаний)
- userReply — параметры для формирования ответа пользователю (провайдер, модель, история, промпты, обработчик ошибок)
- execSQL — параметры для SQL-агентов (провайдер, модель, промпт, обработчик ошибок)
Пример структуры
{
common: {
title: "Основной Flow c маршрутизатором",
agentName: "bsp",
promptTable: "gpt_prompts",
userQueryAttibName: "user_query",
historyMaxLength: 4,
useRoute: 0,
exitScript: "MainFlow_FollowUp",
MBQuery_fallback: {
script_code: "MBQuery_TimeOut",
timeout: 180
}
},
detectRoute: {
provider: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
prompt: "$route_prompt",
routerTools: [ ... ],
errorScript: "RAG_ErrorFallback"
},
detectIntent: {
provider: "OpenAI",
apiFormat: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
prompt: "$rag_intent_prompt",
errorScript: "RAG_ErrorFallback",
kbName: "defKnowBase",
kbDomain: "tech_domain"
},
userReply: {
provider: "OpenAI",
apiFormat: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
errorScript: "RAG_ErrorFallback",
useHistory: 1,
addUserQuery: 1,
sendBotAnwser: 1,
systemPrompts: {
start: [["$start_prompt", "$rag_prompt"]],
final: ["$final_prompt"]
}
}
}Как работает подстановка
- Загрузка snippet: Конфигурация подгружается через snippet с именем
Business.AgentsParams.BSPbConfig. - Выбор активного агента: В коде определяется активный агент через переменную
activeAgent(например,bsp,CompanyInfo,Table1). - Инициализация agentCFG: В зависимости от значения
activeAgentвыбирается соответствующая ветка конфигурации и присваивается переменнойagentCFG. - Передача параметров: agentCFG используется для инициализации LLMClient, настройки промптов, истории, провайдера, модели и других параметров.
- Маршрутизация и обработка: Ветка
detectRouteопределяет инструменты маршрутизации, которые используются для выбора сценария обработки запроса пользователя. - Обработка ошибок: Для каждого сценария можно задать обработчик ошибок (
errorScript) и fallback-скрипты. - Интеграция с базой знаний: Ветка
detectIntentможет содержать параметры для подключения к базе знаний (kbName,kbDomain).
Структура кода
let aAgent = lead.getAttr("activeAgent")
let agentCFG
if (aAgent === "bsp") {
agentCFG = { ... } // параметры для bsp
} else if (aAgent === "CompanyInfo") {
agentCFG = { ... } // параметры для CompanyInfo
} else if (aAgent === "Table1") {
agentCFG = { ... } // параметры для Table1
} else {
bot.sendMessage(`BSPbConfig:snippet - неизвестный activeAgent: ${aAgent}`)
bot.stop()
}
Куда подставляются параметры
- LLMClient: параметры модели, провайдера, истории, промптов и сценариев подставляются при создании и настройке клиента.
- Маршрутизатор: инструменты из
routerToolsиспользуются для выбора сценария обработки. - Обработка ошибок: скрипты из
errorScriptиMBQuery_fallbackиспользуются для fallback-логики. - Промпты: значения из
systemPromptsподставляются в соответствующие методы LLMClient для формирования запроса. - База знаний: параметры
kbNameиkbDomainиспользуются для интеграции с внешними источниками знаний.
Рекомендации
- Все параметры должны быть явно определены для каждого сценария, чтобы избежать ошибок при маршрутизации и генерации ответа.
- Для расширения функционала добавляйте новые ветки конфигурации с нужными параметрами.
FAQ
Вопрос: Как добавить нового агента?
Ответ: Добавьте новую ветку в объект конфигурации с нужными параметрами и обработчиками.
Вопрос: Как изменить модель или провайдера?
Ответ: Измените значения model и provider в нужной ветке конфигурации.
Вопрос: Как задать fallback-скрипт?
Ответ: Укажите параметры в MBQuery_fallback или errorScript для нужного сценария.
Вопрос: Как интегрировать базу знаний?
Ответ: Добавьте параметры kbName и kbDomain в ветку сценария, где требуется интеграция.
Ошибки и отладка
В этом документе описаны все основные механизмы обработки ошибок, настройки таймаутов, использование нотификатора, трассировки и отладки.
1. Таймауты: где и как настраиваются
Таймауты — это максимальное время ожидания ответа от LLM или внешнего сервиса. Если таймаут превышен, происходит ошибка и запускается обработка сбоя.
Где настраиваются:
- В конфиге агента (
agentCFG): timeout: время ожидания в секундах.- Пример:
MBQuery_fallback: { script_code: "MBQuery_TimeOut", timeout: 180 } - В клиенте LLM (
LLMClient):- Таймаут может задаваться при инициализации клиента или в параметрах запроса.
- Если таймаут не указан — используется значение по умолчанию (обычно 30-60 секунд).
Как работает:
- Если таймаут превышен:
- Сценарий не блокируется — пользователь отправляется в выбранный скрипт в котором описана другая логика обработки его запроса
2. Нотификатор: что это и как работает
Notifier — это модуль для отправки уведомлений о сбоях и важных событиях админам.
- Подробная инструкция: см. Документация по Notifier
- Вызов:
Notifier.send({ message, severity, ... }) - Используется для ошибок, таймаутов, превышения лимитов.
3. LLMTracer: трассировка ошибок
LLMTracer — модуль для логирования всех событий, включая ошибки.
- Подробная инструкция: см. Документация по LLMTracer
- При ошибке записывается строка с
type=err,status=error, описанием и параметрами запроса. - Позволяет анализировать причины сбоев, видеть историю запросов и ответов.
- Для отладки используйте подробные сообщения и сохраняйте контекст.
4. Режим debug и самостоятельная отладка
Если не удаётся найти причину ошибки:
- Включите режим debug:
- Перейдите в настройки бота и включите режим отладки.
- Перейдите в настройки лида и включите нужный режим отладки.
- В точках падения используйте команды логирования:
bot.debug('Debug:' + JSON.stringify(data))
- Пройдите путь пользователя вручную:
- Повторите шаги, которые приводят к ошибке.
- Проверьте параметры запроса, ответы модели, логи LLMTracer.
- Используйте тестовые данные и сценарии.
Eval - Тестирование
Схема работы системы Eval
Полная схема флоу с блокировками и таблицами
graph TB
Start([Пользователь запускает тест]) --> StartRun[Eval_StartRun]
StartRun --> CheckRun{Проверка run_status}
CheckRun -->|pending| CreateReport[Создать report в eval_reports]
CheckRun -->|!pending| Error1[Ошибка: run уже запущен]
CreateReport --> UpdateRun[Обновить eval_runs:<br/>status=running, started_at]
UpdateRun --> InitLeads[Запустить Eval_InitLead<br/>для каждого run_lead_id]
InitLeads --> SetBatchTest[Установить batchTest=1]
SetBatchTest --> SaveContext[Сохранить eval_context:<br/>run_id, suite_id, report_id]
SaveContext --> ProcessQuestion[Eval_ProcessQuestion]
ProcessQuestion --> CheckContext{Есть текущая серия<br/>в контексте?}
CheckContext -->|Да| GetNextQuestion[Взять следующий вопрос<br/>из серии]
CheckContext -->|Нет| GetUnclaimed[getUnclaimedSeries<br/>report_id, suite_id]
GetUnclaimed --> CheckTable1[Проверить eval_answers:<br/>найти свободные серии/вопросы]
CheckTable1 --> AvailableList{Есть доступные<br/>элементы?}
AvailableList -->|Нет| AggregateReport[Eval_AggregateReport]
AvailableList -->|Да| TryLock[Попытка захвата блокировки]
TryLock --> LockType{Тип элемента?}
LockType -->|Серия| LockSeries["eval_series_runId_seriesIndex<br/>TTL=60s"]
LockType -->|Standalone| LockQuestion["eval_q_runId_questionId<br/>TTL=5s"]
LockSeries --> CheckLock{Блокировка<br/>получена?}
LockQuestion --> CheckLock
CheckLock -->|Нет| ReleaseNotNeeded[continue<br/>блокировка не была получена]
CheckLock -->|Да| DoubleCheck[Двойная проверка:<br/>проверить eval_answers]
ReleaseNotNeeded --> TryLock
DoubleCheck --> AlreadyClaimed{Элемент уже<br/>занят?}
AlreadyClaimed -->|Да| ReleaseLock[bot.releaseLockForBot<br/>освободить блокировку]
AlreadyClaimed -->|Нет| CreateAnswers[Создать записи в eval_answers<br/>status=PROCESSING<br/>для всех вопросов серии]
ReleaseLock --> TryLock
CreateAnswers --> SaveSeriesContext[Сохранить серию в контекст:<br/>current_series, answerIds]
GetNextQuestion --> CheckFirst{Первый вопрос<br/>серии?}
SaveSeriesContext --> CheckFirst
CheckFirst -->|Да| ClearHistory[Очистить историю mainAgent]
CheckFirst -->|Нет| SetQuery[Установить user_query]
ClearHistory --> SetQuery
SetQuery --> MARouter[MA_Router<br/>обработка вопроса ботом]
MARouter --> CheckBatchTest{batchTest==1?}
CheckBatchTest -->|Нет| NormalFlow[Обычный flow]
CheckBatchTest -->|Да| SaveAnswer[Eval_SaveAnswer]
SaveAnswer --> GetSession[Получить session_id<br/>из LLMTracer]
GetSession --> SaveActual[Сохранить actual_answer<br/>в eval_answers]
SaveActual --> GetMetrics[getTraceMetrics<br/>из llm_tracer]
GetMetrics --> SaveMetrics[Сохранить метрики:<br/>latency_ms, tokens, etc.]
SaveMetrics --> LockCounter["eval_run_runId_counter<br/>TTL=10s, wait=30s"]
LockCounter --> IncrementCounter[incrementProcessedQuestions<br/>в eval_reports]
IncrementCounter --> JudgeAnswer[Eval_JudgeAnswer]
JudgeAnswer --> CallJudge[Вызов LLM-ассессора]
CallJudge --> ParseJSON{Успешно<br/>распарсить JSON?}
ParseJSON -->|Да| SaveRatings[Сохранить ratings:<br/>overall, accuracy, etc.<br/>status=COMPLETED]
ParseJSON -->|Нет| SaveDefault[Сохранить дефолтные<br/>ratings=50<br/>status=COMPLETED]
SaveRatings --> UpdateSeriesIdx[Увеличить current_series_question_idx]
SaveDefault --> UpdateSeriesIdx
UpdateSeriesIdx --> ProcessQuestion
MARouter -->|Ошибка| ErrorFallback[RAG_ErrorFallback]
ErrorFallback --> CheckBatchTest2{batchTest==1?}
CheckBatchTest2 -->|Да| HandleError[Eval_HandleError]
CheckBatchTest2 -->|Нет| NormalError[Обычная обработка ошибки]
HandleError --> MarkFailed[markAnswerFailed<br/>status=FAILED<br/>в eval_answers]
MarkFailed --> IncrementFailed[incrementFailedQuestions<br/>в eval_reports]
IncrementFailed --> ProcessQuestion
AggregateReport --> CheckAllProcessed[areAllQuestionsProcessed<br/>report_id, suite_id]
CheckAllProcessed --> CheckStatuses[Проверить статусы через table.find:<br/>PENDING, PROCESSING<br/>используя IN условие]
CheckStatuses --> CheckSeries[Проверить целостность серий:<br/>все вопросы в финальных статусах<br/>COMPLETED или FAILED]
CheckSeries --> AllDone{Все обработано?}
AllDone -->|Нет| SendStatusMsg[Отправить статус главному лиду:<br/>обработка продолжается]
AllDone -->|Да| FinalizeLock["eval_run_runId_finalize<br/>TTL=60s"]
SendStatusMsg --> ExitFlow
FinalizeLock --> LockAcquired{Блокировка<br/>получена?}
LockAcquired -->|Нет| OtherLeadFinalizes[Другой лид финализирует<br/>и отправит уведомление]
LockAcquired -->|Да| FinalizeReport[finalizeReport:<br/>calculateReportStats<br/>status=COMPLETED]
OtherLeadFinalizes --> ExitFlow
FinalizeReport --> FinalizeRun[finalizeRun:<br/>status=COMPLETED<br/>finished_at]
FinalizeRun --> SendNotify[Eval_Notify<br/>отправить уведомление]
SendNotify --> UpdateNotify[Обновить notification_sent=1]
UpdateNotify --> ExitFlow
Note1[Блокировка финализации гарантирует<br/>единственность отправки уведомления]
ExitFlow --> End([Завершение])
style Start fill:#e1f5ff
style End fill:#e1f5ff
style Error1 fill:#ffcccc
style HandleError fill:#ffcccc
style MarkFailed fill:#ffcccc
style LockSeries fill:#fff4cc
style LockQuestion fill:#fff4cc
style LockCounter fill:#fff4cc
style FinalizeLock fill:#fff4cc
style NotifyLock fill:#fff4cc
style CreateReport fill:#ccffcc
style CreateAnswers fill:#ccffcc
style SaveRatings fill:#ccffcc
style FinalizeReport fill:#ccffcc
Схема таблиц и их связи
erDiagram
eval_runs ||--o{ eval_reports : "has"
eval_suites ||--o{ eval_questions : "contains"
eval_suites ||--o{ eval_runs : "used_in"
eval_reports ||--o{ eval_answers : "contains"
eval_questions ||--o{ eval_answers : "answered_by"
eval_runs {
int id PK
int suite_id FK
text run_lead_ids "lead1,lead2,lead3"
text run_status "pending|running|completed|failed"
datetime started_at
datetime finished_at
}
eval_suites {
int id PK
text name
int bot_id
}
eval_questions {
int id PK
int suite_id FK
text question_text
text optimal_answer
int series_index "null для standalone"
int order_in_series "1,2,3..."
}
eval_reports {
int id PK
int run_id FK
datetime started_at
datetime finished_at
int total_questions
int processed_questions
int failed_questions
decimal average_rating
text report_status "running|completed|failed"
int notification_sent
}
eval_answers {
int id PK
int report_id FK
int question_id FK
text lead_id
text session_id
text question_text
text optimal_answer
text actual_answer
text answer_status "pending|processing|completed|failed"
decimal rating_overall
decimal rating_accuracy
int latency_ms
int input_tokens
int output_tokens
text error_message
}
llm_tracer {
text session_id PK
decimal outclient_time
int input_tokens
int output_tokens
}
Схема блокировок и их жизненный цикл
sequenceDiagram
participant L1 as Lead 1
participant L2 as Lead 2
participant DB as eval_answers
participant Lock as Lock System
Note over L1,L2: Параллельная обработка вопросов
L1->>DB: getUnclaimedSeries(report_id, suite_id)
DB-->>L1: [Серия 1, Серия 2, Вопрос 3]
L2->>DB: getUnclaimedSeries(report_id, suite_id)
DB-->>L2: [Серия 1, Серия 2, Вопрос 3]
L1->>Lock: waitForBotLock("eval_series_{runId}_1")
Lock-->>L1: true (получена)
L2->>Lock: waitForBotLock("eval_series_{runId}_1")
Lock-->>L2: false (занята L1)
L1->>DB: Двойная проверка: серия свободна?
DB-->>L1: Да, свободна
L1->>DB: Создать записи status=PROCESSING
DB-->>L1: answerIds: [101, 102, 103]
L2->>Lock: waitForBotLock("eval_series_{runId}_2")
Lock-->>L2: true (получена)
L2->>DB: Двойная проверка: серия свободна?
DB-->>L2: Да, свободна
L2->>DB: Создать записи status=PROCESSING
DB-->>L2: answerIds: [104, 105]
Note over L1: Обработка вопросов серии 1
L1->>DB: Обновить answer_id=101: actual_answer, status=COMPLETED
Note over L2: Обработка вопросов серии 2
L2->>DB: Обновить answer_id=104: actual_answer, status=COMPLETED
Note over L1,L2: Блокировки автоматически освобождаются по TTL
Note over L1,L2: или при ошибке через releaseLockForBot()
Схема обработки ошибок
flowchart TD
Start[Обработка вопроса] --> Process[MA_Router обрабатывает]
Process --> Success{Успешно?}
Process --> Timeout{Таймаут?}
Process --> Error{Ошибка API?}
Success -->|Да| SaveAnswer[Eval_SaveAnswer]
SaveAnswer --> Judge[Eval_JudgeAnswer]
Judge --> JudgeSuccess{Ассессор<br/>ответил?}
JudgeSuccess -->|Да| SaveRatings[Сохранить ratings<br/>status=COMPLETED]
JudgeSuccess -->|Нет| SaveDefault[Сохранить дефолт<br/>status=COMPLETED]
SaveRatings --> NextQuestion[Следующий вопрос]
SaveDefault --> NextQuestion
Timeout -->|Да| ErrorFallback[RAG_ErrorFallback]
Error -->|Да| ErrorFallback
ErrorFallback --> CheckBatch{batchTest==1?}
CheckBatch -->|Нет| UserError[Показать ошибку<br/>пользователю]
CheckBatch -->|Да| HandleError[Eval_HandleError]
HandleError --> MarkFailed[markAnswerFailed<br/>status=FAILED<br/>error_message]
MarkFailed --> IncrementFailed[incrementFailedQuestions]
IncrementFailed --> NextQuestion
NextQuestion --> CheckMore{Есть ещё<br/>вопросы?}
CheckMore -->|Да| Process
CheckMore -->|Нет| Aggregate[Eval_AggregateReport]
Aggregate --> CheckAll{Все вопросы<br/>обработаны?}
CheckAll -->|Нет| Wait[Ждать завершения<br/>других лидов]
CheckAll -->|Да| Finalize[Финализация report]
style Error fill:#ffcccc
style Timeout fill:#ffcccc
style HandleError fill:#ffcccc
style MarkFailed fill:#ffcccc
style Success fill:#ccffcc
style SaveRatings fill:#ccffcc
style Finalize fill:#ccffcc
Схема статусов вопросов
stateDiagram-v2
[*] --> PENDING: Создан в claimSeries
PENDING --> PROCESSING: Захвачен лидом
PROCESSING --> COMPLETED: Успешно обработан<br/>и оценён
PROCESSING --> FAILED: Ошибка при обработке
COMPLETED --> [*]
FAILED --> [*]
note right of PROCESSING
Блокировка активна
TTL: 5s (вопрос) или 60s (серия)
end note
note right of COMPLETED
Финальный статус
Включает ratings и метрики
end note
Схема параллельной обработки (Run Leads Pool)
graph LR
subgraph "Run Leads Pool"
L1[Lead 1]
L2[Lead 2]
L3[Lead 3]
end
subgraph "Общий Report"
R[(eval_reports<br/>report_id=1)]
end
subgraph "Вопросы Suite"
Q1[Серия 1: Q1, Q2, Q3]
Q2[Серия 2: Q4, Q5]
Q3[Вопрос 6]
Q4[Вопрос 7]
end
subgraph "Блокировки (run_id=5)"
B1[eval_series_5_1]
B2[eval_series_5_2]
B3[eval_q_5_6]
B4[eval_q_5_7]
end
L1 -->|claimSeries| B1
L2 -->|claimSeries| B2
L3 -->|claimSeries| B3
B1 --> Q1
B2 --> Q2
B3 --> Q3
Q1 --> R
Q2 --> R
Q3 --> R
L1 -.->|Параллельно| L2
L2 -.->|Параллельно| L3
style R fill:#ccffcc
style B1 fill:#fff4cc
style B2 fill:#fff4cc
style B3 fill:#fff4cc
style B4 fill:#fff4cc
Ключевые моменты
Блокировки
- Все блокировки привязаны к
run_idдля изоляции параллельных запусков - Формат:
{prefix}_{runId}_{identifier} - TTL: 5s для вопросов, 60s для серий, 60s для финализации
- Освобождаются автоматически по TTL или через
bot.releaseLockForBot()
Таблицы
-
eval_runs- запуски тестов -
eval_reports- отчёты (один на run) -
eval_answers- ответы на вопросы (много на report) -
eval_questions- вопросы из suite -
llm_tracer- метрики производительности
Обработка ошибок
- Ошибки обрабатываются через
Eval_HandleError - Вопрос помечается как
FAILEDсerror_message - Тест продолжается со следующим вопросом
- Не влияет на другие лиды в пуле
- FAILED вопросы можно переобработать (не считаются занятыми)
Оптимизация запросов
- Используется
table.findс условиемINдля проверки статусов - Заменены
filter/mapна прямые запросы к БД где возможно - Проверка активных статусов:
["answer_status", "IN", ["pending", "processing", "completed"]] - Проверка финальных статусов:
["answer_status", "IN", ["completed", "failed"]]
Серии vs Standalone
- Серии захватываются целиком (все вопросы сразу)
- Standalone вопросы захватываются по одному
- История очищается перед началом новой серии
- Целостность серий проверяется при финализации