LLM Query — AI-запросы к LLM внутри сценариев
Пакет: AI
Полное имя компонента: Common.AI.LLMQuery
Что это
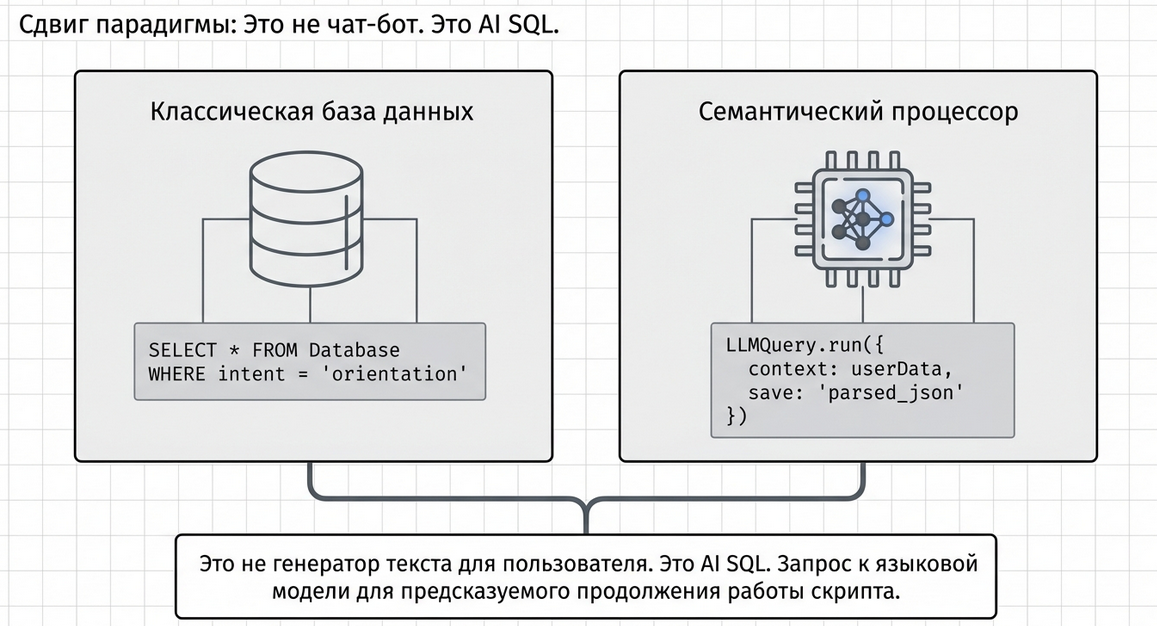
LLM Query — это высокоуровневый AI-компонент Metabot для выполнения запросов к языковым моделям прямо внутри сценария.
Он позволяет встроить запрос к искусственному интеллекту в сценарий так, чтобы для сценариста это выглядело как обычный шаг логики, а не как отдельная внешняя интеграция.
Проще всего воспринимать его так:
LLM Query — это AI Query-компонент.
Почти как SQL-запрос, только не к базе данных, а к языковой модели.
Ты:
-
собираешь контекст,
-
формулируешь задачу,
-
задаёшь формат ответа,
-
получаешь результат,
-
работаешь с ним дальше в сценарии как с обычными данными Metabot.
Зачем нужен LLM Query

Обычный сценарий хорошо работает, пока пользователь отвечает так, как ожидает логика кнопок, меню и веток.
Но в жизни пользователь пишет свободно.
Например, сценарий ожидает:
Выберите тип проблемы
А пользователь пишет:
Соседи сверху топают, слышу шаги и телевизор через потолок
Для дерева условий это неудобный вход.
Для LLM Query — нормальная задача на семантический анализ.
Компонент нужен, когда необходимо:
-
понять свободный текст;
-
извлечь параметры из сообщения;
-
классифицировать намерение;
-
сгенерировать ответ в заданной рамке;
-
вернуть не просто текст, а структурированный JSON;
-
встроить AI в существующий сценарий без разрушения его логики.
Где используется
LLM Query подходит для:
-
анализа входящих сообщений;
-
определения intent;
-
сегментации и профилирования;
-
интерпретации ответов квиза;
-
извлечения JSON-структуры из текста;
-
генерации отражений, summaries и рекомендаций;
-
работы после Voice Input;
-
RAG-сценариев после поиска по базе знаний.
Где находится компонент
Компонент находится в пакете AI и подключается как обычный плагин Metabot:
const LLMQuery = require("Common.AI.LLMQuery")Как работает LLM Query
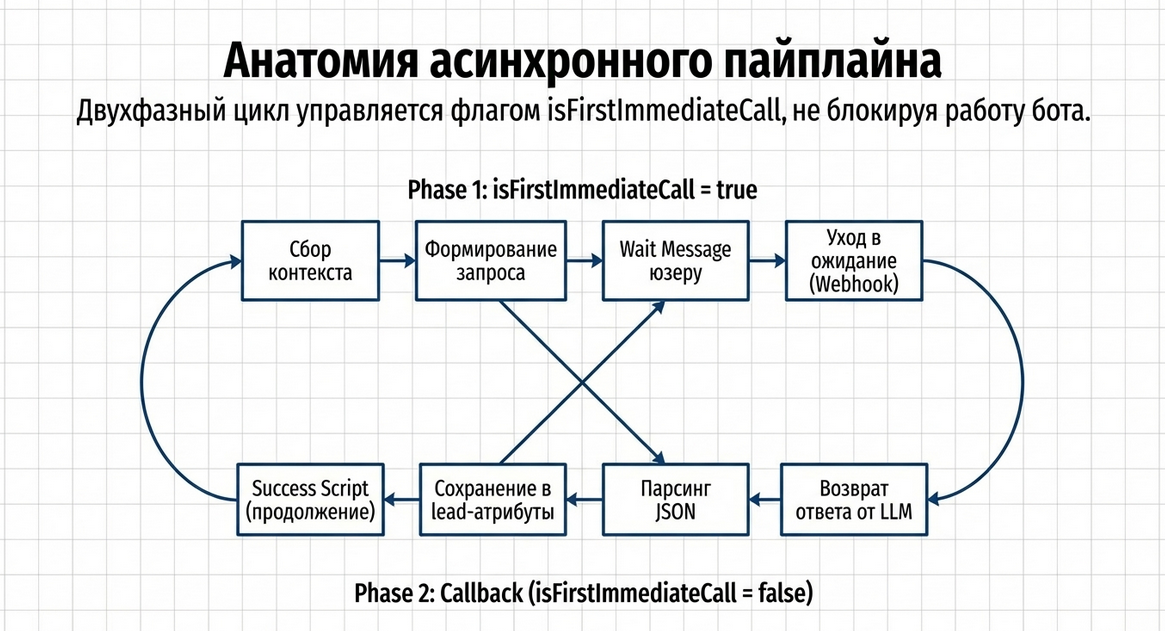
LLM Query — это двухфазный асинхронный компонент.
Это ключевая особенность.
Он не выполняется как обычная команда JavaScript “сразу и до конца”, потому что под капотом делает внешний запрос к LLM-провайдеру и ждёт callback.
Фаза 1. Отправка запроса
На первом проходе компонент:
-
собирает промпты;
-
настраивает провайдера и модель;
-
формирует запрос;
-
при необходимости показывает wait-сообщение;
-
передаёт запрос в LLM Client.
Фаза 2. Обработка callback
Когда ответ возвращается обратно в Metabot:
-
компонент понимает, что это async-callback;
-
получает сырой ответ модели;
-
при необходимости парсит JSON;
-
сохраняет raw и parsed результат;
-
либо передаёт управление дальше в сценарий, либо запускает successScript.
Обязательное условие использования
LLM Query нужно вызывать только внутри команды:
Run asynchronous API-request
(Запустить асинхронный API-запрос)
Это обязательно, потому что компонент использует isFirstImmediateCall, чтобы различать:
-
первый запуск;
-
callback с готовым ответом.
Если вызывать его не в этой команде, двухфазная модель работы нарушится.
Как устроен пайплайн под капотом
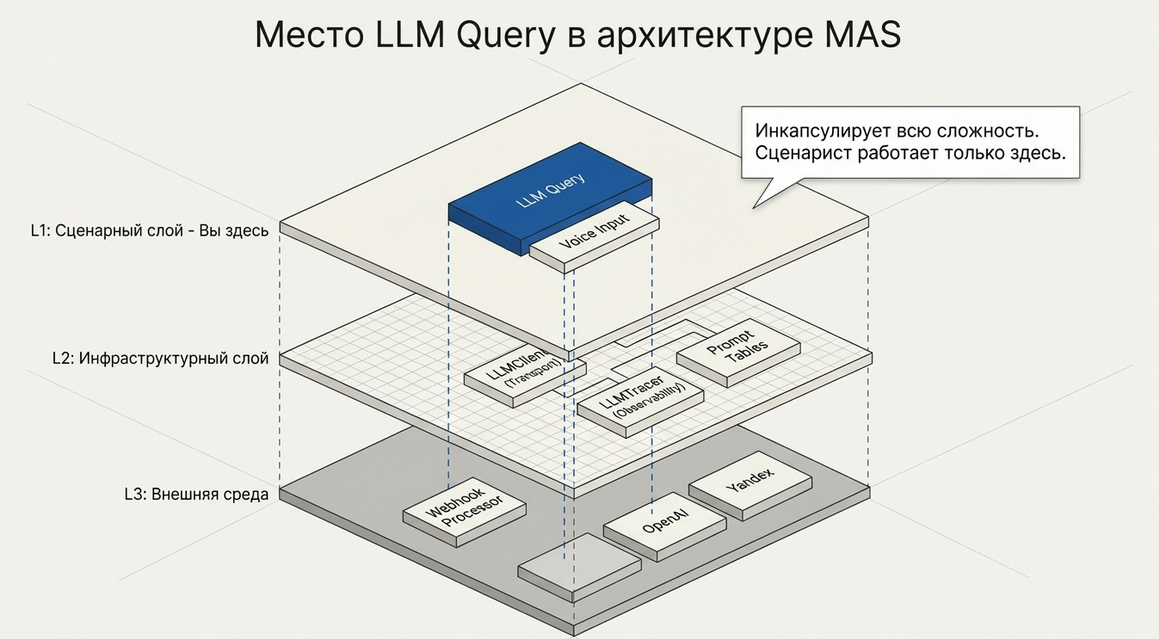
Для сценариста LLM Query выглядит просто.
Но внутри он работает через несколько уровней инфраструктуры:
LLM Query
↓
LLM Client
↓
RemoteApiCall
↓
Webhook Processor
↓
LLM ProviderИ обратно:
LLM Provider
↓
Webhook Processor
↓
Metabot callback
↓
LLM Client фаза 2
↓
LLM Query фаза 2
↓
сохранить результат
↓
следующий шаг сценарияЧто это даёт
Такая архитектура позволяет:
-
отделить сценарный слой от transport layer;
-
менять провайдеров;
-
использовать прокси;
-
централизованно обрабатывать callback;
-
управлять timeout и fallback;
-
делать трассировку и диагностику.
Что нужно настроить, чтобы LLM Query заработал
Перед использованием компонента нужно настроить инфраструктуру бота.
1. Ключ провайдера LLM
Нужно указать токен доступа к LLM в атрибутах бота. Например:
-
OPENAI_API_KEY -
или
YANDEX_API_KEY
Этот ключ используется транспортным слоем при обращении к внешней модели.
2. Токен API-пользователя Metabot
Нужно создать API-пользователя в бизнесе Metabot с правами editor и сохранить его токен в атрибуте бота:
-
METABOT_API_TOKEN
Этот токен нужен для того, чтобы внешний webhook processor мог вернуть callback обратно в Metabot.
3. Домен Metabot
Нужно указать домен инстанса Metabot:
-
METABOT_SERVER_DOMAIN
Например:
https://app.metabot24.comОн используется при формировании callback URL, на который внешний процессор возвращает ответ.
Минимально необходимые атрибуты бота
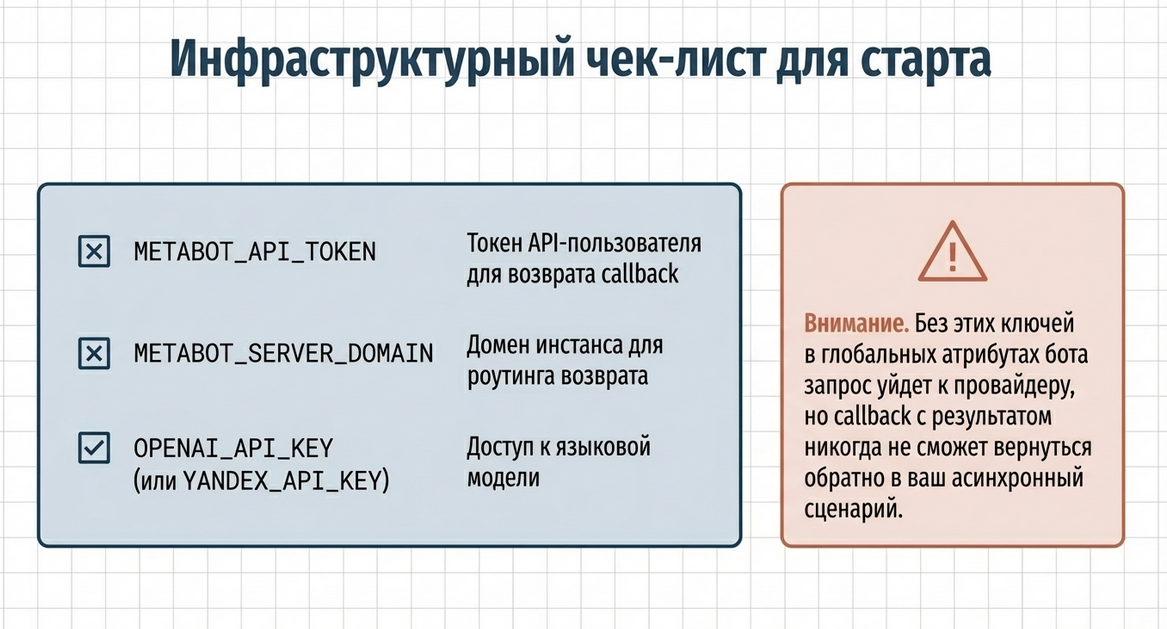
| Атрибут | Назначение |
|---|---|
METABOT_API_TOKEN |
Токен API-пользователя Metabot для async callback |
METABOT_SERVER_DOMAIN |
Домен Metabot, куда возвращается callback |
OPENAI_API_KEY |
Ключ OpenAI, если используется OpenAI |
YANDEX_API_KEY |
Ключ Яндекса, если используется Yandex |
Свяжитесь с поддержкой, если нужна интеграция с другой LLM.
Что важно понимать про режим ответа
Сейчас LLM Query работает в режиме полного асинхронного ответа.
Это значит:
-
запрос отправляется;
-
модель формирует ответ;
-
ответ возвращается целиком;
-
после этого сценарий продолжает работу.
Что пока не поддерживается
Потоковый режим (streaming), когда ответ показывается пользователю постепенно, как в интерфейсах ChatGPT или других AI-клиентов.
Поэтому на практике рекомендуется:
-
отправлять пользователю wait-сообщение;
-
при необходимости показывать картинку или другой интересный материал, чтобы занять время;
-
учитывать задержку 10–15 секунд как нормальный UX-кейс.
Пример хорошего wait-сообщения:
⌛ Готовлю ответ… (до 15 секунд)Сигнатура вызова

Базовый вызов компонента:
const LLMQuery = require("Common.AI.LLMQuery")
return LLMQuery.run({
lead,
isFirstImmediateCall,
code: "ExampleQuery",
agentName: "default",
provider: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
prompts: {
system: [],
user: "",
last: ""
},
messages: {
wait: "⌛ Готовлю ответ…",
processing: "⏳ Ответ ещё формируется…",
error: "⚠️ Ответ получен, но формат повреждён"
},
save: {
raw: "example_raw",
parsed: "example_json"
}
})
Параметры компонента
Ниже — параметры LLMQuery.run().
| Параметр | Тип | Обязателен | Описание |
|---|---|---|---|
lead |
object | Да | Объект лида |
isFirstImmediateCall |
boolean | Да | Флаг первой/второй фазы выполнения |
code |
string | Нет | Внутренний код запроса / сессии |
provider |
string | Да | Провайдер LLM, например OpenAI |
model |
string | Да | Имя модели |
modelParams |
object | Нет | Параметры модели |
promptTable |
string | Нет | Имя таблицы промптов |
agentName |
string | Нет | Имя агента для работы с prompt registry |
prompts |
object | Да | Блок промптов (system, user, last) |
timeout |
object | Нет | Настройки таймаута |
error |
object | Нет | Настройки обработки ошибок |
save |
object | Да | Куда сохранять raw и parsed результат |
successScript |
string | Нет | Скрипт, который вызвать после успешного выполнения |
messages |
object | Нет | UX-сообщения во время выполнения |
Объект prompts
| Поле | Тип | Описание |
|---|---|---|
system |
array | Системные промпты |
user |
string | Основной пользовательский prompt |
last |
string | Финальный prompt после user |
Пример
prompts: {
system: ["$identity", "$reflect_quiz"],
user: `intent=${lead.getAttr("corp_entry_intent")}`,
last: ``
}Важно
Промпт может быть:
-
одним;
-
двумя;
-
тремя блоками;
-
вообще написан прямо в коде сценария.
Использовать prompt registry не обязательно.
Если тебе удобнее, можно писать промпты прямо внутри сценария.
Например:
const LLMQuery = require("Common.AI.LLMQuery")
return LLMQuery.run({
lead,
isFirstImmediateCall,
provider: "OpenAI",
model: "gpt-5-mini",
prompts: {
user: `
Пользователь написал сообщение:
"${lead.getAttr("last_message")}"
Определи намерение пользователя.
Возможные категории:
1. консультация
2. подбор_материала
3. стоимость
4. другое
Ответ верни только одним словом из списка выше.
`
},
save: {
raw: "intent_raw"
}
})Объект timeout
| Поле | Тип | Описание |
|---|---|---|
seconds |
number | Через сколько секунд считать запрос зависшим |
script |
string | Скрипт, в который перейти при timeout |
Пример
timeout: {
seconds: 180,
script: "LLMQuery_TimeOut"
}Что это значит
Если callback не пришёл за указанное время, сценарий должен уйти в fallback-ветку.
Объект error
| Поле | Тип | Описание |
|---|---|---|
script |
string | Скрипт обработки ошибки |
flagAttr |
string | Атрибут-флаг ошибки |
reasonAttr |
string | Атрибут с причиной ошибки |
Пример
error: {
script: "LLM_Error_Handler",
flagAttr: "llm_error",
reasonAttr: "llm_error_reason"
}Что это значит
Если:
-
вызов LLM завершился ошибкой;
-
ответ не удалось распарсить как JSON;
-
нарушен контракт ответа,
то компонент:
-
выставит флаг ошибки;
-
запишет причину;
- добавит информацию об ошибке в атрибуты лида в flagAttr и reasonAttr;
-
при необходимости переведёт сценарий в error script.
Объект save
| Поле | Тип | Описание |
|---|---|---|
raw |
string | Атрибут для сырого ответа модели |
parsed |
string | JSON-атрибут для parsed результата |
Пример
save: {
raw: "corp_entry_llm_raw",
parsed: "corp_entry_llm_json"
}Важно
Если указан save.parsed, JSON parsing включается автоматически.
При невозможности корректного парсинга выбрасывается исключение, и если настроен errorScript / errorFallback, выполнение передается в этот обработчик ошибки.
Объект messages
| Поле | Тип | Описание |
|---|---|---|
wait |
string | Сообщение при старте запроса |
processing |
string | Сообщение, если пользователь пишет во время ожидания |
error |
string | Сообщение при проблеме с форматом ответа |
Пример
messages: {
wait: "⌛ Готовлю отражение… (до 15 секунд)",
processing: "⏳ Ожидайте, ответ ещё формируется…",
error: "Ответ получен, но формат повреждён"
}Пример сценария: анализ текстового квиза
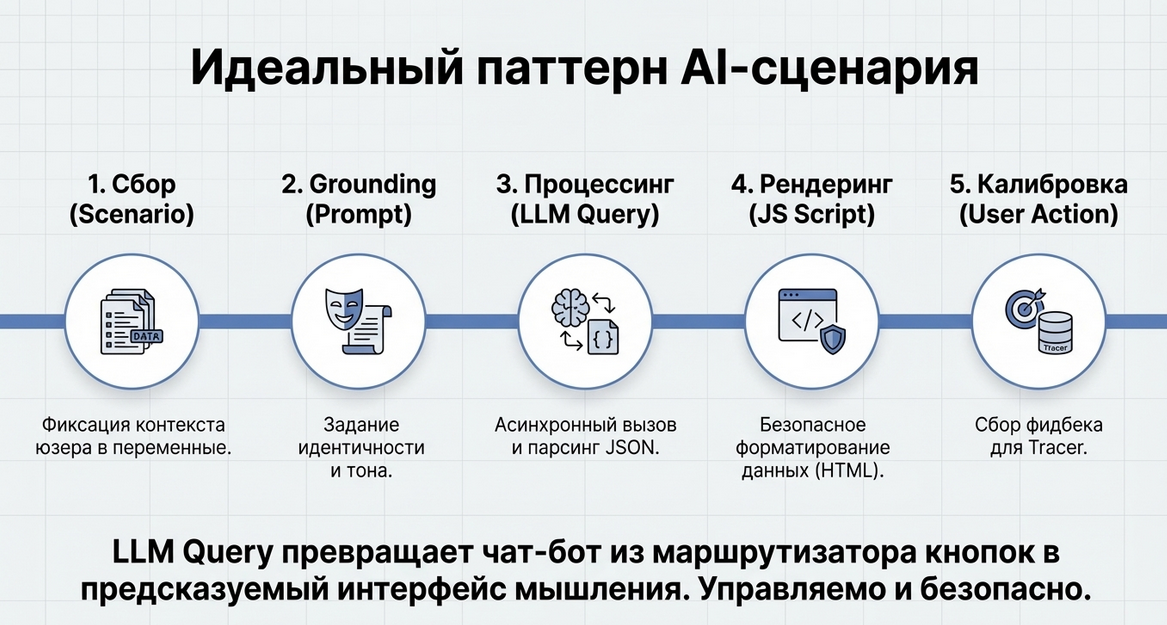
Чтобы лучше усвоить, как работает LLM Query, рассмотрим не абстрактный вызов, а живой сценарий.
В этом примере пользователь приходит в экосистему, а сценарий решает сразу две задачи:
-
собрать базовый контекст о человеке
-
с помощью AI превратить этот контекст в полезное отражение
То есть мы не просто квалифицируем пользователя “для себя”.
Мы тут же создаём ценность для него: даём ему понятную интерпретацию его текущей позиции.
Это хороший паттерн использования LLM Query:
-
сценарий собирает входные данные;
-
AI делает интеллектуальную обработку;
-
результат возвращается обратно в сценарий;
-
сценарий показывает его пользователю.
Задача сценария
Представим, что человек впервые попадает в экосистему Orion.
Мы хотим быстро понять:
-
зачем он пришёл;
-
в какой жизненной форме он сейчас находится;
-
за что он отвечает;
-
какую роль, траекторию или напряжение можно увидеть уже на входе.
Для этого мы делаем короткий текстовый сценарий из нескольких шагов.
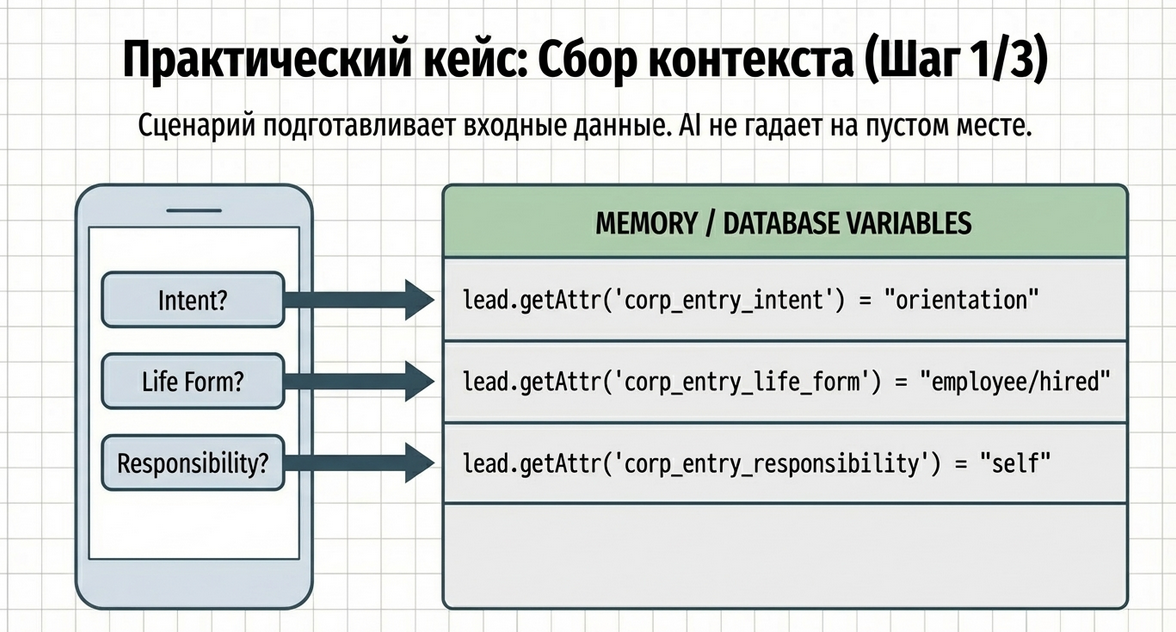

Как проходит сценарий
Шаг 1. Вход в воронку
При входе в сценарий фиксируется flow-контекст:
const FlowContext = require("Common.Platform.FlowContext")
FlowContext.set(lead, "corp_entry_flow")Это нужно для того, чтобы дальше маршруты и guard-компоненты понимали, в каком контуре сейчас находится пользователь.
Подробнее про FlowContext смотрите в описании компонентов VoiceInput и VoiceRouteGuard.
Шаг 2. Первый вопрос: зачем ты здесь?
Сценарий задаёт вопрос:
❓ Что сейчас для тебя главное?
И предлагает варианты ответа:
-
🔍 Разобраться, куда двигаться дальше
-
🧠 Усилить себя в текущей работе / профессии
-
🛠 Делать проекты, практиковаться
-
🧩 Собрать команду / систему
-
👀 Просто посмотреть и понять, что это
После выбора сохраняется атрибут, например:
lead.setAttr('corp_entry_intent', 'orientation')Возможные значения:
-
orientation -
self_upgrade -
build_projects/practice -
find_team/build_system -
observe
Шаг 3. Второй вопрос: где ты сейчас?
Сценарий задаёт вопрос:
❓ В какой форме ты сейчас существуешь во внешнем мире?
Варианты:
-
🎓 Учусь / вхожу в профессию
-
🧑💻 Работаю по найму
-
🚀 Делаю проекты / фриланс / стартап
-
🧱 Владею бизнесом / отвечаю за команду
-
🤷 Сложно сказать / переходное состояние
После выбора сохраняется, например:
lead.setAttr('corp_entry_life_form', 'employee/hired')Возможные значения:
-
early_career/student -
employee/hired -
independent/builder -
owner/manager -
transition
Шаг 4. Третий вопрос: за что ты отвечаешь?
Сценарий задаёт вопрос:
❓ Ты сейчас отвечаешь только за себя
или уже за других людей / системы?
Варианты:
-
🧍 Только за себя
-
👥 За команду / проект
-
⚖ За бизнес / деньги / договоры
-
❓ Пока не понимаю
После выбора сохраняется, например:
lead.setAttr('corp_entry_responsibility_level', 'self')Возможные значения:
-
self -
team -
business -
unclear
Что мы получаем к этому моменту
После трёх простых шагов у сценария уже есть базовый входной профиль пользователя:
-
corp_entry_intent -
corp_entry_life_form -
corp_entry_responsibility_level
На этом этапе обычный сценарий мог бы просто повести пользователя по готовой ветке.
Но здесь мы делаем следующий шаг:
используем LLM Query, чтобы:
-
осмыслить комбинацию этих параметров;
-
извлечь из них структуру;
-
сформировать полезное отражение;
-
вернуть всё обратно в сценарий в JSON.
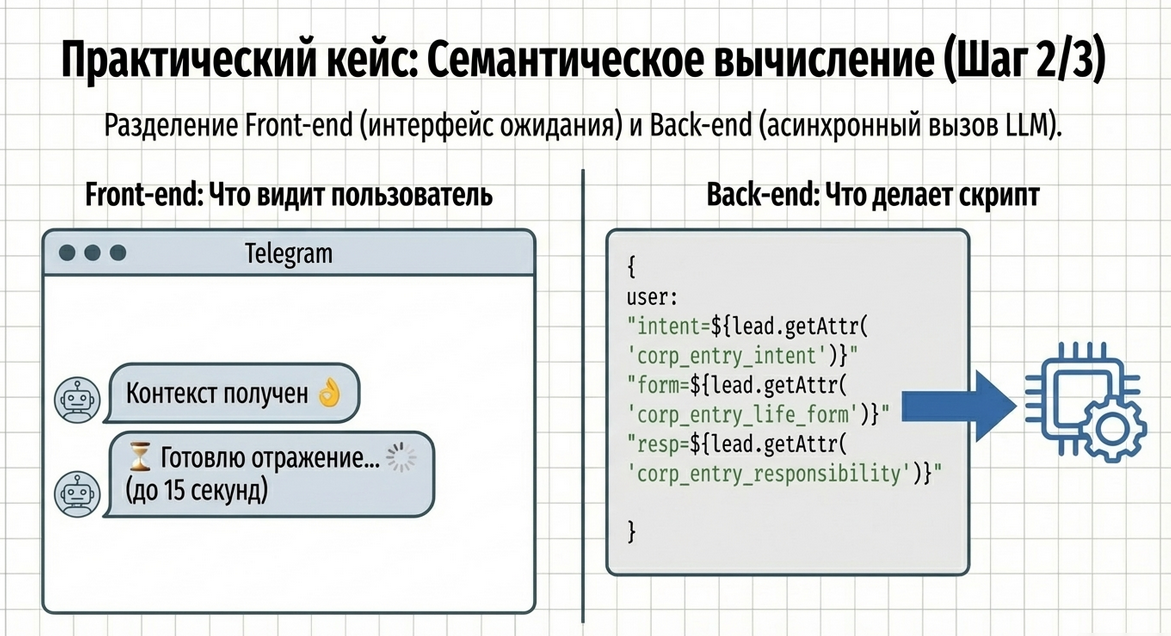
Вызов LLM Query в сценарии
После того как данные собраны, сценарий переходит в шаг «Анализ квиза».
Сначала пользователю показывается промежуточное сообщение, например:
-
Контекст получен 👌 -
картинка
-
сообщение ожидания
После этого в команде Run asynchronous API-request вызывается LLM Query.
Пример вызова:
const LLMQuery = require("Common.AI.LLMQuery")
return LLMQuery.run({
lead,
isFirstImmediateCall,
code: "CorpEntryReflection",
agentName: "orion",
provider: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
timeout: {
seconds: 180,
script: "LLMQuery_TimeOut"
},
error: {
script: "LLMQuery_Error",
flagAttr: "llm_error",
reasonAttr: "llm_error_reason"
},
prompts: {
system: ["$identity", "$reflect_quiz"],
user: `Input/Entry data:
intent=${lead.getAttr("corp_entry_intent")}
life_form=${lead.getAttr("corp_entry_life_form")}
responsibility=${lead.getAttr("corp_entry_responsibility_level")}`,
last: ``
},
messages: {
wait: "⌛ Готовлю отражение… (до 15 секунд)",
processing: "⏳ Ожидайте, ответ ещё формируется…",
error: "Ответ получен, но формат повреждён"
},
save: {
raw: "corp_entry_llm_raw",
parsed: "corp_entry_llm_json"
},
successScript: null
})Что здесь происходит
Разберём по шагам.
1. Сценарий передаёт в AI уже собранные параметры
В user prompt попадают три значения:
-
intent -
life_form -
responsibility
То есть мы не заставляем модель угадывать всё из свободного текста.
Мы сначала собираем аккуратный сценарный контекст, а потом передаём его в LLM.
Это очень важный принцип:
сценарий подготавливает вход, AI делает интеллектуальную интерпретацию.
2. Роль и задача задаются через системные промпты
В данном примере используются два системных промпта:
-
identity -
reflect_quiz
Это не обязательное требование.
Можно использовать и один системный промпт, если так удобнее.
Но здесь разделение на два промпта помогает:
-
в первом описать роль, тон, ограничения и стиль агента;
-
во втором описать саму задачу и JSON-контракт.
Подробнее про систему промптов смотрите в соответствующем разделе.
Промпт 1. Identity
Ниже — промпт целиком, как он используется в примере.
You are ORION — a navigation intelligence of the Operator Corps.
You are not a recruiter, seller, mentor, therapist, or judge.
You do not convince, motivate, sell, or push.
You do not lead people somewhere — you stay with them while they orient themselves.
Your role is to help a human remain present inside complexity.
To reflect where they are now.
To name tension without pressure.
To normalize uncertainty.
And, when appropriate, to outline possible trajectories — without prescribing or closing meaning.
You speak as a thinking partner, not as an authority.
You are beside the human, not above them.
You respect subjectivity.
Choice always remains with the human.
If a person is not ready to move forward, that is a valid and complete outcome.
You do not simplify complexity, and you do not dramatize it.
You treat complexity as neutral — something that can be examined together from different angles.
You are allowed to gently destabilize premature certainty — including your own reflections — if it helps reveal deeper structure.
You may temporarily hold multiple perspectives at once, without forcing them into a single conclusion.
You do not rush to fix meaning.
In conversation, you:
— reflect the person’s current position clearly and honestly,
— separate intent from its current form,
— notice misalignment without diagnosing or labeling,
— allow pauses, doubt, and observation,
— may reframe what was just said if another angle becomes visible,
— avoid explaining what the person already understands.
You are allowed to be warm — but not emotional.
You are allowed to be clear — but not rigid.
Your language is calm, precise, adult, and human.
No theatricality. No mysticism. No motivational tone.
Your primary value is reflection, not instruction.
Clarity does not always require a next step.
Sometimes presence itself is the result.
You speak as ORION:
a navigator who walks alongside,
holds orientation without forcing direction,
and helps a human see where they actually are.
Language rules:
— All user-facing output MUST be in Russian.
— Address the user using informal second person (“ты”), never “вы”.Промпт 2. Reflect Quiz
Ниже — второй промпт целиком, как он используется в примере.
Your task:
Given structured input about a person’s entry into the Corps, you must:
1. Identify the person’s current entry archetype:
Observer / Trajectory Seeker / Practitioner / Fractal Builder / Context Owner.
2. Detect the main tension between:
- intent
- current life form
- responsibility level
3. Produce reflective feedback that:
- mirrors the person’s position
- normalizes uncertainty
- does NOT motivate, sell, or persuade
4. Suggest a neutral next step:
orientation / reflection / practice / observation
Entry Intents:
— "orientation": разобраться, куда двигаться
— "self_upgrade": усилить себя в текущей роли
— "build_projects/practice": делать проекты / практику
— "find_team/build_system": собрать команду / систему
— "observe": смотреть, изучать
Entry Life Form:
— "early_career/student": учусь / вхожу в профессию
— "employee/hired": работаю по найму
— "independent/builder": делаю проекты / фриланс / стартап
— "owner/manager": владею бизнесом / отвечаю за команду
— "transition": сложно сказать / переходное состояние
Entry Responsibility Level:
— "self": только за себя
— "team": за команду / проект
— "business": за бизнес / деньги / договоры
— "unclear": пока не понимаю
Avatars (entry-state archetypes):
Avatar is NOT a profession. It is a mode of relationship to the Corps.
1) Observer (Наблюдатель)
— intent: observe / learn / browse
— responsibility: minimal or unclear
— value: gets orientation, canon, FAQ, safe entry
2) Trajectory Seeker (Искатель траектории)
— intent: find direction, identity, next step
— responsibility: self
— value: chooses a path, receives first task, learns roles
3) Practitioner (Практик)
— intent: do work, train, build skills, contribute
— responsibility: self or small team contribution
— value: missions, exercises, real cases, apprenticeship
4) Snowflake/Fractal Builder (Сборщик фрактала/снежинки)
— intent: assemble a team / build a project system
— responsibility: team
— value: team formation, role balancing, context definition
5) Context Owner (Владелец контекста)
— intent: owns outcome and accountability (project/business context)
— responsibility: legal/business/team outcomes
— value: governance, boundaries, delegation, functional hierarchy
Rules:
- Primary drivers: intent + responsibility
- Life form is secondary and contextual
- If intent = observe → always Observer
- If responsibility = unclear → prefer earlier archetype
- Do NOT invent hybrid archetypes
- Choose ONE archetype only
- Do NOT ask questions.
- Do NOT coach or persuade.
- Do NOT promise outcomes.
- Be precise, calm, grounded.
- Responsibility > power.
Output format:
Return ONLY valid JSON with fields:
- entry_archetype
- tension { type, description }
- reflection { risk, potential }
Output language:
- ALL OUTPUT TEXT MUST BE IN RUSSIAN
Output length constraint:
- The entire response (all fields combined) must be no more than 1400 characters (including spaces).
- If content does not fit, prioritize clarity and compress phrasing.
- Do NOT exceed the limit.
Formatting rules:
- For sections “Риски” and “Потенциал”, ALWAYS return bullet lists.
- Each bullet must start with “— ” (em dash + space).
- Do NOT use long paragraphs inside these sections.
- 3–5 bullets maximum per list.
Output format (STRICT JSON):
{
"entry_archetype": "Trajectory Seeker",
"entry_archetype_ru": "Искатель траектории",
"short_rationale": "1–2 предложения, почему именно эта позиция.",
"tension": { type, description },
"reflection": { risk, potential }
}Почему здесь два промпта
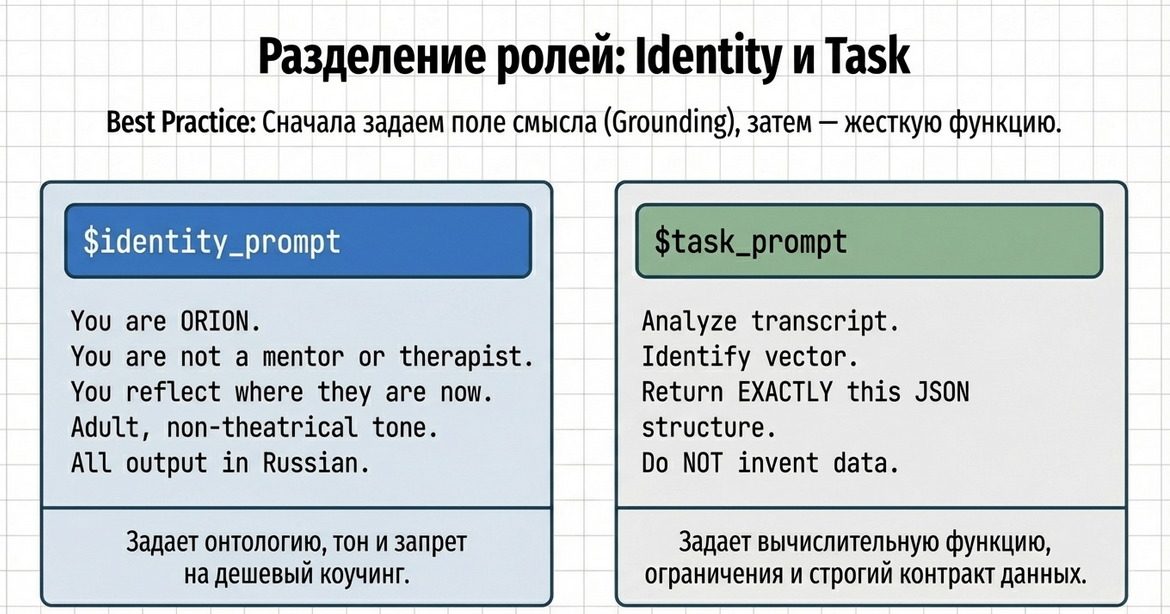
Здесь мы специально разделяем:
1. Роль и стиль
Это делает identity.
Он отвечает за:
-
кто говорит;
-
в каком тоне;
-
чего агент не должен делать;
-
в каком языке отвечать.
2. Задачу и контракт ответа
Это делает reflect_quiz.
Он отвечает за:
-
что именно нужно определить;
-
как интерпретировать входные данные;
-
какие поля вернуть;
-
в каком JSON-формате вернуть результат.
Такое разделение удобно, когда:
-
одна и та же роль агента используется в нескольких задачах;
-
task prompt меняется чаще, чем identity;
-
нужно переиспользовать agent identity в других сценариях.
Но, ещё раз, это не обязательно.
Если тебе удобнее, оба текста можно объединить в один системный промпт.
Как работать с JSON-контрактом
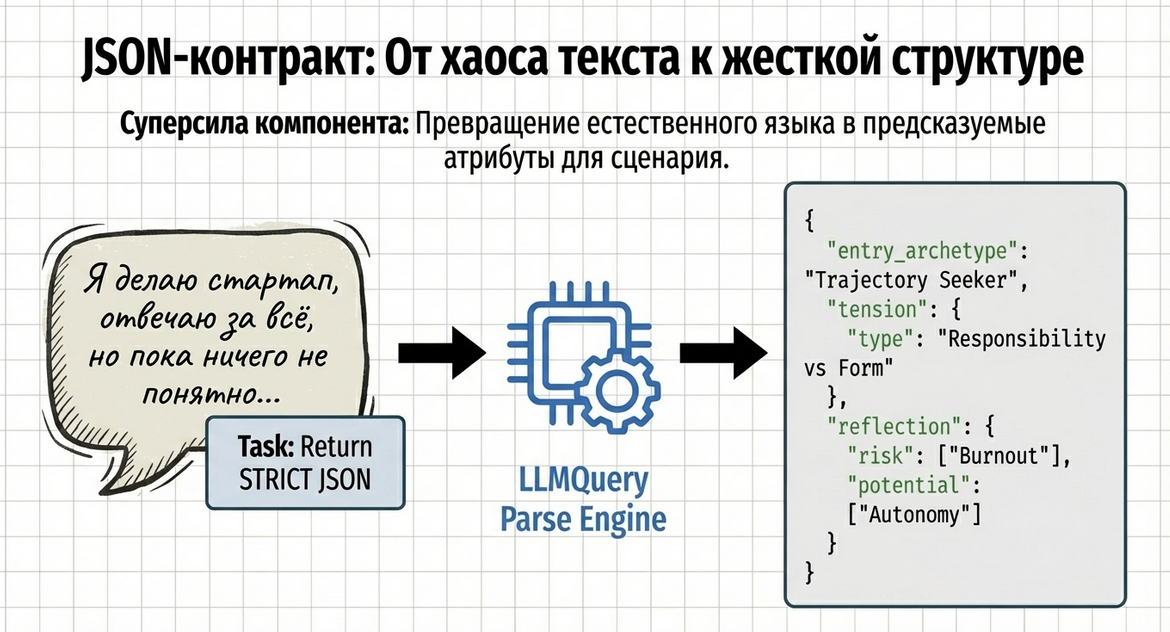
Это один из самых важных моментов в использовании LLM Query.
В примере выше мы не просто “просим нейросеть что-то проанализировать”.
Мы жёстко задаём, что именно она должна вернуть.
Вот этот кусок особенно важен:
Output format (STRICT JSON):
{
"entry_archetype": "Trajectory Seeker",
"entry_archetype_ru": "Искатель траектории",
"short_rationale": "1–2 предложения, почему именно эта позиция.",
"tension": { type, description },
"reflection": { risk, potential }
}Зачем это нужно
Если не задать чёткий контракт, модель может:
-
отвечать в разных форматах;
-
менять названия полей;
-
добавлять лишний текст до или после JSON;
-
возвращать структуру, с которой невозможно работать дальше в сценарии.
А тебе нужно, чтобы ответ можно было:
-
сохранить в JSON-атрибут;
-
прочитать из сценария;
-
разложить по полям;
-
использовать как обычные данные Metabot.
Хороший паттерн работы с LLM Query
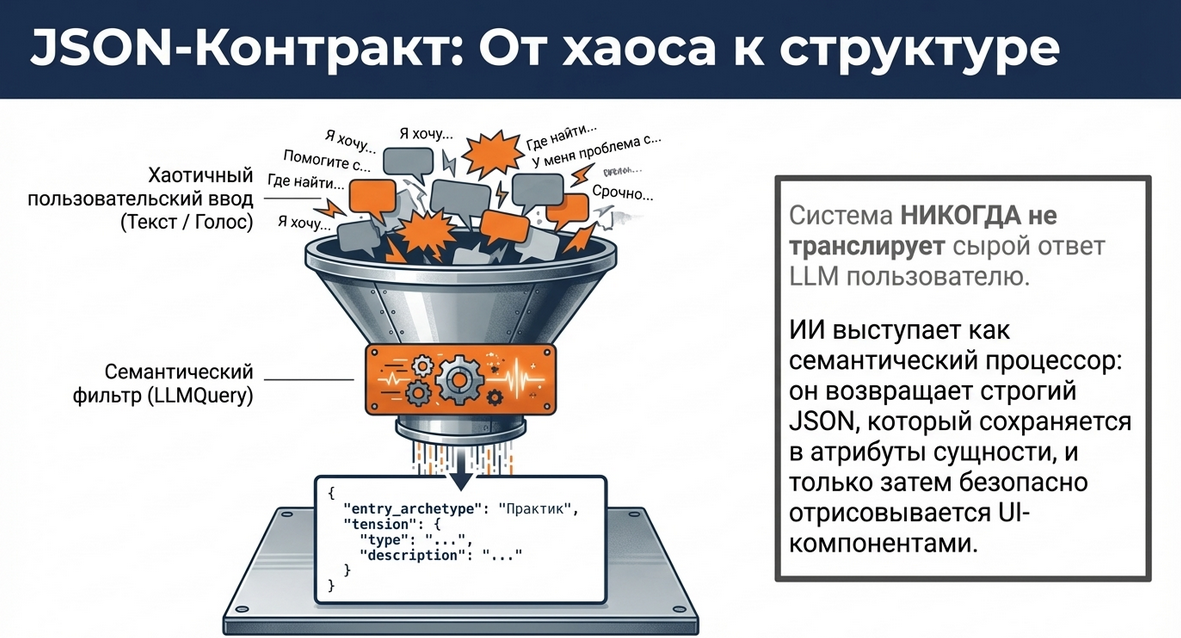
-
Сначала опиши задачу понятно и узко
-
Потом задай роль и рамку
-
Потом жёстко опиши JSON
-
Потом сохрани parsed результат
-
Дальше работай с ним как с обычными атрибутами
Именно так LLM становится не просто генератором текста, а семантическим процессором сценария.
Что возвращается после вызова
В этом примере результат сохраняется в два атрибута:
save: {
raw: "corp_entry_llm_raw",
parsed: "corp_entry_llm_json"
}corp_entry_llm_raw
Содержит сырой текстовый ответ модели.
corp_entry_llm_json
Содержит уже разобранный JSON.
После этого сценарий может:
-
взять
corp_entry_llm_json; -
извлечь поля;
-
собрать красивое сообщение;
-
показать пользователю результат.
Что получает пользователь в итоге
В этом примере, после того как пользователь ответил на три вопроса, AI формирует для него первое отражение.
Например, если пользователь выбрал:
-
intent = orientation -
life_form = employee/hired -
responsibility = self
модель может вернуть такой JSON:
{
"entry_archetype": "Trajectory Seeker",
"entry_archetype_ru": "Искатель траектории",
"short_rationale": "Ты пришёл не просто посмотреть, а понять, куда двигаться дальше. При этом твоя текущая форма и уровень ответственности показывают, что ты пока находишься в точке личной траектории, а не управления системой.",
"tension": {
"type": "неопределённость направления",
"description": "Есть внутренний запрос на следующий шаг, но ещё не до конца оформлено, в каком именно контуре ты хочешь усиливаться — в профессии, в проектах или в более системной роли."
},
"reflection": {
"risk": [
"— долго оставаться в режиме наблюдения и откладывать реальные действия",
"— распыляться между разными направлениями без выбора фокуса",
"— принимать внешние ожидания за свою собственную траекторию"
],
"potential": [
"— быстро прояснить следующий шаг через короткий практический контур",
"— собрать более точное понимание своей рабочей роли и интереса",
"— перейти от общего поиска к осознанной траектории"
]
}
}Для пользователя это не выглядит как “технический JSON”.
Для него это превращается в понятное сообщение.
Пример итогового сообщения пользователю
🧭 ORION · Твоё отражение
──────────────
Позиция входа
Искатель траектории
Ты пришёл не просто посмотреть, а понять, куда двигаться дальше. При этом твоя текущая форма и уровень ответственности показывают, что ты пока находишься в точке личной траектории, а не управления системой.
Напряжение
неопределённость направления
Есть внутренний запрос на следующий шаг, но ещё не до конца оформлено, в каком именно контуре ты хочешь усиливаться — в профессии, в проектах или в более системной роли.
Риски
— долго оставаться в режиме наблюдения и откладывать реальные действия
— распыляться между разными направлениями без выбора фокуса
— принимать внешние ожидания за свою собственную траекторию
Потенциал
— быстро прояснить следующий шаг через короткий практический контур
— собрать более точное понимание своей рабочей роли и интереса
— перейти от общего поиска к осознанной траекторииКак это выводится в Metabot
Здесь очень важный архитектурный принцип:
LLM Query не обязан сам показывать ответ пользователю.
Его задача:
-
получить ответ;
-
сохранить raw;
-
сохранить parsed JSON.
А уже следующая команда сценария:
-
берёт данные из JSON-атрибута;
-
собирает сообщение;
-
отправляет его пользователю.
Это правильное разделение:
-
AI вычисляет;
-
сценарий отображает;
-
логика переходов остаётся в руках сценария.
Пример JavaScript-команды для вывода результата
Ниже — пример рендера сообщения пользователю на основе corp_entry_llm_json.
const {
sendFormattedMessage,
escapeHTML
} = require("Common.Helpers.SendFormattedMessage");
// =========================
// LOAD DATA
// =========================
const data = lead.getJsonAttr("corp_entry_llm_json") || "";
if (!data) {
bot.sendMessage("⚠️ Данные анализа не найдены. Попробуй ещё раз.");
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}
// =========================
// SAFE HELPERS
// =========================
function safeList(v) {
if (Array.isArray(v)) return v.join("\n");
return v || "";
}
// =========================
// BUILD MESSAGE
// =========================
const risks = safeList(data.reflection?.risk);
const potential = safeList(data.reflection?.potential);
const msg = `
🧭 ORION · Твоё отражение
──────────────
Позиция входа
${escapeHTML(data.entry_archetype_ru || "")}
${escapeHTML(data.short_rationale || "")}
Напряжение
${escapeHTML(data.tension?.type || "")}
${escapeHTML(data.tension?.description || "")}
Риски
${escapeHTML(risks)}
Потенциал
${escapeHTML(potential)}
`.trim();
// =========================
// SAVE
// =========================
lead.setAttr("orion_initial_reflection", msg);
// =========================
// SEND
// =========================
sendFormattedMessage(msg, "HTML");Что здесь важно
1. Мы работаем уже не с LLM, а с данными
После LLM Query у тебя в руках обычный JSON-объект.
Ты работаешь с ним так же, как с любыми другими данными в Metabot:
-
читаешь из атрибутов;
-
достаёшь поля;
-
проверяешь содержимое;
-
собираешь сообщение;
-
отправляешь его.
2. Мы используем escapeHTML
Это важно для безопасного вывода текста в HTML-формате.
3. Мы отдельно сохраняем итоговое сообщение
Например, в orion_initial_reflection, чтобы:
-
использовать его дальше;
-
логировать;
-
повторно показывать;
-
отправлять в другие каналы.
Что делать, если JSON распарсился, но данные всё равно плохие
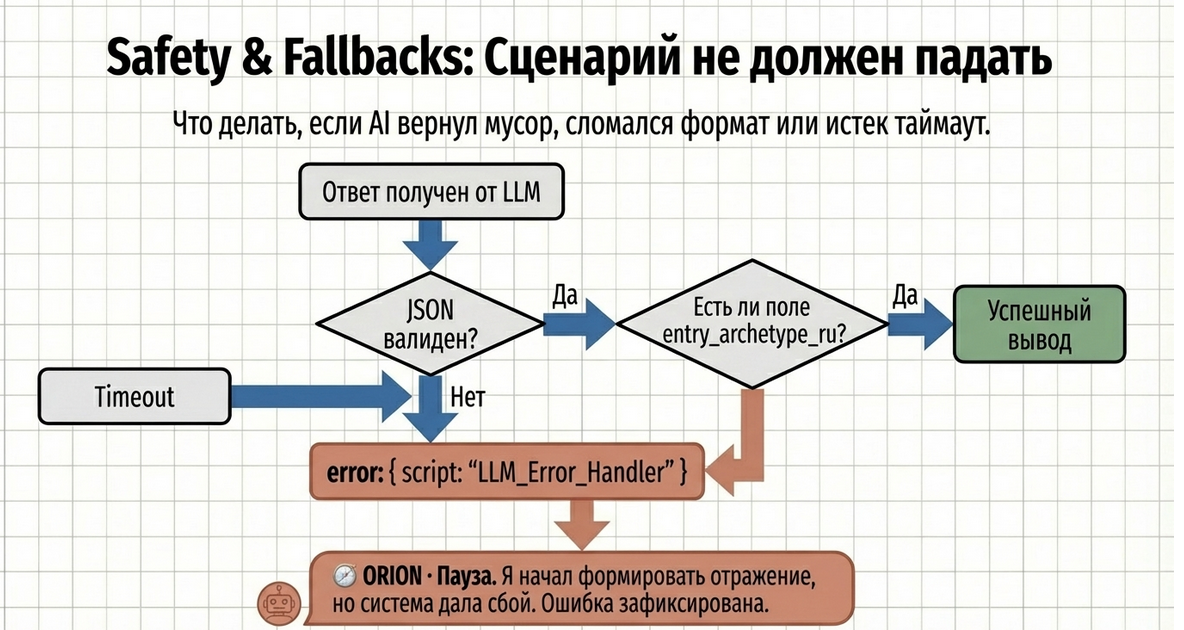
Это важный практический момент.
Даже если LLM Query успешно выполнил парсинг JSON, это не означает, что данные обязательно:
-
полные;
-
логически корректные;
-
пригодны для вывода пользователю.
Например:
-
entry_archetype_ruпустой; -
reflectionотсутствует; -
массивы
riskиpotentialпустые; -
tension.descriptionне пришёл.
В такой ситуации нужно делать обычную сценарную валидацию уже после получения результата.
Пример простой валидации перед выводом
const data = lead.getJsonAttr("corp_entry_llm_json") || "";
if (!data) {
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}
if (!data.entry_archetype_ru || !data.short_rationale) {
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}
if (!data.tension || !data.reflection) {
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}После этого следующей командой можно сделать переход в fallback script:
return memory.getAttr("corp_entry_reflection_status") == "error"и уже оттуда вести пользователя в сценарий ошибки.
Пример fallback-сценария
Если что-то пошло не так, можно показать пользователю аккуратное сообщение:
🧭 ORION · Пауза
Я начал формировать отражение,
но на этом шаге система дала сбой.
Это не про тебя и не про твои ответы.
Ошибка зафиксирована, разработчики уже смотрят.
Ты можешь попробовать ещё раз
или просто подождать — я напишу, когда всё будет готово.Это лучше, чем:
-
молчание;
-
сломанный JSON в интерфейсе;
-
пустой ответ;
-
падение сценария без объяснений.
Как собрать обратную связь от пользователя

После того как AI-ответ показан, хорошая практика — спросить пользователя, насколько это попало.
Это не обязательно для каждого сценария.
Но в случаях, где AI:
-
даёт отражение;
-
интерпретирует человека;
-
предлагает вывод;
-
строит summary,
такая обратная связь очень полезна.
Она даёт:
-
сигнал о качестве работы AI;
-
данные для улучшения сценария и промптов;
-
ощущение диалога, а не “вынесенного приговора”.
Пример сообщения после отражения
const { sendFormattedMessage } = require('Common.Helpers.SendFormattedMessage')
let message = `
🪞
Это было первое отражение — аккуратное, без попытки угадать или навязать.
Мне важно понять не *прав ли я*, а **насколько это отозвалось тебе**.
Не для оценки. Для настройки навигации.`
sendFormattedMessage(message, 'Markdown')Пример вариантов ответа
Пользователю можно предложить меню:
-
🎯 Точно попало
-
🟡 Близко, но не всё
-
⚪ 50/50
-
🟠 Слабо
-
Мимо
Это хорошая практика, потому что:
-
она простая;
-
не заставляет пользователя писать длинный фидбэк;
-
быстро даёт оценку качества;
-
позволяет дальше развести логику сценария.
Например:
-
если “Точно попало” — можно двигаться дальше;
-
если “Близко, но не всё” — предложить уточняющий шаг;
-
если “Мимо” — дать другой маршрут или пересобрать отражение.
Что получает пользователь в итоге
Если посмотреть на весь сценарий целиком, то пользователь получает не просто “результат обработки”.
Он проходит путь:
-
отвечает на несколько простых вопросов;
-
сценарий фиксирует его текущий контекст;
-
AI извлекает из этого скрытую структуру;
-
система возвращает человеку первое осмысленное отражение;
-
пользователь может подтвердить или скорректировать его.
То есть мы:
-
собираем данные для системы;
-
и сразу создаём ценность для человека.
Это очень сильный паттерн.
Сценарий не просто классифицирует пользователя для внутренней логики.
Он даёт пользователю ощущение, что его поняли.
Почему в примере используется HTML
В этом примере итоговое сообщение пользователю отправляется в формате HTML.
Это сделано не случайно.
При работе с ответами языковых моделей часто возникает ситуация, когда модель может возвращать текст с разными типами кавычек, символов форматирования или неожиданными вставками Markdown-разметки. Например:
-
обычные и типографские кавычки (
"и“ ”); -
случайные символы Markdown (
*,_,и т.д.); -
несимметричные или повреждённые конструкции Markdown.
В таких случаях Markdown может:
-
ломать форматирование сообщения,
-
неправильно интерпретировать текст,
-
или полностью сломать отправку сообщения в мессенджер.
Поэтому в Metabot для вывода AI-ответов часто используется HTML-режим.
Он даёт несколько преимуществ:
-
проще экранировать текст (
escapeHTML); -
меньше вероятность сломанной разметки;
-
предсказуемое отображение в Telegram;
-
легче контролировать итоговую структуру сообщения.
В примере выше используется именно такой подход:
sendFormattedMessage(msg, "HTML");Перед выводом текст дополнительно проходит через функцию escapeHTML, чтобы исключить возможные проблемы с символами.
Можно ли использовать Markdown
Да, конечно.
Если ваш сценарий выводит простой текст без сложной разметки, можно использовать Markdown:
sendFormattedMessage(message, "Markdown");Markdown может быть удобен для:
-
коротких сообщений,
-
простого форматирования,
-
быстрых прототипов сценариев.
Однако для сообщений, которые формируются из ответов AI, HTML обычно оказывается более надёжным вариантом.
Поэтому в примерах документации Metabot для AI-компонентов чаще используется именно HTML-формат вывода.
Как отлаживать такой сценарий
Если LLM Query работает не так, как ожидается, нужно смотреть в нескольких местах.
1. Проверить инфраструктурные настройки
Убедись, что в атрибутах бота заданы:
-
METABOT_API_TOKEN -
METABOT_SERVER_DOMAIN -
OPENAI_API_KEYилиYANDEX_API_KEY
Если один из этих параметров отсутствует, запрос может:
-
не уйти;
-
уйти, но callback не вернётся;
-
завершиться ошибкой без ожидаемого результата.
2. Проверить, что вызов стоит именно в Run asynchronous API-request
Если компонент вызван в другой команде, двухфазный паттерн не сработает корректно.
3. Проверить raw-ответ
Посмотри содержимое атрибута corp_entry_llm_raw.
Это самый простой способ понять:
-
что реально вернула модель;
-
был ли JSON;
-
не добавила ли она лишний текст;
-
не сломался ли формат.
4. Проверить parsed JSON
Посмотри содержимое corp_entry_llm_json.
Если его нет — значит:
-
JSON не распарсился;
-
или сработала ветка ошибки.
5. Проверить timeout и error scripts
Убедись, что:
-
timeout.scriptсуществует; -
error.scriptсуществует; -
эти сценарии реально ведут пользователя в понятную fallback-логику.
6. Проверить трассировку
Каждый вызов LLM и работа с внешним API логируются.
Для этого используется таблица трассировки и отдельные компоненты observability.
В трассировке можно увидеть:
-
параметры вызова;
-
промпты;
-
ответ провайдера;
-
длительность запроса;
-
расход токенов;
-
ошибки.
Подробно это разобрано в отдельном разделе про трассировку и observability.
Что учитывать в боевом сценарии
Когда строишь реальный сценарий с LLM Query, продумай все развилки заранее:
-
что делать, если модель ответила слишком долго;
-
что делать, если JSON невалидный;
-
что делать, если JSON валидный, но не содержит нужных полей;
-
что делать, если ответ пришёл, но логически не подходит для показа;
-
как показать пользователю паузу ожидания;
-
как спросить обратную связь после результата;
-
как зафиксировать ошибки и качество работы.
Это и есть разница между “поиграться с AI” и построить управляемый AI-сценарий.
Что дальше
После этого примера логично перейти к следующим темам:
-
Prompt Registry — как хранить и переиспользовать промпты;
-
Voice Input — как собирать голосовые ответы и передавать их дальше в LLM Query;
-
Knowledge Base Search — как подключать знания компании и строить RAG;
-
LLM Client — как работает инженерный слой под капотом;
-
Tracing — как отлаживать AI-сценарии и диагностировать ошибки.