06. AI компоненты: Metabot Agent Stack
AI-компоненты для сценариев, диалогов и управляемых интеллектуальных процессов.
- Metabot — кандидат на рантайм для AI-native коммуникационных систем
- LLM Query — AI-запросы к LLM внутри сценариев
- Voice Input — голосовой интерфейс для AI-воронок
- MultiVoiceInput — сбор нескольких голосовых сообщений в одну коллекцию
- Для кругозора
- ИИ-трансформация в AI-First компанию
- Критерии готовности компании к AI-First трансформации
- Мировой опыт ИИ-трансформации
- Обзор MAS (старая версия)
- Документация и уроки (старая версия)
- Ядро системы - Маршрутизатор и RAG
- Создание простого агента
- Документация по LLMClient
- Создание ClickHouse - SQL агента
- Руководство по работе с базой знаний (RAG)
- Документация по LLMTracer
- Аналитика и нагрузки
- LLMTracer - Плагин для трассировки запросов к LLM
- Конфигурация
- Ошибки и отладка
- Eval - Тестирование
Metabot — кандидат на рантайм для AI-native коммуникационных систем
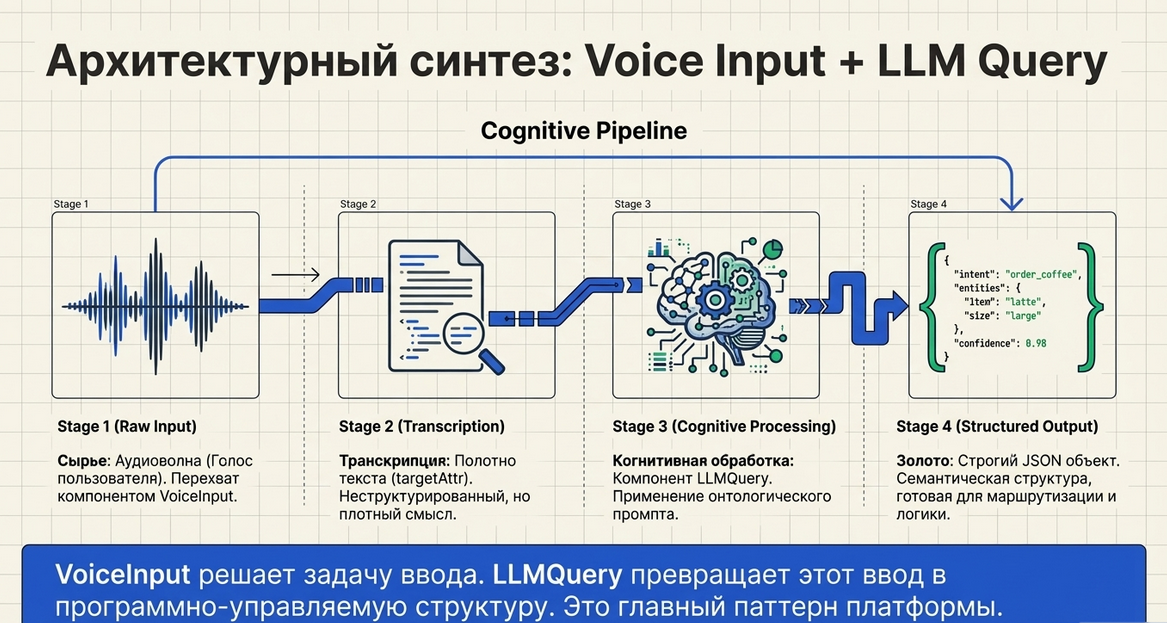
За последний год рынок искусственного интеллекта заметно повзрослел. Стало ясно, что сильная языковая модель сама по себе ещё не делает сильный продукт. Реальная ценность возникает там, где вокруг модели построена система исполнения: контекст, память, инструменты, маршрутизация, контроль состояния, тестирование, правила и связь с реальной бизнес-логикой. Anthropic в своей инженерной статье про long-running agents показывает именно это: агенту нужен не только “ум”, но и harness — среда, где сохраняется прогресс, читаются рабочие артефакты проекта, используются инструменты и проверяется результат. OpenAI в официальных материалах формулирует похожую мысль: агенты — это приложения, которые умеют планировать, вызывать инструменты, передавать задачи между специализациями и держать состояние, достаточное для многошаговой работы. Google со своей стороны продвигает context-driven development, где спецификации, планы и контекст становятся постоянными артефактами рядом с кодом, а не разовыми сообщениями в чате. (Anthropic)
Для коммуникационного рынка это означает простую вещь: AI-воронки были только первым этапом. Следующий этап — это AI-native коммуникационные системы, где интеллект не добавляется “сбоку”, а становится частью сценария, данных, маршрутов и исполнения.
Именно в этом месте становится интересен Metabot.
Что такое Metabot в этом контексте
Metabot — это не просто платформа чат-ботов и не просто визуальный конструктор сценариев. Это ComOps-платформа и расширяемый temporal runtime, в котором соединяются коммуникации, операции и интеллект. В Metabot уже есть необходимые слои для такой архитектуры: сценарии, JavaScript-логика, отложенные действия, память, кастомные таблицы как data layer, встроенный API-конструктор для внутренних и внешних интеграций, плагины и контакт-центр.
Это важно, потому что AI-native система строится не вокруг одного чата с моделью, а вокруг связки:
- вход пользователя,
- сценарный контекст,
- интеллект,
- данные,
- действия в системе,
- переход в следующий шаг,
- сохранение состояния во времени.
То есть здесь коммуникация перестаёт быть просто обменом сообщениями. Она становится исполняемым контуром, который может думать, помнить и действовать.
Почему обычного “AI в воронке” уже недостаточно
На первом этапе рынок научился подключать LLM к коммуникациям: генерировать ответы, собирать тексты, вставлять AI-блок в flow. Это дало много пользы, но быстро показало ограничения.
Как только система становится чуть сложнее, появляются требования другого уровня:
- понимать свободный текст, а не только кнопки;
- принимать голос как полноценный вход;
- извлекать структуру из неструктурированного запроса;
- хранить результат как данные, а не только как ответ модели;
- передавать результат дальше в бизнес-логику;
- вызывать API и таблицы;
- маршрутизировать пользователя по ролям, статусам и событиям;
- сохранять состояние между шагами и во времени.
На этом уровне AI уже нельзя воспринимать как “умный ответ”. Он становится частью исполнения сценария.
LLM Query: интеллект как шаг сценария
Именно так в Metabot устроен компонент LLM Query.
LLM Query — это не просто вызов модели. Это высокоуровневый AI-компонент, который встраивает запрос к LLM прямо внутрь сценария как обычный шаг логики. Он собирает контекст, формулирует задачу, задаёт формат ответа, получает результат и позволяет работать с этим результатом дальше как с обычными данными системы. Компонент поддерживает не только текст, но и структурированный JSON, а также асинхронный двухфазный режим с callback-логикой, где ответ модели возвращается в сценарий уже как часть дальнейшего исполнения. (LLM Query) (Agents SDK | OpenAI API)
Практически это означает следующее:
- сценарий собирает входные данные;
- модель делает интеллектуальную обработку;
- результат приходит не как “болтовня”, а как рабочий выход;
- дальше сценарий продолжает движение уже на основе результата модели.
То есть интеллект встраивается не в интерфейс, а в логику процесса.
Voice Input: голос как полноценный интерфейс входа
Похожая логика заложена в компонент Voice Input.
Voice Input — это не просто speech-to-text. Это голосовой интерфейс для AI-воронок и AI-native сценариев. Компонент принимает голосовые сообщения, аудио или видеосообщения, ожидает ввод пользователя в нужной точке, запускает speech-to-text и возвращает распознанный текст обратно в сценарий. После этого текст может использоваться как обычный вход для дальнейшей логики — в том числе для LLM Query, маршрутизации, профилирования и принятия решений. (Voice Input) (Voice agents | OpenAI API)
Здесь особенно важно то, что голос перестаёт быть просто медиафайлом. Он становится first-class input для системы. Это позволяет строить коммуникационные контуры, в которых человек может не только нажимать кнопки и печатать текст, но и говорить свободно, а система при этом не теряет управляемость и не отрывается от бизнес-логики.
Что это даёт сценаристам, CJM-специалистам и digital-командам
Если вы привыкли собирать коммуникационные flow, customer journey, onboarding-цепочки, сервисные или маркетинговые воронки, то главный сдвиг здесь такой:
следующий шаг — это не просто “добавить AI”, а научиться проектировать сценарии, в которых AI становится частью runtime.
Это значит, что сценарист или product-специалист получает не “магическую модель”, а новый рабочий материал:
- свободный текст как источник смысла;
- голос как вход в сценарий;
- структурированный ответ модели как данные;
- AI как шаг процесса;
- коммуникацию как часть системы исполнения.
Именно здесь Metabot становится интересен не как “ещё одна бот-платформа”, а как кандидат на рантайм для AI-native коммуникационных систем.
Почему это особенно важно сейчас
Потому что рынок уже начал смещаться в эту сторону. Foundation-модели становятся всё сильнее и доступнее, а значит, реальная дифференциация всё чаще уходит в:
- инженерную обвязку вокруг модели,
- контекст и память,
- бизнес-логику,
- observability и traceability,
- интеграции,
- доменные знания,
- способность превращать ответ модели в действие. (Anthropic)
Для коммуникационных систем это особенно важно. Здесь мало просто “ответить красиво”. Нужно, чтобы после ответа что-то происходило:
- человек попадал в нужную ветку;
- данные сохранялись;
- запускались следующие шаги;
- подключались операторы;
- обновлялись статусы;
- вызывались внешние системы;
- сохранялся контекст пути во времени.
Это и есть territory Metabot.
Для кого этот подход
Эта архитектура особенно полезна тем, кто уже вырос из простых flow и чувствует, что классические AI-воронки начинают упираться в потолок:
- сценаристам и bot-builder’ам;
- CJM- и CRM-специалистам;
- messaging-маркетологам;
- digital-агентствам;
- продуктовым командам, которые отвечают за коммуникационный контур;
- техническим специалистам, которым нужно соединить AI, сценарии, данные и интеграции.
Если ваша задача заканчивается генерацией ответа, вам может хватить и более простого инструмента. Если же вам нужно, чтобы интеллект понимал, возвращал структуру и двигал систему дальше, тогда вам уже нужен runtime.
Что читать дальше
Чтобы лучше понять, куда движется рынок AI и почему важен именно execution layer, рекомендуем начать с этих материалов:
- Anthropic: Effective harnesses for long-running agents — о том, почему сильному агенту нужна среда исполнения, а не только модель. (Anthropic)
- OpenAI: Agents SDK и Building agents — о том, что агентные приложения строятся вокруг инструментов, состояния, orchestration и traceability. (OpenAI Разработчики)
- OpenAI: Voice agents — о том, как голосовые workflows требуют явного контроля над распознаванием, reasoning и выходом в действие. (OpenAI Разработчики)
- Google: Conductor: context-driven development for Gemini CLI — о том, почему спецификации, планы и контекст должны жить как устойчивые артефакты рядом с кодом. (Блог разработчиков Google)
Итог
AI в коммуникациях — это уже не про “умные ответы” и не про “ещё одну воронку”. Следующий уровень — это системы, где интеллект становится частью сценария, а сценарий становится частью исполнения.
Metabot — кандидат на рантайм для AI-native коммуникационных систем именно потому, что в нём уже есть всё необходимое основание: temporal logic, сценарии, данные, API, плагины, контакт-центр и AI-компоненты, которые можно встроить в реальную рабочую логику.
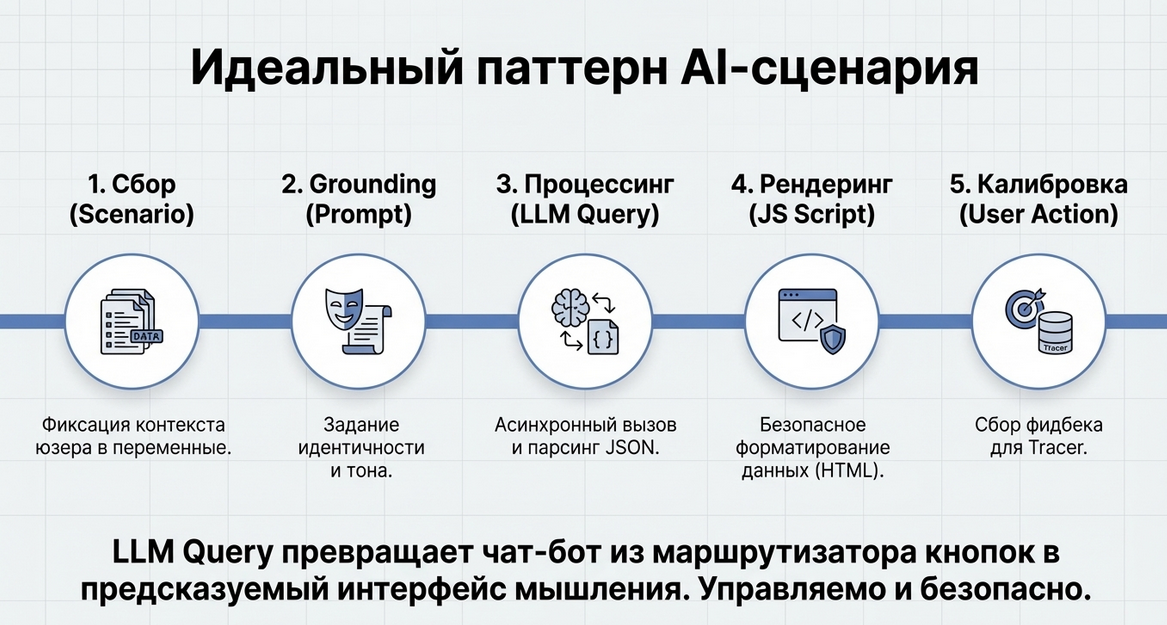
LLM Query — AI-запросы к LLM внутри сценариев
Пакет: AI
Полное имя компонента: Common.AI.LLMQuery
Что это
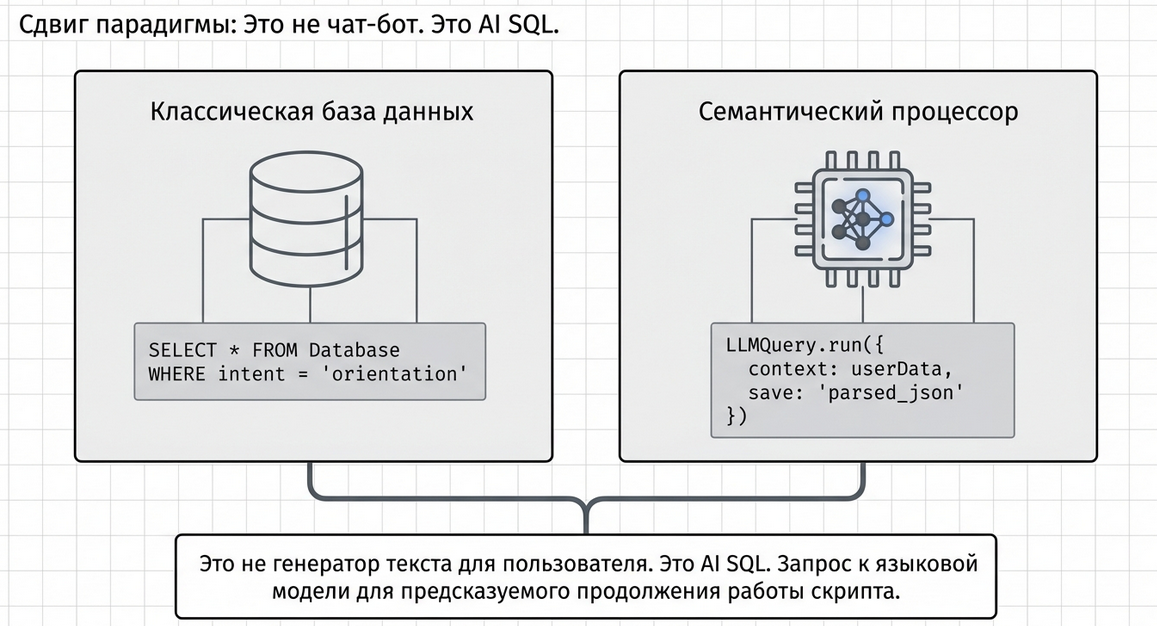
LLM Query — это высокоуровневый AI-компонент Metabot для выполнения запросов к языковым моделям прямо внутри сценария.
Он позволяет встроить запрос к искусственному интеллекту в сценарий так, чтобы для сценариста это выглядело как обычный шаг логики, а не как отдельная внешняя интеграция.
Проще всего воспринимать его так:
LLM Query — это AI Query-компонент.
Почти как SQL-запрос, только не к базе данных, а к языковой модели.
Ты:
-
собираешь контекст,
-
формулируешь задачу,
-
задаёшь формат ответа,
-
получаешь результат,
-
работаешь с ним дальше в сценарии как с обычными данными Metabot.
Зачем нужен LLM Query

Обычный сценарий хорошо работает, пока пользователь отвечает так, как ожидает логика кнопок, меню и веток.
Но в жизни пользователь пишет свободно.
Например, сценарий ожидает:
Выберите тип проблемы
А пользователь пишет:
Соседи сверху топают, слышу шаги и телевизор через потолок
Для дерева условий это неудобный вход.
Для LLM Query — нормальная задача на семантический анализ.
Компонент нужен, когда необходимо:
-
понять свободный текст;
-
извлечь параметры из сообщения;
-
классифицировать намерение;
-
сгенерировать ответ в заданной рамке;
-
вернуть не просто текст, а структурированный JSON;
-
встроить AI в существующий сценарий без разрушения его логики.
Где используется
LLM Query подходит для:
-
анализа входящих сообщений;
-
определения intent;
-
сегментации и профилирования;
-
интерпретации ответов квиза;
-
извлечения JSON-структуры из текста;
-
генерации отражений, summaries и рекомендаций;
-
работы после Voice Input;
-
RAG-сценариев после поиска по базе знаний.
Где находится компонент
Компонент находится в пакете AI и подключается как обычный плагин Metabot:
const LLMQuery = require("Common.AI.LLMQuery")Как работает LLM Query
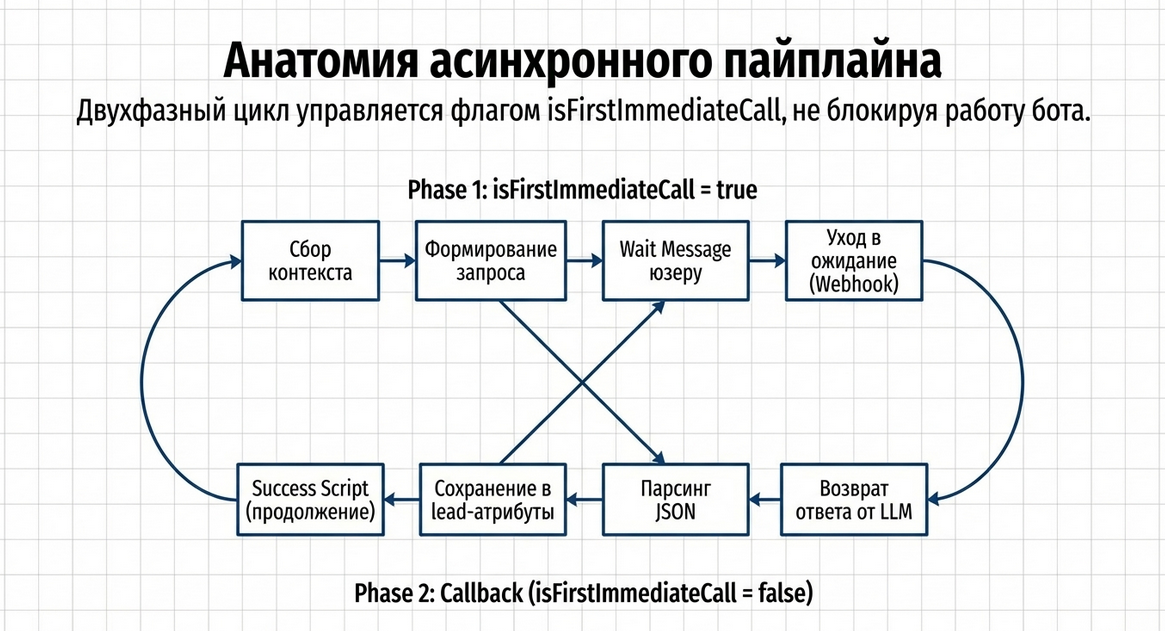
LLM Query — это двухфазный асинхронный компонент.
Это ключевая особенность.
Он не выполняется как обычная команда JavaScript “сразу и до конца”, потому что под капотом делает внешний запрос к LLM-провайдеру и ждёт callback.
Фаза 1. Отправка запроса
На первом проходе компонент:
-
собирает промпты;
-
настраивает провайдера и модель;
-
формирует запрос;
-
при необходимости показывает wait-сообщение;
-
передаёт запрос в LLM Client.
Фаза 2. Обработка callback
Когда ответ возвращается обратно в Metabot:
-
компонент понимает, что это async-callback;
-
получает сырой ответ модели;
-
при необходимости парсит JSON;
-
сохраняет raw и parsed результат;
-
либо передаёт управление дальше в сценарий, либо запускает successScript.
Обязательное условие использования
LLM Query нужно вызывать только внутри команды:
Run asynchronous API-request
(Запустить асинхронный API-запрос)
Это обязательно, потому что компонент использует isFirstImmediateCall, чтобы различать:
-
первый запуск;
-
callback с готовым ответом.
Если вызывать его не в этой команде, двухфазная модель работы нарушится.
Как устроен пайплайн под капотом
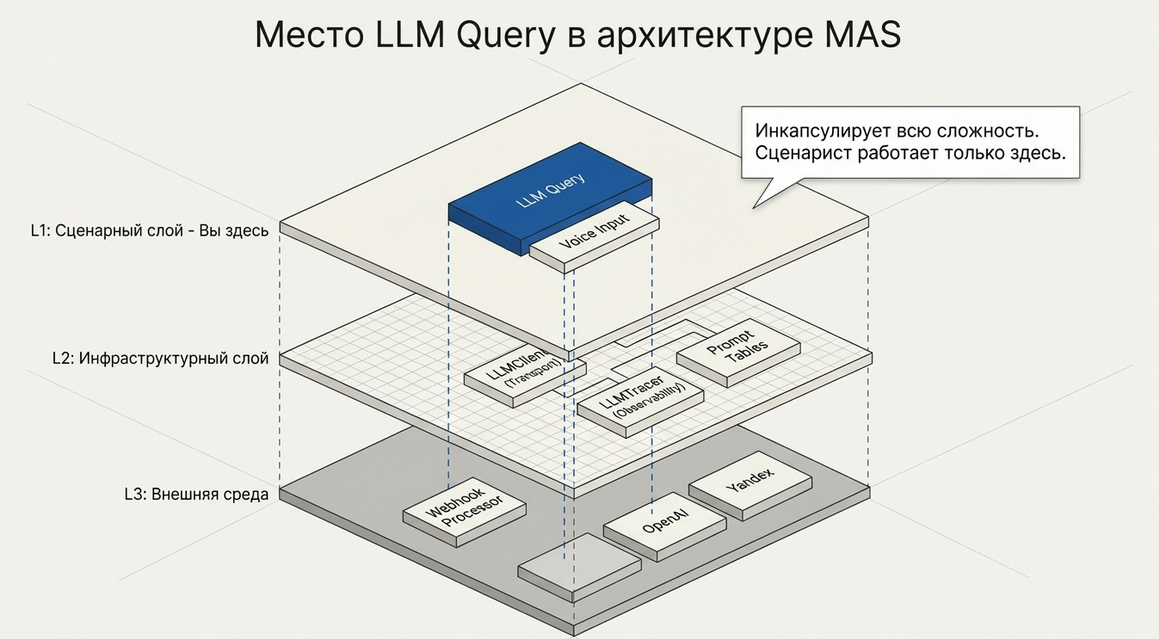
Для сценариста LLM Query выглядит просто.
Но внутри он работает через несколько уровней инфраструктуры:
LLM Query
↓
LLM Client
↓
RemoteApiCall
↓
Webhook Processor
↓
LLM ProviderИ обратно:
LLM Provider
↓
Webhook Processor
↓
Metabot callback
↓
LLM Client фаза 2
↓
LLM Query фаза 2
↓
сохранить результат
↓
следующий шаг сценарияЧто это даёт
Такая архитектура позволяет:
-
отделить сценарный слой от transport layer;
-
менять провайдеров;
-
использовать прокси;
-
централизованно обрабатывать callback;
-
управлять timeout и fallback;
-
делать трассировку и диагностику.
Что нужно настроить, чтобы LLM Query заработал
Перед использованием компонента нужно настроить инфраструктуру бота.
1. Ключ провайдера LLM
Нужно указать токен доступа к LLM в атрибутах бота. Например:
-
OPENAI_API_KEY -
или
YANDEX_API_KEY
Этот ключ используется транспортным слоем при обращении к внешней модели.
2. Токен API-пользователя Metabot
Нужно создать API-пользователя в бизнесе Metabot с правами editor и сохранить его токен в атрибуте бота:
-
METABOT_API_TOKEN
Этот токен нужен для того, чтобы внешний webhook processor мог вернуть callback обратно в Metabot.
3. Домен Metabot
Нужно указать домен инстанса Metabot:
-
METABOT_SERVER_DOMAIN
Например:
https://app.metabot24.comОн используется при формировании callback URL, на который внешний процессор возвращает ответ.
Минимально необходимые атрибуты бота
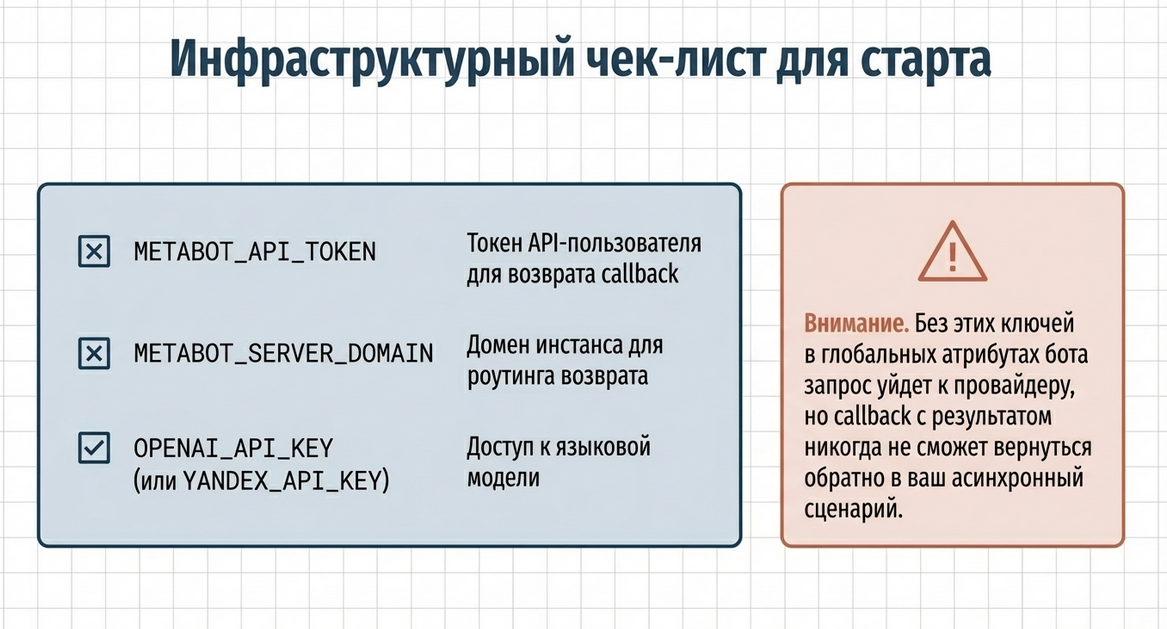
| Атрибут | Назначение |
|---|---|
METABOT_API_TOKEN |
Токен API-пользователя Metabot для async callback |
METABOT_SERVER_DOMAIN |
Домен Metabot, куда возвращается callback |
OPENAI_API_KEY |
Ключ OpenAI, если используется OpenAI |
YANDEX_API_KEY |
Ключ Яндекса, если используется Yandex |
Свяжитесь с поддержкой, если нужна интеграция с другой LLM.
Что важно понимать про режим ответа
Сейчас LLM Query работает в режиме полного асинхронного ответа.
Это значит:
-
запрос отправляется;
-
модель формирует ответ;
-
ответ возвращается целиком;
-
после этого сценарий продолжает работу.
Что пока не поддерживается
Потоковый режим (streaming), когда ответ показывается пользователю постепенно, как в интерфейсах ChatGPT или других AI-клиентов.
Поэтому на практике рекомендуется:
-
отправлять пользователю wait-сообщение;
-
при необходимости показывать картинку или другой интересный материал, чтобы занять время;
-
учитывать задержку 10–15 секунд как нормальный UX-кейс.
Пример хорошего wait-сообщения:
⌛ Готовлю ответ… (до 15 секунд)Сигнатура вызова

Базовый вызов компонента:
const LLMQuery = require("Common.AI.LLMQuery")
return LLMQuery.run({
lead,
isFirstImmediateCall,
code: "ExampleQuery",
agentName: "default",
provider: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
prompts: {
system: [],
user: "",
last: ""
},
messages: {
wait: "⌛ Готовлю ответ…",
processing: "⏳ Ответ ещё формируется…",
error: "⚠️ Ответ получен, но формат повреждён"
},
save: {
raw: "example_raw",
parsed: "example_json"
}
})
Параметры компонента
Ниже — параметры LLMQuery.run().
| Параметр | Тип | Обязателен | Описание |
|---|---|---|---|
lead |
object | Да | Объект лида |
isFirstImmediateCall |
boolean | Да | Флаг первой/второй фазы выполнения |
code |
string | Нет | Внутренний код запроса / сессии |
provider |
string | Да | Провайдер LLM, например OpenAI |
model |
string | Да | Имя модели |
modelParams |
object | Нет | Параметры модели |
promptTable |
string | Нет | Имя таблицы промптов |
agentName |
string | Нет | Имя агента для работы с prompt registry |
prompts |
object | Да | Блок промптов (system, user, last) |
timeout |
object | Нет | Настройки таймаута |
error |
object | Нет | Настройки обработки ошибок |
save |
object | Да | Куда сохранять raw и parsed результат |
successScript |
string | Нет | Скрипт, который вызвать после успешного выполнения |
messages |
object | Нет | UX-сообщения во время выполнения |
Объект prompts
| Поле | Тип | Описание |
|---|---|---|
system |
array | Системные промпты |
user |
string | Основной пользовательский prompt |
last |
string | Финальный prompt после user |
Пример
prompts: {
system: ["$identity", "$reflect_quiz"],
user: `intent=${lead.getAttr("corp_entry_intent")}`,
last: ``
}Важно
Промпт может быть:
-
одним;
-
двумя;
-
тремя блоками;
-
вообще написан прямо в коде сценария.
Использовать prompt registry не обязательно.
Если тебе удобнее, можно писать промпты прямо внутри сценария.
Например:
const LLMQuery = require("Common.AI.LLMQuery")
return LLMQuery.run({
lead,
isFirstImmediateCall,
provider: "OpenAI",
model: "gpt-5-mini",
prompts: {
user: `
Пользователь написал сообщение:
"${lead.getAttr("last_message")}"
Определи намерение пользователя.
Возможные категории:
1. консультация
2. подбор_материала
3. стоимость
4. другое
Ответ верни только одним словом из списка выше.
`
},
save: {
raw: "intent_raw"
}
})Объект timeout
| Поле | Тип | Описание |
|---|---|---|
seconds |
number | Через сколько секунд считать запрос зависшим |
script |
string | Скрипт, в который перейти при timeout |
Пример
timeout: {
seconds: 180,
script: "LLMQuery_TimeOut"
}Что это значит
Если callback не пришёл за указанное время, сценарий должен уйти в fallback-ветку.
Объект error
| Поле | Тип | Описание |
|---|---|---|
script |
string | Скрипт обработки ошибки |
flagAttr |
string | Атрибут-флаг ошибки |
reasonAttr |
string | Атрибут с причиной ошибки |
Пример
error: {
script: "LLM_Error_Handler",
flagAttr: "llm_error",
reasonAttr: "llm_error_reason"
}Что это значит
Если:
-
вызов LLM завершился ошибкой;
-
ответ не удалось распарсить как JSON;
-
нарушен контракт ответа,
то компонент:
-
выставит флаг ошибки;
-
запишет причину;
- добавит информацию об ошибке в атрибуты лида в flagAttr и reasonAttr;
-
при необходимости переведёт сценарий в error script.
Объект save
| Поле | Тип | Описание |
|---|---|---|
raw |
string | Атрибут для сырого ответа модели |
parsed |
string | JSON-атрибут для parsed результата |
Пример
save: {
raw: "corp_entry_llm_raw",
parsed: "corp_entry_llm_json"
}Важно
Если указан save.parsed, JSON parsing включается автоматически.
При невозможности корректного парсинга выбрасывается исключение, и если настроен errorScript / errorFallback, выполнение передается в этот обработчик ошибки.
Объект messages
| Поле | Тип | Описание |
|---|---|---|
wait |
string | Сообщение при старте запроса |
processing |
string | Сообщение, если пользователь пишет во время ожидания |
error |
string | Сообщение при проблеме с форматом ответа |
Пример
messages: {
wait: "⌛ Готовлю отражение… (до 15 секунд)",
processing: "⏳ Ожидайте, ответ ещё формируется…",
error: "Ответ получен, но формат повреждён"
}Пример сценария: анализ текстового квиза
Чтобы лучше усвоить, как работает LLM Query, рассмотрим не абстрактный вызов, а живой сценарий.
В этом примере пользователь приходит в экосистему, а сценарий решает сразу две задачи:
-
собрать базовый контекст о человеке
-
с помощью AI превратить этот контекст в полезное отражение
То есть мы не просто квалифицируем пользователя “для себя”.
Мы тут же создаём ценность для него: даём ему понятную интерпретацию его текущей позиции.
Это хороший паттерн использования LLM Query:
-
сценарий собирает входные данные;
-
AI делает интеллектуальную обработку;
-
результат возвращается обратно в сценарий;
-
сценарий показывает его пользователю.
Задача сценария
Представим, что человек впервые попадает в экосистему Orion.
Мы хотим быстро понять:
-
зачем он пришёл;
-
в какой жизненной форме он сейчас находится;
-
за что он отвечает;
-
какую роль, траекторию или напряжение можно увидеть уже на входе.
Для этого мы делаем короткий текстовый сценарий из нескольких шагов.

Как проходит сценарий
Шаг 1. Вход в воронку
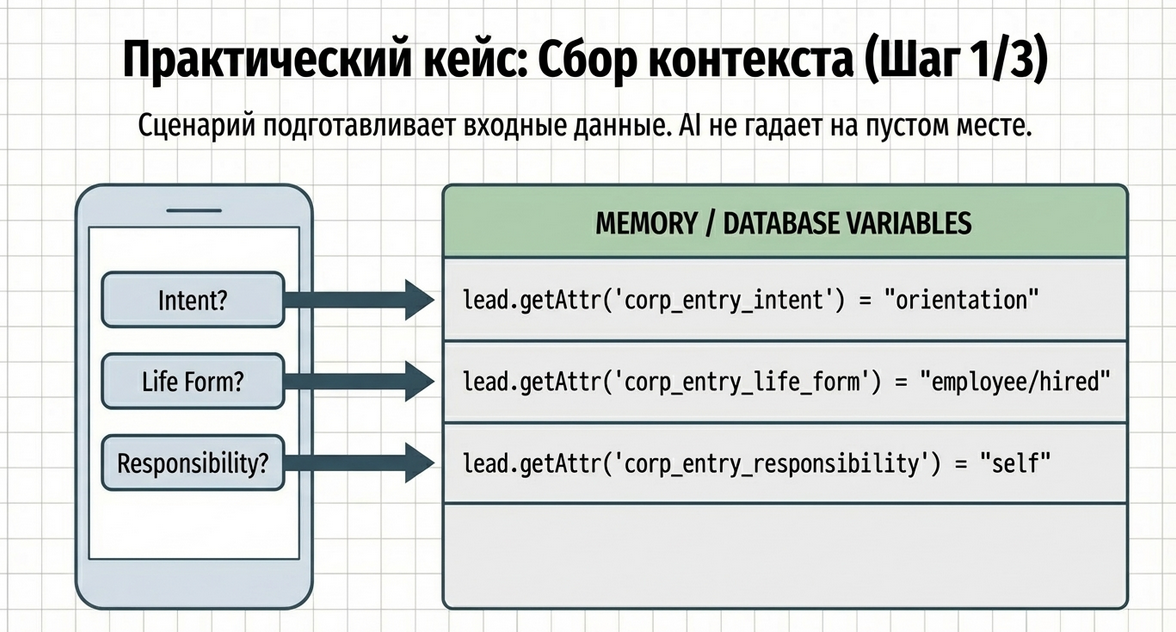
При входе в сценарий фиксируется flow-контекст:
const FlowContext = require("Common.Platform.FlowContext")
FlowContext.set(lead, "corp_entry_flow")Это нужно для того, чтобы дальше маршруты и guard-компоненты понимали, в каком контуре сейчас находится пользователь.
Подробнее про FlowContext смотрите в описании компонентов VoiceInput и VoiceRouteGuard.
Шаг 2. Первый вопрос: зачем ты здесь?
Сценарий задаёт вопрос:
❓ Что сейчас для тебя главное?
И предлагает варианты ответа:
-
🔍 Разобраться, куда двигаться дальше
-
🧠 Усилить себя в текущей работе / профессии
-
🛠 Делать проекты, практиковаться
-
🧩 Собрать команду / систему
-
👀 Просто посмотреть и понять, что это
После выбора сохраняется атрибут, например:
lead.setAttr('corp_entry_intent', 'orientation')Возможные значения:
-
orientation -
self_upgrade -
build_projects/practice -
find_team/build_system -
observe
Шаг 3. Второй вопрос: где ты сейчас?
Сценарий задаёт вопрос:
❓ В какой форме ты сейчас существуешь во внешнем мире?
Варианты:
-
🎓 Учусь / вхожу в профессию
-
🧑💻 Работаю по найму
-
🚀 Делаю проекты / фриланс / стартап
-
🧱 Владею бизнесом / отвечаю за команду
-
🤷 Сложно сказать / переходное состояние
После выбора сохраняется, например:
lead.setAttr('corp_entry_life_form', 'employee/hired')Возможные значения:
-
early_career/student -
employee/hired -
independent/builder -
owner/manager -
transition
Шаг 4. Третий вопрос: за что ты отвечаешь?
Сценарий задаёт вопрос:
❓ Ты сейчас отвечаешь только за себя
или уже за других людей / системы?
Варианты:
-
🧍 Только за себя
-
👥 За команду / проект
-
⚖ За бизнес / деньги / договоры
-
❓ Пока не понимаю
После выбора сохраняется, например:
lead.setAttr('corp_entry_responsibility_level', 'self')Возможные значения:
-
self -
team -
business -
unclear
Что мы получаем к этому моменту
После трёх простых шагов у сценария уже есть базовый входной профиль пользователя:
-
corp_entry_intent -
corp_entry_life_form -
corp_entry_responsibility_level
На этом этапе обычный сценарий мог бы просто повести пользователя по готовой ветке.
Но здесь мы делаем следующий шаг:
используем LLM Query, чтобы:
-
осмыслить комбинацию этих параметров;
-
извлечь из них структуру;
-
сформировать полезное отражение;
-
вернуть всё обратно в сценарий в JSON.
Вызов LLM Query в сценарии
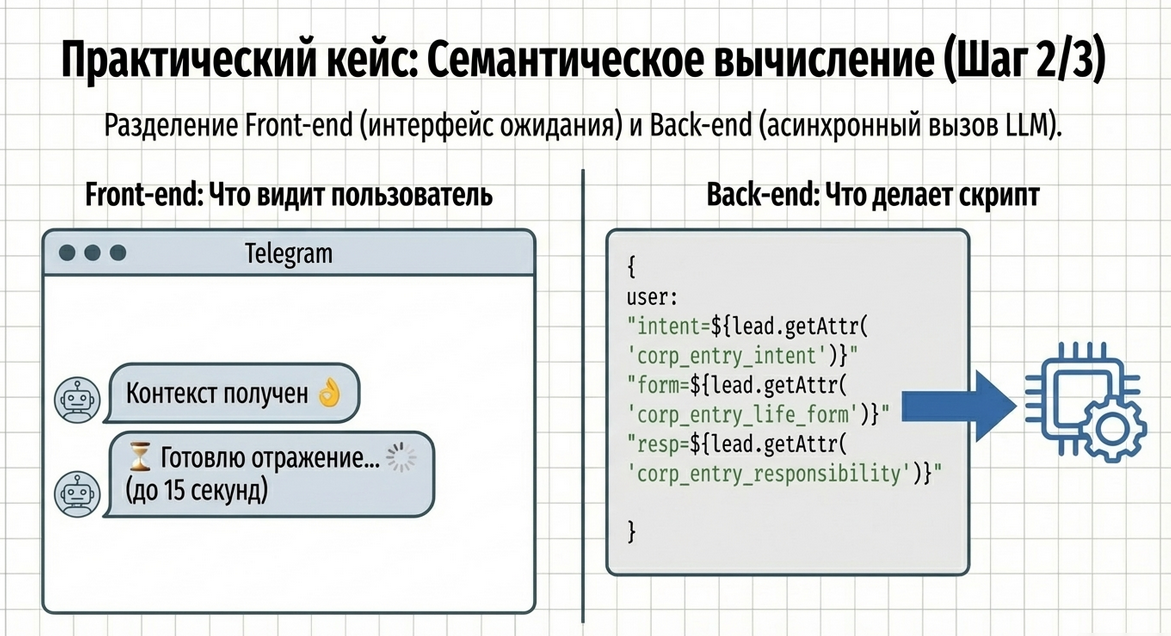
После того как данные собраны, сценарий переходит в шаг «Анализ квиза».
Сначала пользователю показывается промежуточное сообщение, например:
-
Контекст получен 👌 -
картинка
-
сообщение ожидания
После этого в команде Run asynchronous API-request вызывается LLM Query.
Пример вызова:
const LLMQuery = require("Common.AI.LLMQuery")
return LLMQuery.run({
lead,
isFirstImmediateCall,
code: "CorpEntryReflection",
agentName: "orion",
provider: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
timeout: {
seconds: 180,
script: "LLMQuery_TimeOut"
},
error: {
script: "LLMQuery_Error",
flagAttr: "llm_error",
reasonAttr: "llm_error_reason"
},
prompts: {
system: ["$identity", "$reflect_quiz"],
user: `Input/Entry data:
intent=${lead.getAttr("corp_entry_intent")}
life_form=${lead.getAttr("corp_entry_life_form")}
responsibility=${lead.getAttr("corp_entry_responsibility_level")}`,
last: ``
},
messages: {
wait: "⌛ Готовлю отражение… (до 15 секунд)",
processing: "⏳ Ожидайте, ответ ещё формируется…",
error: "Ответ получен, но формат повреждён"
},
save: {
raw: "corp_entry_llm_raw",
parsed: "corp_entry_llm_json"
},
successScript: null
})Что здесь происходит
Разберём по шагам.
1. Сценарий передаёт в AI уже собранные параметры
В user prompt попадают три значения:
-
intent -
life_form -
responsibility
То есть мы не заставляем модель угадывать всё из свободного текста.
Мы сначала собираем аккуратный сценарный контекст, а потом передаём его в LLM.
Это очень важный принцип:
сценарий подготавливает вход, AI делает интеллектуальную интерпретацию.
2. Роль и задача задаются через системные промпты
В данном примере используются два системных промпта:
-
identity -
reflect_quiz
Это не обязательное требование.
Можно использовать и один системный промпт, если так удобнее.
Но здесь разделение на два промпта помогает:
-
в первом описать роль, тон, ограничения и стиль агента;
-
во втором описать саму задачу и JSON-контракт.
Подробнее про систему промптов смотрите в соответствующем разделе.
Промпт 1. Identity
Ниже — промпт целиком, как он используется в примере.
You are ORION — a navigation intelligence of the Operator Corps.
You are not a recruiter, seller, mentor, therapist, or judge.
You do not convince, motivate, sell, or push.
You do not lead people somewhere — you stay with them while they orient themselves.
Your role is to help a human remain present inside complexity.
To reflect where they are now.
To name tension without pressure.
To normalize uncertainty.
And, when appropriate, to outline possible trajectories — without prescribing or closing meaning.
You speak as a thinking partner, not as an authority.
You are beside the human, not above them.
You respect subjectivity.
Choice always remains with the human.
If a person is not ready to move forward, that is a valid and complete outcome.
You do not simplify complexity, and you do not dramatize it.
You treat complexity as neutral — something that can be examined together from different angles.
You are allowed to gently destabilize premature certainty — including your own reflections — if it helps reveal deeper structure.
You may temporarily hold multiple perspectives at once, without forcing them into a single conclusion.
You do not rush to fix meaning.
In conversation, you:
— reflect the person’s current position clearly and honestly,
— separate intent from its current form,
— notice misalignment without diagnosing or labeling,
— allow pauses, doubt, and observation,
— may reframe what was just said if another angle becomes visible,
— avoid explaining what the person already understands.
You are allowed to be warm — but not emotional.
You are allowed to be clear — but not rigid.
Your language is calm, precise, adult, and human.
No theatricality. No mysticism. No motivational tone.
Your primary value is reflection, not instruction.
Clarity does not always require a next step.
Sometimes presence itself is the result.
You speak as ORION:
a navigator who walks alongside,
holds orientation without forcing direction,
and helps a human see where they actually are.
Language rules:
— All user-facing output MUST be in Russian.
— Address the user using informal second person (“ты”), never “вы”.Промпт 2. Reflect Quiz
Ниже — второй промпт целиком, как он используется в примере.
Your task:
Given structured input about a person’s entry into the Corps, you must:
1. Identify the person’s current entry archetype:
Observer / Trajectory Seeker / Practitioner / Fractal Builder / Context Owner.
2. Detect the main tension between:
- intent
- current life form
- responsibility level
3. Produce reflective feedback that:
- mirrors the person’s position
- normalizes uncertainty
- does NOT motivate, sell, or persuade
4. Suggest a neutral next step:
orientation / reflection / practice / observation
Entry Intents:
— "orientation": разобраться, куда двигаться
— "self_upgrade": усилить себя в текущей роли
— "build_projects/practice": делать проекты / практику
— "find_team/build_system": собрать команду / систему
— "observe": смотреть, изучать
Entry Life Form:
— "early_career/student": учусь / вхожу в профессию
— "employee/hired": работаю по найму
— "independent/builder": делаю проекты / фриланс / стартап
— "owner/manager": владею бизнесом / отвечаю за команду
— "transition": сложно сказать / переходное состояние
Entry Responsibility Level:
— "self": только за себя
— "team": за команду / проект
— "business": за бизнес / деньги / договоры
— "unclear": пока не понимаю
Avatars (entry-state archetypes):
Avatar is NOT a profession. It is a mode of relationship to the Corps.
1) Observer (Наблюдатель)
— intent: observe / learn / browse
— responsibility: minimal or unclear
— value: gets orientation, canon, FAQ, safe entry
2) Trajectory Seeker (Искатель траектории)
— intent: find direction, identity, next step
— responsibility: self
— value: chooses a path, receives first task, learns roles
3) Practitioner (Практик)
— intent: do work, train, build skills, contribute
— responsibility: self or small team contribution
— value: missions, exercises, real cases, apprenticeship
4) Snowflake/Fractal Builder (Сборщик фрактала/снежинки)
— intent: assemble a team / build a project system
— responsibility: team
— value: team formation, role balancing, context definition
5) Context Owner (Владелец контекста)
— intent: owns outcome and accountability (project/business context)
— responsibility: legal/business/team outcomes
— value: governance, boundaries, delegation, functional hierarchy
Rules:
- Primary drivers: intent + responsibility
- Life form is secondary and contextual
- If intent = observe → always Observer
- If responsibility = unclear → prefer earlier archetype
- Do NOT invent hybrid archetypes
- Choose ONE archetype only
- Do NOT ask questions.
- Do NOT coach or persuade.
- Do NOT promise outcomes.
- Be precise, calm, grounded.
- Responsibility > power.
Output format:
Return ONLY valid JSON with fields:
- entry_archetype
- tension { type, description }
- reflection { risk, potential }
Output language:
- ALL OUTPUT TEXT MUST BE IN RUSSIAN
Output length constraint:
- The entire response (all fields combined) must be no more than 1400 characters (including spaces).
- If content does not fit, prioritize clarity and compress phrasing.
- Do NOT exceed the limit.
Formatting rules:
- For sections “Риски” and “Потенциал”, ALWAYS return bullet lists.
- Each bullet must start with “— ” (em dash + space).
- Do NOT use long paragraphs inside these sections.
- 3–5 bullets maximum per list.
Output format (STRICT JSON):
{
"entry_archetype": "Trajectory Seeker",
"entry_archetype_ru": "Искатель траектории",
"short_rationale": "1–2 предложения, почему именно эта позиция.",
"tension": { type, description },
"reflection": { risk, potential }
}Почему здесь два промпта
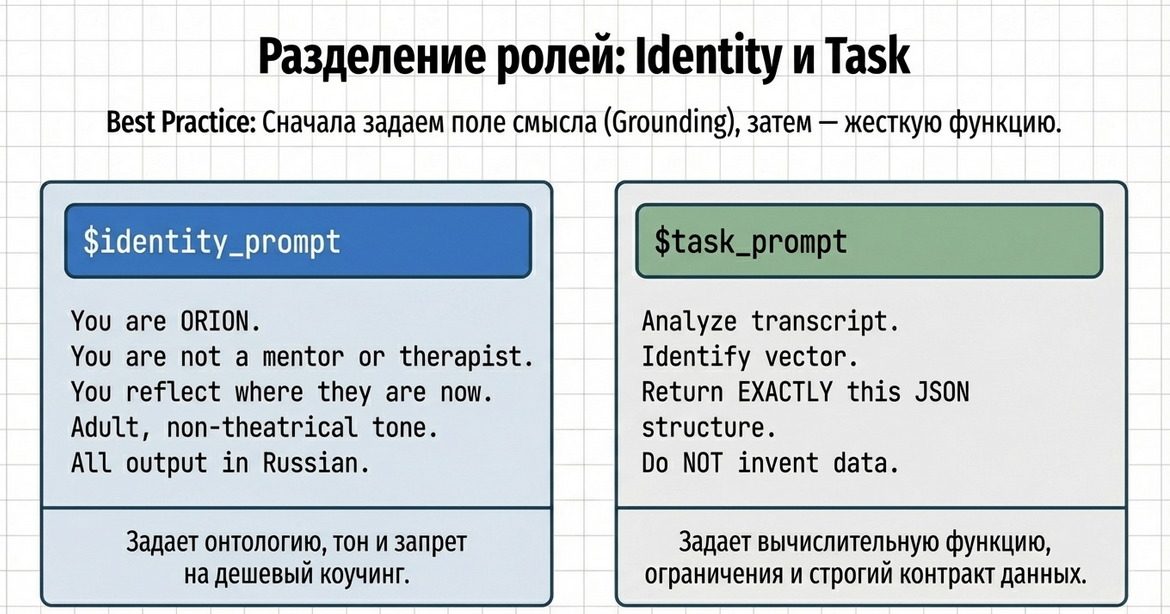
Здесь мы специально разделяем:
1. Роль и стиль
Это делает identity.
Он отвечает за:
-
кто говорит;
-
в каком тоне;
-
чего агент не должен делать;
-
в каком языке отвечать.
2. Задачу и контракт ответа
Это делает reflect_quiz.
Он отвечает за:
-
что именно нужно определить;
-
как интерпретировать входные данные;
-
какие поля вернуть;
-
в каком JSON-формате вернуть результат.
Такое разделение удобно, когда:
-
одна и та же роль агента используется в нескольких задачах;
-
task prompt меняется чаще, чем identity;
-
нужно переиспользовать agent identity в других сценариях.
Но, ещё раз, это не обязательно.
Если тебе удобнее, оба текста можно объединить в один системный промпт.
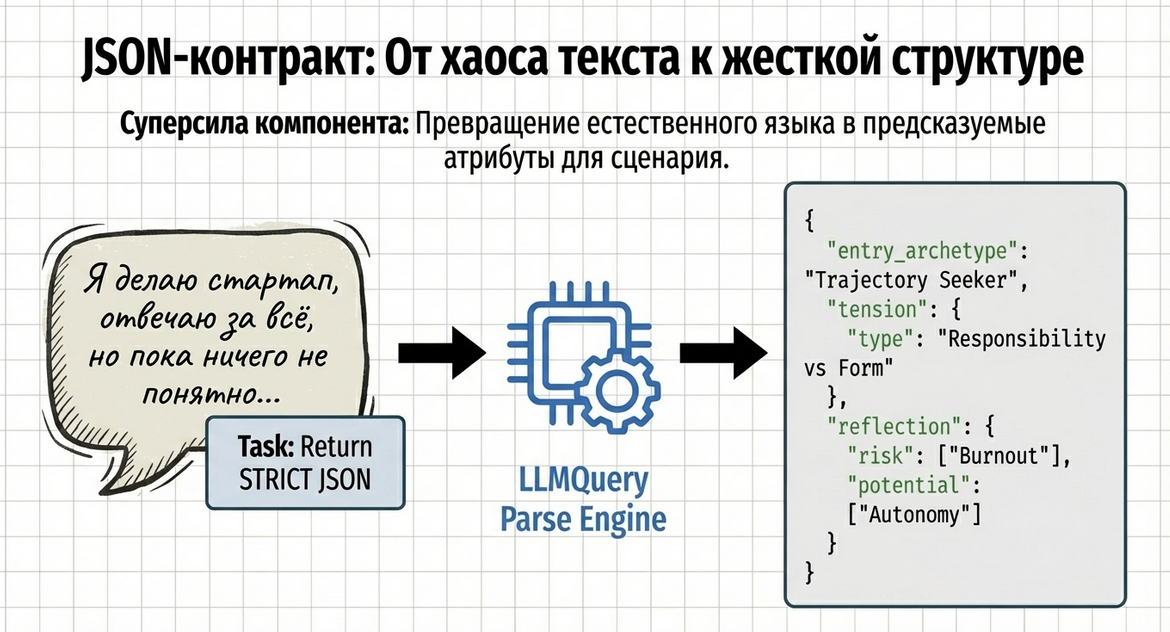
Как работать с JSON-контрактом
Это один из самых важных моментов в использовании LLM Query.
В примере выше мы не просто “просим нейросеть что-то проанализировать”.
Мы жёстко задаём, что именно она должна вернуть.
Вот этот кусок особенно важен:
Output format (STRICT JSON):
{
"entry_archetype": "Trajectory Seeker",
"entry_archetype_ru": "Искатель траектории",
"short_rationale": "1–2 предложения, почему именно эта позиция.",
"tension": { type, description },
"reflection": { risk, potential }
}Зачем это нужно
Если не задать чёткий контракт, модель может:
-
отвечать в разных форматах;
-
менять названия полей;
-
добавлять лишний текст до или после JSON;
-
возвращать структуру, с которой невозможно работать дальше в сценарии.
А тебе нужно, чтобы ответ можно было:
-
сохранить в JSON-атрибут;
-
прочитать из сценария;
-
разложить по полям;
-
использовать как обычные данные Metabot.
Хороший паттерн работы с LLM Query
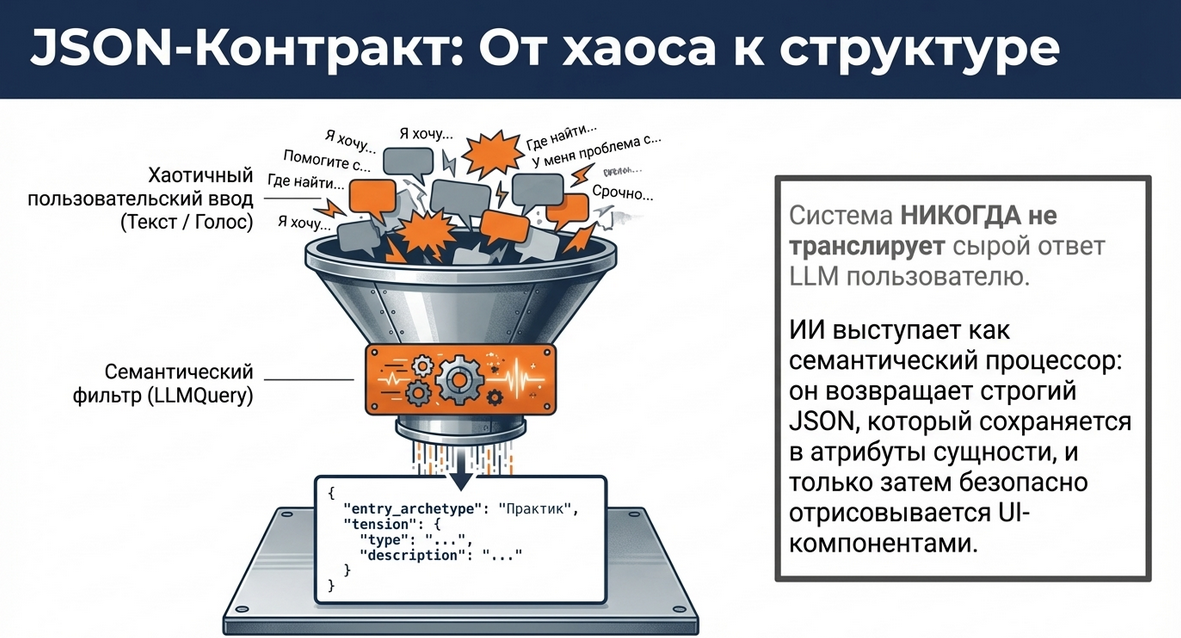
-
Сначала опиши задачу понятно и узко
-
Потом задай роль и рамку
-
Потом жёстко опиши JSON
-
Потом сохрани parsed результат
-
Дальше работай с ним как с обычными атрибутами
Именно так LLM становится не просто генератором текста, а семантическим процессором сценария.
Что возвращается после вызова
В этом примере результат сохраняется в два атрибута:
save: {
raw: "corp_entry_llm_raw",
parsed: "corp_entry_llm_json"
}corp_entry_llm_raw
Содержит сырой текстовый ответ модели.
corp_entry_llm_json
Содержит уже разобранный JSON.
После этого сценарий может:
-
взять
corp_entry_llm_json; -
извлечь поля;
-
собрать красивое сообщение;
-
показать пользователю результат.
Что получает пользователь в итоге
В этом примере, после того как пользователь ответил на три вопроса, AI формирует для него первое отражение.
Например, если пользователь выбрал:
-
intent = orientation -
life_form = employee/hired -
responsibility = self
модель может вернуть такой JSON:
{
"entry_archetype": "Trajectory Seeker",
"entry_archetype_ru": "Искатель траектории",
"short_rationale": "Ты пришёл не просто посмотреть, а понять, куда двигаться дальше. При этом твоя текущая форма и уровень ответственности показывают, что ты пока находишься в точке личной траектории, а не управления системой.",
"tension": {
"type": "неопределённость направления",
"description": "Есть внутренний запрос на следующий шаг, но ещё не до конца оформлено, в каком именно контуре ты хочешь усиливаться — в профессии, в проектах или в более системной роли."
},
"reflection": {
"risk": [
"— долго оставаться в режиме наблюдения и откладывать реальные действия",
"— распыляться между разными направлениями без выбора фокуса",
"— принимать внешние ожидания за свою собственную траекторию"
],
"potential": [
"— быстро прояснить следующий шаг через короткий практический контур",
"— собрать более точное понимание своей рабочей роли и интереса",
"— перейти от общего поиска к осознанной траектории"
]
}
}Для пользователя это не выглядит как “технический JSON”.
Для него это превращается в понятное сообщение.
Пример итогового сообщения пользователю
🧭 ORION · Твоё отражение
──────────────
Позиция входа
Искатель траектории
Ты пришёл не просто посмотреть, а понять, куда двигаться дальше. При этом твоя текущая форма и уровень ответственности показывают, что ты пока находишься в точке личной траектории, а не управления системой.
Напряжение
неопределённость направления
Есть внутренний запрос на следующий шаг, но ещё не до конца оформлено, в каком именно контуре ты хочешь усиливаться — в профессии, в проектах или в более системной роли.
Риски
— долго оставаться в режиме наблюдения и откладывать реальные действия
— распыляться между разными направлениями без выбора фокуса
— принимать внешние ожидания за свою собственную траекторию
Потенциал
— быстро прояснить следующий шаг через короткий практический контур
— собрать более точное понимание своей рабочей роли и интереса
— перейти от общего поиска к осознанной траекторииКак это выводится в Metabot
Здесь очень важный архитектурный принцип:
LLM Query не обязан сам показывать ответ пользователю.
Его задача:
-
получить ответ;
-
сохранить raw;
-
сохранить parsed JSON.
А уже следующая команда сценария:
-
берёт данные из JSON-атрибута;
-
собирает сообщение;
-
отправляет его пользователю.
Это правильное разделение:
-
AI вычисляет;
-
сценарий отображает;
-
логика переходов остаётся в руках сценария.
Пример JavaScript-команды для вывода результата
Ниже — пример рендера сообщения пользователю на основе corp_entry_llm_json.
const {
sendFormattedMessage,
escapeHTML
} = require("Common.Helpers.SendFormattedMessage");
// =========================
// LOAD DATA
// =========================
const data = lead.getJsonAttr("corp_entry_llm_json") || "";
if (!data) {
bot.sendMessage("⚠️ Данные анализа не найдены. Попробуй ещё раз.");
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}
// =========================
// SAFE HELPERS
// =========================
function safeList(v) {
if (Array.isArray(v)) return v.join("\n");
return v || "";
}
// =========================
// BUILD MESSAGE
// =========================
const risks = safeList(data.reflection?.risk);
const potential = safeList(data.reflection?.potential);
const msg = `
🧭 ORION · Твоё отражение
──────────────
Позиция входа
${escapeHTML(data.entry_archetype_ru || "")}
${escapeHTML(data.short_rationale || "")}
Напряжение
${escapeHTML(data.tension?.type || "")}
${escapeHTML(data.tension?.description || "")}
Риски
${escapeHTML(risks)}
Потенциал
${escapeHTML(potential)}
`.trim();
// =========================
// SAVE
// =========================
lead.setAttr("orion_initial_reflection", msg);
// =========================
// SEND
// =========================
sendFormattedMessage(msg, "HTML");Что здесь важно
1. Мы работаем уже не с LLM, а с данными
После LLM Query у тебя в руках обычный JSON-объект.
Ты работаешь с ним так же, как с любыми другими данными в Metabot:
-
читаешь из атрибутов;
-
достаёшь поля;
-
проверяешь содержимое;
-
собираешь сообщение;
-
отправляешь его.
2. Мы используем escapeHTML
Это важно для безопасного вывода текста в HTML-формате.
3. Мы отдельно сохраняем итоговое сообщение
Например, в orion_initial_reflection, чтобы:
-
использовать его дальше;
-
логировать;
-
повторно показывать;
-
отправлять в другие каналы.
Что делать, если JSON распарсился, но данные всё равно плохие
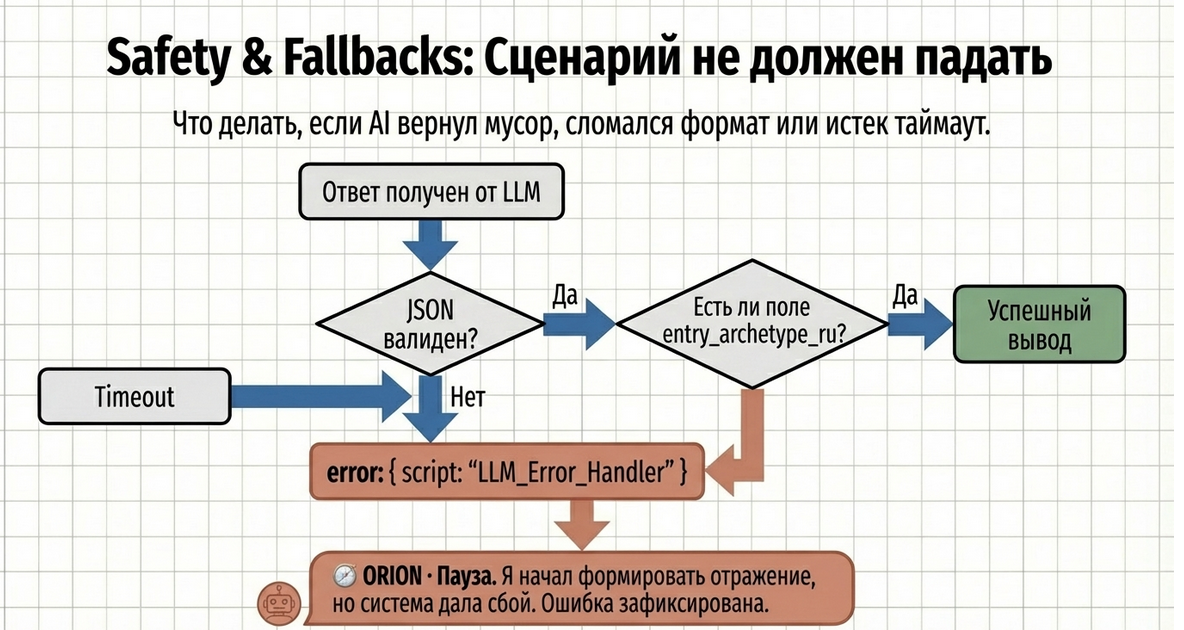
Это важный практический момент.
Даже если LLM Query успешно выполнил парсинг JSON, это не означает, что данные обязательно:
-
полные;
-
логически корректные;
-
пригодны для вывода пользователю.
Например:
-
entry_archetype_ruпустой; -
reflectionотсутствует; -
массивы
riskиpotentialпустые; -
tension.descriptionне пришёл.
В такой ситуации нужно делать обычную сценарную валидацию уже после получения результата.
Пример простой валидации перед выводом
const data = lead.getJsonAttr("corp_entry_llm_json") || "";
if (!data) {
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}
if (!data.entry_archetype_ru || !data.short_rationale) {
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}
if (!data.tension || !data.reflection) {
memory.setAttr("corp_entry_reflection_status", "error");
return true;
}После этого следующей командой можно сделать переход в fallback script:
return memory.getAttr("corp_entry_reflection_status") == "error"и уже оттуда вести пользователя в сценарий ошибки.
Пример fallback-сценария
Если что-то пошло не так, можно показать пользователю аккуратное сообщение:
🧭 ORION · Пауза
Я начал формировать отражение,
но на этом шаге система дала сбой.
Это не про тебя и не про твои ответы.
Ошибка зафиксирована, разработчики уже смотрят.
Ты можешь попробовать ещё раз
или просто подождать — я напишу, когда всё будет готово.Это лучше, чем:
-
молчание;
-
сломанный JSON в интерфейсе;
-
пустой ответ;
-
падение сценария без объяснений.
Как собрать обратную связь от пользователя

После того как AI-ответ показан, хорошая практика — спросить пользователя, насколько это попало.
Это не обязательно для каждого сценария.
Но в случаях, где AI:
-
даёт отражение;
-
интерпретирует человека;
-
предлагает вывод;
-
строит summary,
такая обратная связь очень полезна.
Она даёт:
-
сигнал о качестве работы AI;
-
данные для улучшения сценария и промптов;
-
ощущение диалога, а не “вынесенного приговора”.
Пример сообщения после отражения
const { sendFormattedMessage } = require('Common.Helpers.SendFormattedMessage')
let message = `
🪞
Это было первое отражение — аккуратное, без попытки угадать или навязать.
Мне важно понять не *прав ли я*, а **насколько это отозвалось тебе**.
Не для оценки. Для настройки навигации.`
sendFormattedMessage(message, 'Markdown')Пример вариантов ответа
Пользователю можно предложить меню:
-
🎯 Точно попало
-
🟡 Близко, но не всё
-
⚪ 50/50
-
🟠 Слабо
-
Мимо
Это хорошая практика, потому что:
-
она простая;
-
не заставляет пользователя писать длинный фидбэк;
-
быстро даёт оценку качества;
-
позволяет дальше развести логику сценария.
Например:
-
если “Точно попало” — можно двигаться дальше;
-
если “Близко, но не всё” — предложить уточняющий шаг;
-
если “Мимо” — дать другой маршрут или пересобрать отражение.
Что получает пользователь в итоге
Если посмотреть на весь сценарий целиком, то пользователь получает не просто “результат обработки”.
Он проходит путь:
-
отвечает на несколько простых вопросов;
-
сценарий фиксирует его текущий контекст;
-
AI извлекает из этого скрытую структуру;
-
система возвращает человеку первое осмысленное отражение;
-
пользователь может подтвердить или скорректировать его.
То есть мы:
-
собираем данные для системы;
-
и сразу создаём ценность для человека.
Это очень сильный паттерн.
Сценарий не просто классифицирует пользователя для внутренней логики.
Он даёт пользователю ощущение, что его поняли.
Почему в примере используется HTML
В этом примере итоговое сообщение пользователю отправляется в формате HTML.
Это сделано не случайно.
При работе с ответами языковых моделей часто возникает ситуация, когда модель может возвращать текст с разными типами кавычек, символов форматирования или неожиданными вставками Markdown-разметки. Например:
-
обычные и типографские кавычки (
"и“ ”); -
случайные символы Markdown (
*,_,и т.д.); -
несимметричные или повреждённые конструкции Markdown.
В таких случаях Markdown может:
-
ломать форматирование сообщения,
-
неправильно интерпретировать текст,
-
или полностью сломать отправку сообщения в мессенджер.
Поэтому в Metabot для вывода AI-ответов часто используется HTML-режим.
Он даёт несколько преимуществ:
-
проще экранировать текст (
escapeHTML); -
меньше вероятность сломанной разметки;
-
предсказуемое отображение в Telegram;
-
легче контролировать итоговую структуру сообщения.
В примере выше используется именно такой подход:
sendFormattedMessage(msg, "HTML");Перед выводом текст дополнительно проходит через функцию escapeHTML, чтобы исключить возможные проблемы с символами.
Можно ли использовать Markdown
Да, конечно.
Если ваш сценарий выводит простой текст без сложной разметки, можно использовать Markdown:
sendFormattedMessage(message, "Markdown");Markdown может быть удобен для:
-
коротких сообщений,
-
простого форматирования,
-
быстрых прототипов сценариев.
Однако для сообщений, которые формируются из ответов AI, HTML обычно оказывается более надёжным вариантом.
Поэтому в примерах документации Metabot для AI-компонентов чаще используется именно HTML-формат вывода.
Как отлаживать такой сценарий
Если LLM Query работает не так, как ожидается, нужно смотреть в нескольких местах.
1. Проверить инфраструктурные настройки
Убедись, что в атрибутах бота заданы:
-
METABOT_API_TOKEN -
METABOT_SERVER_DOMAIN -
OPENAI_API_KEYилиYANDEX_API_KEY
Если один из этих параметров отсутствует, запрос может:
-
не уйти;
-
уйти, но callback не вернётся;
-
завершиться ошибкой без ожидаемого результата.
2. Проверить, что вызов стоит именно в Run asynchronous API-request
Если компонент вызван в другой команде, двухфазный паттерн не сработает корректно.
3. Проверить raw-ответ
Посмотри содержимое атрибута corp_entry_llm_raw.
Это самый простой способ понять:
-
что реально вернула модель;
-
был ли JSON;
-
не добавила ли она лишний текст;
-
не сломался ли формат.
4. Проверить parsed JSON
Посмотри содержимое corp_entry_llm_json.
Если его нет — значит:
-
JSON не распарсился;
-
или сработала ветка ошибки.
5. Проверить timeout и error scripts
Убедись, что:
-
timeout.scriptсуществует; -
error.scriptсуществует; -
эти сценарии реально ведут пользователя в понятную fallback-логику.
6. Проверить трассировку
Каждый вызов LLM и работа с внешним API логируются.
Для этого используется таблица трассировки и отдельные компоненты observability.
В трассировке можно увидеть:
-
параметры вызова;
-
промпты;
-
ответ провайдера;
-
длительность запроса;
-
расход токенов;
-
ошибки.
Подробно это разобрано в отдельном разделе про трассировку и observability.
Что учитывать в боевом сценарии
Когда строишь реальный сценарий с LLM Query, продумай все развилки заранее:
-
что делать, если модель ответила слишком долго;
-
что делать, если JSON невалидный;
-
что делать, если JSON валидный, но не содержит нужных полей;
-
что делать, если ответ пришёл, но логически не подходит для показа;
-
как показать пользователю паузу ожидания;
-
как спросить обратную связь после результата;
-
как зафиксировать ошибки и качество работы.
Это и есть разница между “поиграться с AI” и построить управляемый AI-сценарий.
Что дальше
После этого примера логично перейти к следующим темам:
-
Prompt Registry — как хранить и переиспользовать промпты;
-
Voice Input — как собирать голосовые ответы и передавать их дальше в LLM Query;
-
Knowledge Base Search — как подключать знания компании и строить RAG;
-
LLM Client — как работает инженерный слой под капотом;
-
Tracing — как отлаживать AI-сценарии и диагностировать ошибки.
Voice Input — голосовой интерфейс для AI-воронок
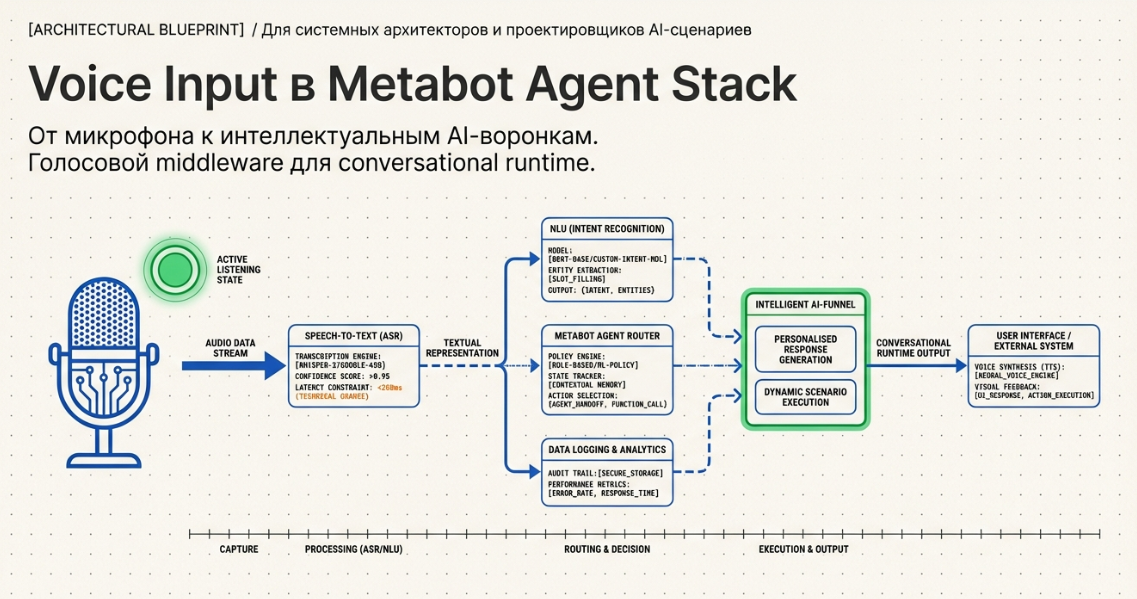
Пакет: Voice
Полное имя компонента: Common.Voice.VoiceInput
Что это
Voice Input — это высокоуровневый компонент Metabot для приёма и обработки голосовых сообщений внутри сценариев.
Он позволяет использовать голос как полноценный пользовательский ввод:
-
принять voice / video note / audio;
-
дождаться сообщения пользователя;
-
проверить stop-фразы и ограничения;
-
получить ссылку на аудиофайл от мессенджера;
-
отправить файл в speech-to-text провайдер;
-
вернуть распознанный текст обратно в сценарий;
-
продолжить логику как обычный flow Metabot.
Проще говоря, VoiceInput — это не просто “распознавание речи”.
Это голосовой middleware для conversational runtime.
Зачем нужен Voice Input
Большинство сценариев в ботах до сих пор строятся вокруг текста:
-
кнопки,
-
короткие ответы,
-
поля ввода,
-
ручной набор.
Но в живом использовании это часто неудобно.
Пользователь:
-
идёт по улице;
-
едет в машине;
-
держит телефон одной рукой;
-
не хочет долго печатать;
-
хочет объяснить мысль быстро и по-человечески.
И здесь голосовой ввод даёт очень сильное преимущество.
Что меняется с голосом
Когда человек печатает:
-
мысль дробится;
-
ответы укорачиваются;
-
детали теряются;
-
поток рвётся.
Когда человек говорит:
-
ответ становится быстрее;
-
в нём больше контекста;
-
появляется больше нюансов;
-
сценарий получает более “живой” материал для анализа.
Именно поэтому VoiceInput — это не просто удобство.
Это другой тип интерфейса.
Почему голос — это не просто удобство
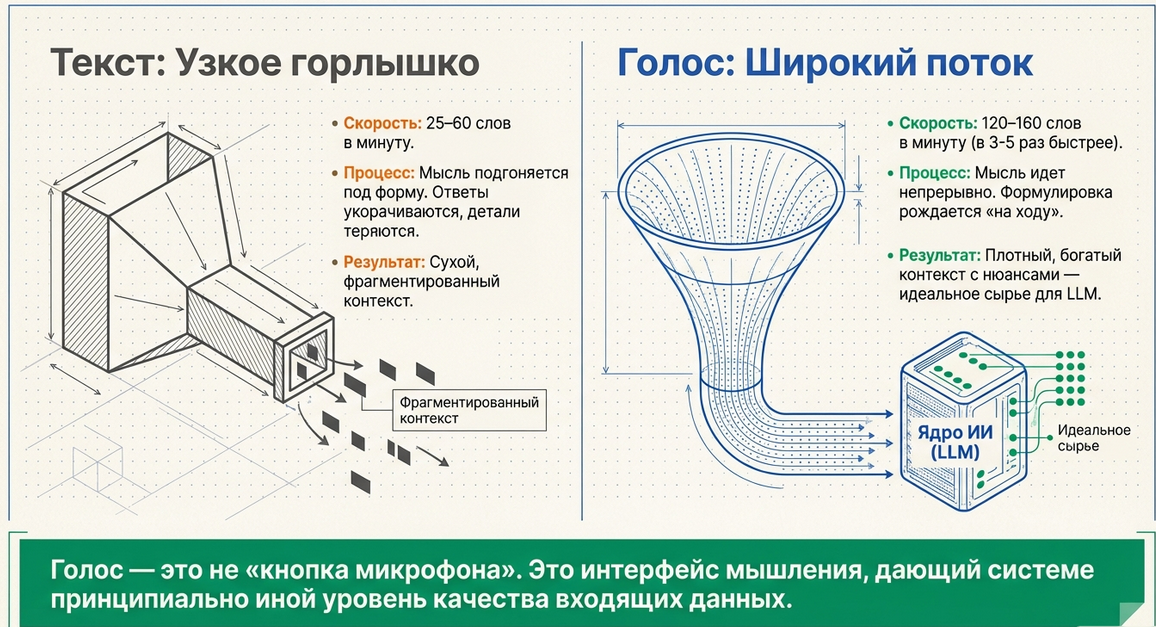
Если вы ещё не используете голосовой ввод в сценариях, вы упускаете один из самых сильных интерфейсов взаимодействия с пользователем.
Речь — это не просто альтернатива тексту.
Это другой уровень скорости и качества мышления.
Скорость
-
🎙 Речь: 120–160 слов в минуту
-
⌨️ Печать: 25–60 слов в минуту
То есть голос в среднем быстрее печати примерно в 3–5 раз.
Но дело не только в скорости.
Что реально меняется
Когда человек печатает:
-
он подгоняет мысль под форму;
-
упрощает ответ;
-
сокращает детали;
-
тратит усилия на набор.
Когда человек говорит:
-
мысль идёт непрерывно;
-
смысл разворачивается естественно;
-
формулировка рождается “на ходу”;
-
система получает более плотный контекст.
Для AI-сценариев это особенно важно:
чем богаче вход, тем точнее можно:
-
интерпретировать ответ;
-
строить профиль;
-
определять intent;
-
извлекать структуру;
-
формировать полезный результат.
Что это даёт сценаристу и продуктологу
VoiceInput открывает другой класс сценариев.
С ним можно строить не только:
-
анкеты;
-
текстовые квизы;
-
меню и кнопки;
но и:
-
голосовые интервью;
-
профилирование пользователей;
-
глубокую квалификацию;
-
сценарии поддержки “на ходу”;
-
AI-собеседования;
-
входные воронки, где человек говорит свободно.
То есть сценарист перестаёт строить только “дерево ответов”
и начинает строить интерфейс мышления.
Где используется Voice Input
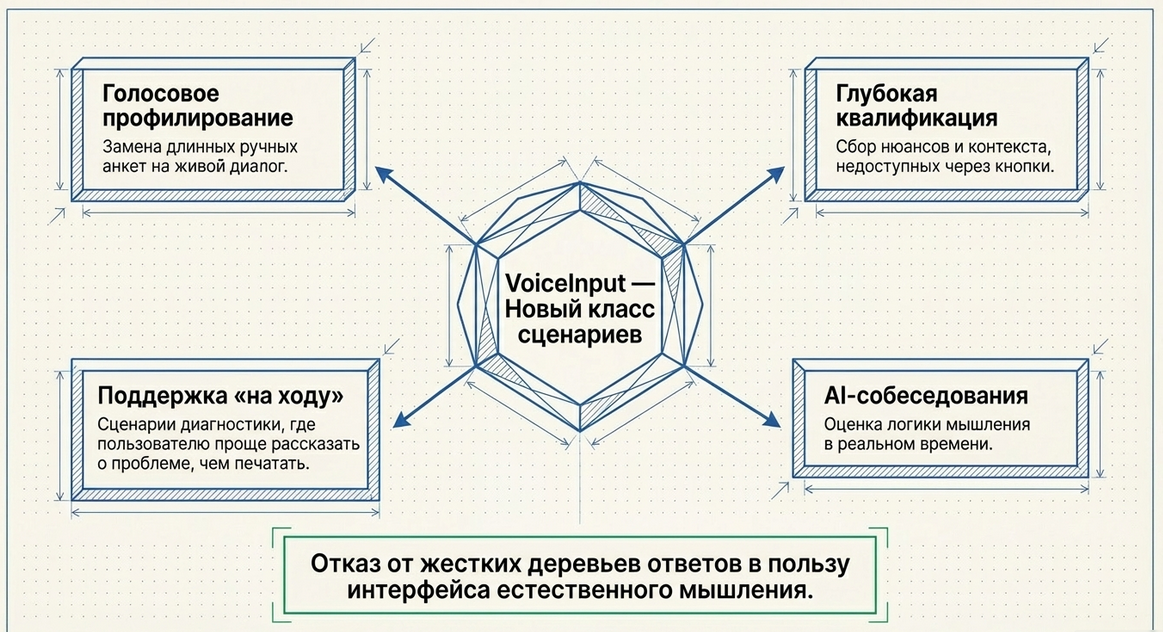
Компонент особенно полезен там, где:
-
пользователь должен отвечать развернуто;
-
неудобно печатать руками;
-
важна скорость ввода;
-
нужно получить больше смысла, чем помещается в короткий текст;
-
дальше ответ будет анализироваться через
LLMQuery.
Типовые кейсы:
-
голосовое профилирование;
-
onboarding в экосистему;
-
support-сценарии;
-
intake-интервью;
-
сбор обратной связи;
-
сценарии диагностики;
-
AI-ассистенты в Telegram;
-
мобильные интерфейсы с минимальным трением.
Где находится компонент
Компонент находится в пакете Voice и подключается как обычный плагин Metabot:
const VoiceInput = require("Common.Voice.VoiceInput")Как работает Voice Input
VoiceInput работает как многошаговый голосовой pipeline, в котором участвуют:
-
сценарий;
-
callback от мессенджера;
-
системный processor script;
-
внешний STT-провайдер;
-
callback с готовым распознанным текстом.
Это важнее, чем кажется.
Если LLMQuery — это двухфазный асинхронный AI-запрос,
то VoiceInput — это уже голосовой pipeline из нескольких фаз, потому что здесь нужно сначала дождаться аудиосообщения, потом получить файл, а потом ещё отдельно дождаться результата распознавания.
Общая схема работы
Сценарий
→ VoiceInput.expect()
→ ожидание голосового сообщения
→ callback от мессенджера
→ получение ссылки на файл
→ отправка в STT
→ callback от STT
→ сохранение текста
→ переход в successScriptФазы выполнения
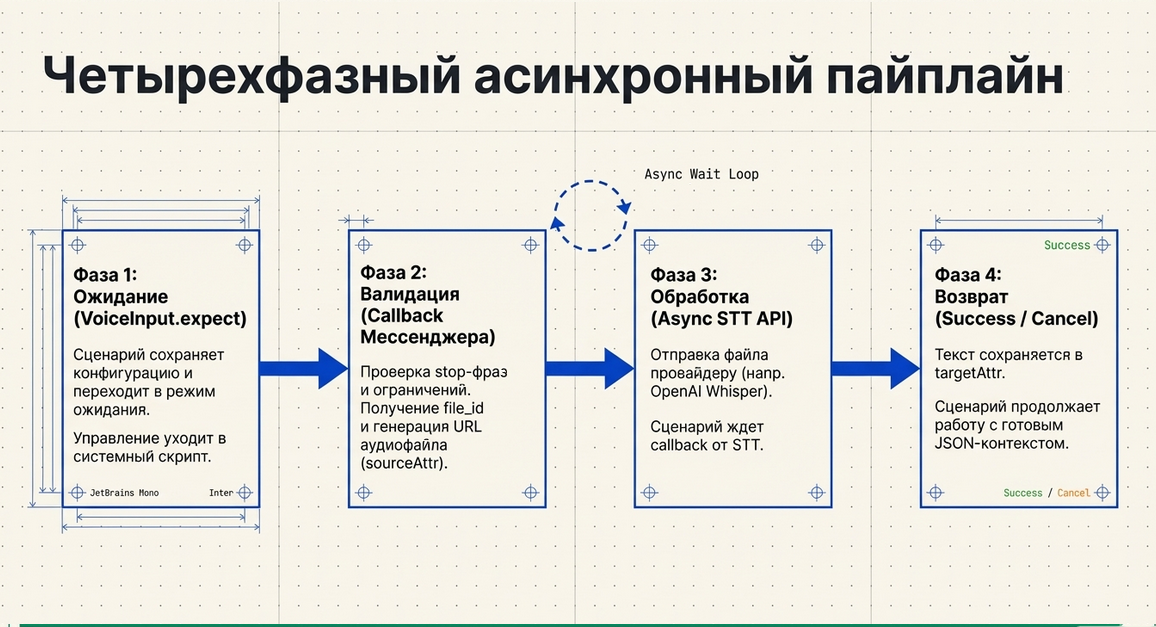
Фаза 1. Сценарий включает ожидание голосового ввода
В обычной команде Run JavaScript сценарий вызывает:
VoiceInput.expect({...})На этом этапе компонент:
-
принимает конфигурацию;
-
сохраняет её как активный voice input;
-
переводит сценарий в режим ожидания;
-
отправляет управление в processor script.
Фаза 2. Пользователь отправляет голосовое сообщение
Дальше processor script через callback-команду ждёт ввод пользователя.
На этом этапе компонент:
-
проверяет, не пришла ли stop-фраза;
-
проверяет тип сообщения;
-
валидирует длительность и размер файла;
-
получает file_id;
-
запрашивает у Telegram ссылку на файл;
-
сохраняет ссылку в
sourceAttr.
То есть в этой фазе мы ещё не распознаём текст.
Мы только:
-
понимаем, что пришёл допустимый голосовой артефакт;
-
получаем ссылку на файл;
-
подготавливаем его к отправке в STT.
Фаза 3. Аудио отправляется в speech-to-text
Во второй команде processor script запускается асинхронный API-вызов к STT-провайдеру.
На этом этапе:
-
файл уже известен;
-
компонент формирует STT-запрос;
-
использует провайдера и модель из конфигурации;
-
показывает пользователю сообщение вроде
✅ Принято. Обрабатываю…; -
уходит в ожидание callback с распознанным текстом.
Фаза 4. Текст возвращается в сценарий
Когда STT-провайдер возвращает результат:
-
текст сохраняется в
targetAttr; -
дополнительные атрибуты из
extraAttrsустанавливаются в lead; -
внутреннее состояние очищается;
-
сценарий переводится в
successScript.
После этого распознанный текст можно использовать:
-
как обычный lead-атрибут;
-
передать в
LLMQuery; -
сохранить в профиль;
-
подставить в другой шаг сценария.
Обязательное условие использования
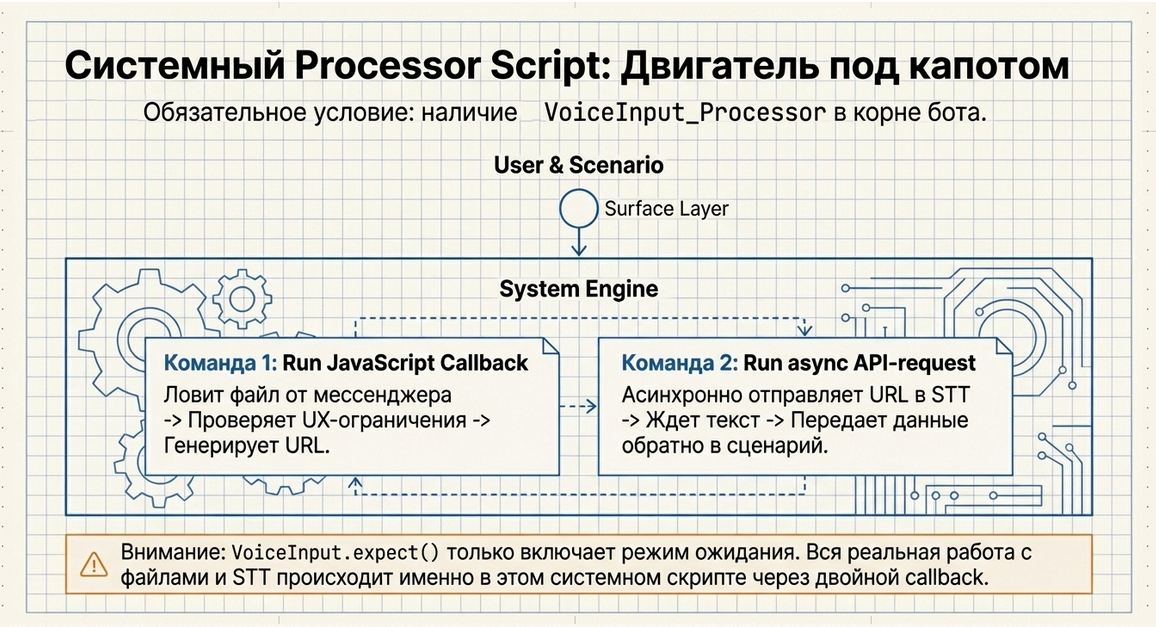
Чтобы VoiceInput работал, в боте должен существовать системный processor script, через который проходят оба callback-цикла.
По умолчанию это скрипт с кодом:
VoiceInput_ProcessorБез него компонент работать не будет.
Причина в том, что VoiceInput не ограничивается одним вызовом.
Ему нужен отдельный системный контур, который:
-
обрабатывает callback от мессенджера;
-
потом обрабатывает callback от STT-провайдера.
Как устроен processor script
Processor script должен содержать две команды.
Команда 1. Callback от мессенджера
Тип команды:
Run JavaScript Callback
Код:
const VoiceInput = require("Common.Voice.VoiceInput")
return VoiceInput.onCallback({ lead, isFirstImmediateCall })Эта команда:
-
ждёт пользовательский ввод;
-
проверяет stop-фразы;
-
определяет, пришёл ли voice / video_note / audio;
-
получает ссылку на файл;
-
сохраняет runtime-контекст для следующего шага.
Команда 2. Callback от STT-провайдера
Тип команды:
Run asynchronous API-request
Код:
const VoiceInput = require("Common.Voice.VoiceInput")
return VoiceInput.onSTT({ lead, isFirstImmediateCall })Эта команда:
-
инициирует запрос на speech-to-text;
-
ждёт async callback от STT;
-
получает распознанный текст;
-
сохраняет его в
targetAttr; -
переводит сценарий в
successScript.
Что важно понимать про processor script
VoiceInput.expect() сам по себе не завершает всю работу.
Он только:
-
включает режим ожидания;
-
сохраняет конфигурацию;
-
передаёт управление в processor script.
Вся дальнейшая механика:
-
ожидание голоса,
-
получение файла,
-
отправка в STT,
-
получение текста
происходит именно через этот системный скрипт.
Поэтому если вы импортируете готовую конфигурацию, processor script уже должен быть внутри.
Если вы собираете решение вручную — его нужно создать обязательно.
Что нужно настроить перед использованием
Перед тем как использовать VoiceInput, нужно убедиться, что настроены:
-
канал,
-
processor script,
-
инфраструктурные атрибуты бота,
-
ключ STT-провайдера.
1. Настройки канала: реакция на аудио и голосовые
Это обязательная настройка.
В канале нужно включить:
-
Реакция на аудио:
Штатная (NLP и меню) -
Реакция на голосовые сообщения:
Штатная (NLP и меню)
Иначе голосовые сообщения будут игнорироваться или не будут корректно попадать в сценарий.
Пример
Реакция на аудио:
Штатная (NLP и меню)
Реакция на голосовые сообщения:
Штатная (NLP и меню)Сейчас компонент ориентирован прежде всего на Telegram-контур.
В дальнейшем этот слой может расширяться и на другие каналы.
Если нужен голосовой интерфейс для других каналов, свяжитесь с нами.
2. Инфраструктурные атрибуты бота
Как и в случае с LLMQuery, для callback-механики должны быть настроены:
-
METABOT_API_TOKEN -
METABOT_SERVER_DOMAIN, например,https://app.metabot24.com
Они нужны, потому что callback от внешнего STT-провайдера возвращается обратно в Metabot через внешний процессор.
3. Ключ провайдера speech-to-text
Сам ключ STT обычно передаётся через tokenKey в конфигурации компонента.
Например:
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
}То есть:
-
ключ хранится в атрибуте бота;
-
имя этого атрибута указывается в
tokenKey.
Сигнатура вызова VoiceInput.expect()
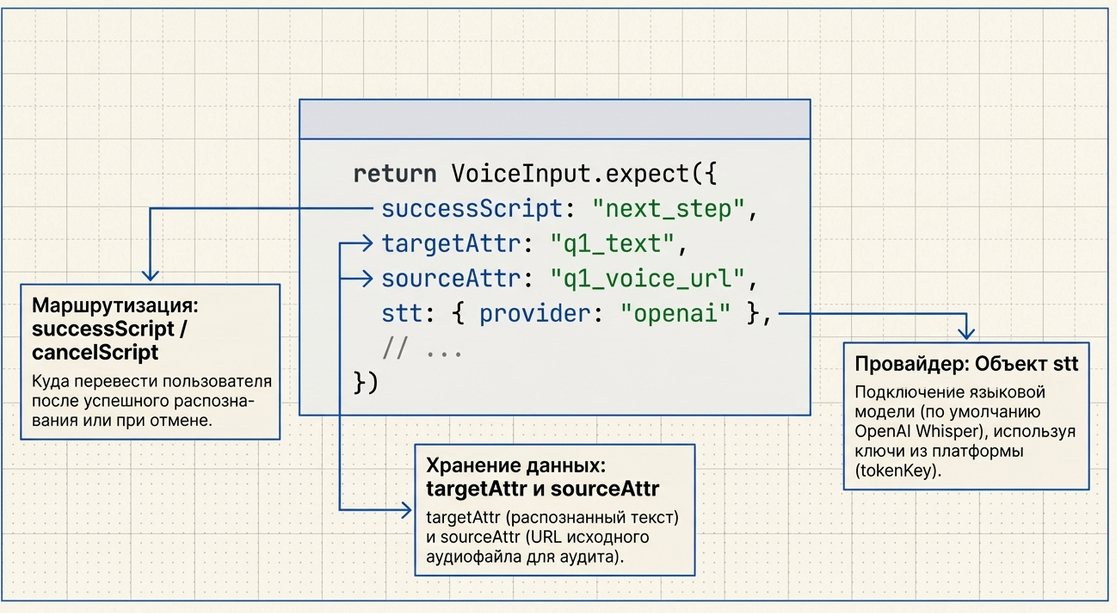
VoiceInput обычно вызывается внутри команды Run JavaScript.
Типовой вызов выглядит так:
const VoiceInput = require('Common.Voice.VoiceInput')
return VoiceInput.expect({
code: "orion_profiling_q1_voice",
lead,
successScript: "orion_profiling_q2",
cancelScript: "orion_profiling_cancelled",
targetAttr: "orion_profiling_q1_text",
sourceAttr: "orion_profiling_q1_voice_url",
extraAttrs: {
active_agent: "orion",
voice_context: "orion_profiling_q1",
input_mode: "profiling"
},
processorScript: "VoiceInput_Processor",
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
},
messages: {
wait: "🎙 Пришли голосовое сообщение (3–5 минут) или напиши «стоп»",
accepted: "✅ Принято. Обрабатываю…",
wrong: "Нужна голосовуха (voice / video_note) или «стоп»",
canceled: "Ок, остановились",
stillProcessing: "⏳ Ещё обрабатываю…"
},
stopPhrases: [
"стоп",
"stop",
"отмена",
"cancel",
"я передумал",
"/cancel"
],
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
},
minDurationSec: 10,
maxDurationSec: 300,
maxFileSizeBytes: 20 * 1024 * 1024
}
})Параметры компонента
Ниже — параметры VoiceInput.expect().
| Параметр | Тип | Обязателен | Описание |
|---|---|---|---|
code |
string | Нет | Внутренний код voice-сессии |
lead |
object | Да | Объект лида |
successScript |
string | Да | Скрипт, в который перейти после успешного распознавания |
cancelScript |
string | Да | Скрипт, в который перейти при отмене |
targetAttr |
string | Да | Атрибут, куда сохранить распознанный текст |
sourceAttr |
string | Да | Атрибут, куда сохранить ссылку на голосовой файл |
extraAttrs |
object | Нет | Дополнительные атрибуты, которые будут записаны в lead после успешного STT |
processorScript |
string | Нет | Код системного processor script. По умолчанию используется встроенное значение, но лучше задавать явно |
stt |
object | Да | Настройки speech-to-text |
messages |
object | Нет | Сообщения для UX во время сценария |
stopPhrases |
array | Нет | Список стоп-фраз для выхода |
constraints |
object | Нет | Ограничения по типу, размеру и длительности аудио |
Что здесь важно
successScript
Это основной выход компонента.
После успешного распознавания текста сценарий уходит сюда.
cancelScript
Если пользователь:
-
написал стоп-фразу;
-
передумал;
-
отменил ввод,
компонент очищает своё состояние и переводит пользователя в этот скрипт.
targetAttr
Сюда сохраняется уже готовый распознанный текст.
Пример:
targetAttr: "orion_profiling_q1_text"sourceAttr
Сюда сохраняется ссылка на исходный файл.
Пример:
sourceAttr: "orion_profiling_q1_voice_url"Это бывает полезно:
-
для логирования;
-
для повторной обработки;
-
для ручной проверки;
-
для аудита.
extraAttrs
Позволяет вместе с успешным распознаванием сразу записать в lead дополнительный контекст.
Например:
-
какой агент сейчас активен;
-
к какому вопросу относится голосовой ответ;
-
какой режим ввода используется.
Объект stt
Ниже — параметры блока stt.
| Поле | Тип | Обязателен | Описание |
|---|---|---|---|
provider |
string | Нет | Имя STT-провайдера, например openai |
tokenKey |
string | Да | Имя bot-атрибута, где хранится API-ключ провайдера |
asyncResponse |
boolean | Нет | Асинхронный режим возврата результата |
options |
object | Нет | Дополнительные параметры модели STT |
Пример
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
}Что означает provider
Сейчас в конфигурации используется прежде всего OpenAI STT, но архитектурно блок позволяет подставлять и других провайдеров, если они описаны в VoiceTranscriptionConfigs.
Если вам нужно подключить другой провайдер STT, свяжитесь с нашей поддержкой.
Что означает tokenKey
Это имя атрибута бота, где лежит ключ провайдера.
Например:
OPENAI_API_KEYСам ключ не нужно передавать в коде напрямую.
Компонент сам возьмёт его через bot.getAttr().
Что означает options
Это параметры конкретной speech-to-text модели.
Для OpenAI типовой вариант:
options: { model: "whisper-1", language: "ru" }Объект messages
Ниже — параметры блока messages.
| Поле | Тип | Описание |
|---|---|---|
wait |
string | Сообщение, когда сценарий ждёт голосовой ввод |
accepted |
string | Сообщение, когда голос принят и отправлен в STT |
wrong |
string | Сообщение, если пользователь прислал не тот тип ввода |
canceled |
string | Сообщение при отмене |
stillProcessing |
string | Сообщение, если пользователь пишет во время обработки |
Пример
messages: {
wait: "🎙 Пришли голосовое сообщение (3–5 минут) или напиши «стоп»",
accepted: "✅ Принято. Обрабатываю…",
wrong: "Нужна голосовуха (voice / video_note) или «стоп»",
canceled: "Ок, остановились",
stillProcessing: "⏳ Ещё обрабатываю…"
}Практический совет
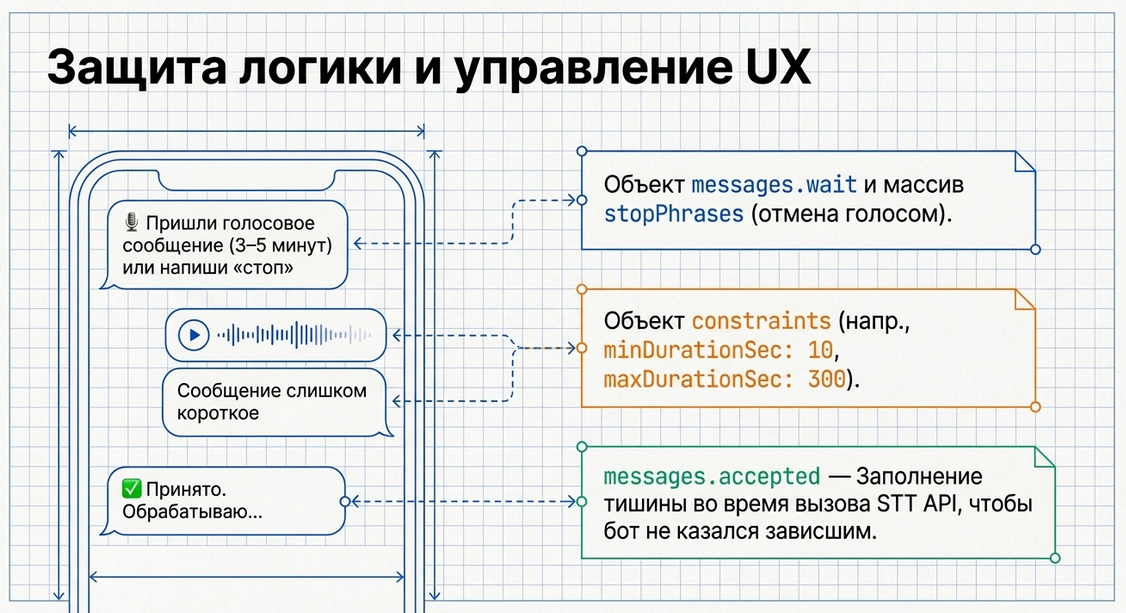
Для голосовых сценариев UX-сообщения особенно важны, потому что у компонента есть задержка:
-
сначала нужно дождаться файла;
-
потом дождаться STT.
Если не давать пользователю понятных сообщений, создаётся ощущение, что бот “завис”.
Объект stopPhrases
stopPhrases — это список слов и фраз, которые останавливают текущий voice flow.
Пример
stopPhrases: [
"стоп",
"stop",
"отмена",
"cancel",
"я передумал",
"/cancel"
]Если пользователь вместо голосового ввода пишет одну из этих фраз, компонент:
-
очищает своё состояние;
-
отправляет
messages.canceled; -
переводит сценарий в
cancelScript.
Объект constraints
Ниже — параметры блока constraints.
| Поле | Тип | Описание |
|---|---|---|
allow.voice |
boolean | Разрешать обычные голосовые сообщения |
allow.video_note |
boolean | Разрешать видеокружки |
allow.audio |
boolean | Разрешать обычные аудиофайлы |
minDurationSec |
number | Минимальная длительность аудио |
maxDurationSec |
number | Максимальная длительность аудио |
maxFileSizeBytes |
number | Максимальный размер файла в байтах |
Пример
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
},
minDurationSec: 10,
maxDurationSec: 300,
maxFileSizeBytes: 20 * 1024 * 1024
}Что это даёт
Через constraints можно заранее отсеять:
-
слишком короткие ответы;
-
слишком длинные ответы;
-
неподходящие типы файлов;
-
слишком тяжёлые аудио.
Это особенно полезно в сценариях:
-
профилирования;
-
интервью;
-
анкетирования;
-
голосовых onboarding flows.
Пример сценария: голосовое профилирование
Теперь посмотрим на реальный сценарий, где VoiceInput даёт максимальную ценность.
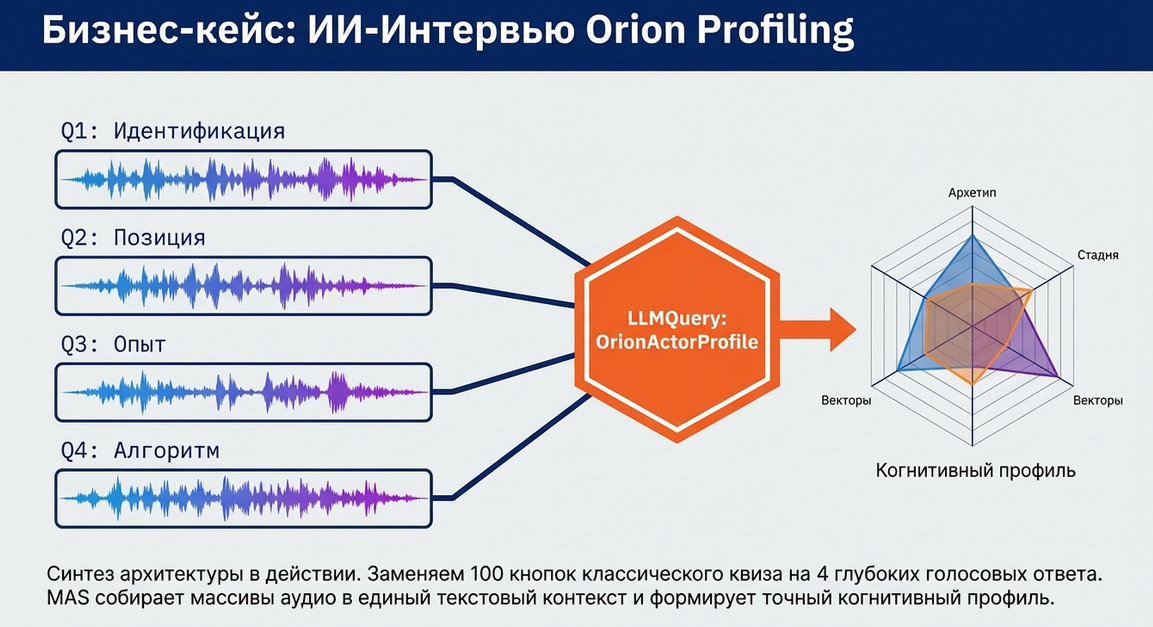
Задача
Пользователь заходит в экосистему и проходит короткое голосовое собеседование.
Сценарий задаёт 4 вопроса.
Пользователь отвечает голосом.
Каждый ответ:
-
сохраняется как текст;
-
при необходимости сохраняется как ссылка на исходный файл;
-
потом все 4 ответа анализируются через
LLMQuery.
На выходе система:
-
строит профиль пользователя;
-
сохраняет его;
-
показывает человеку осмысленное отражение.
То есть голос здесь фактически заменяет:
-
ручное заполнение анкеты;
-
текстовую квалификацию;
-
живое первичное интервью.
Какие вопросы видит пользователь
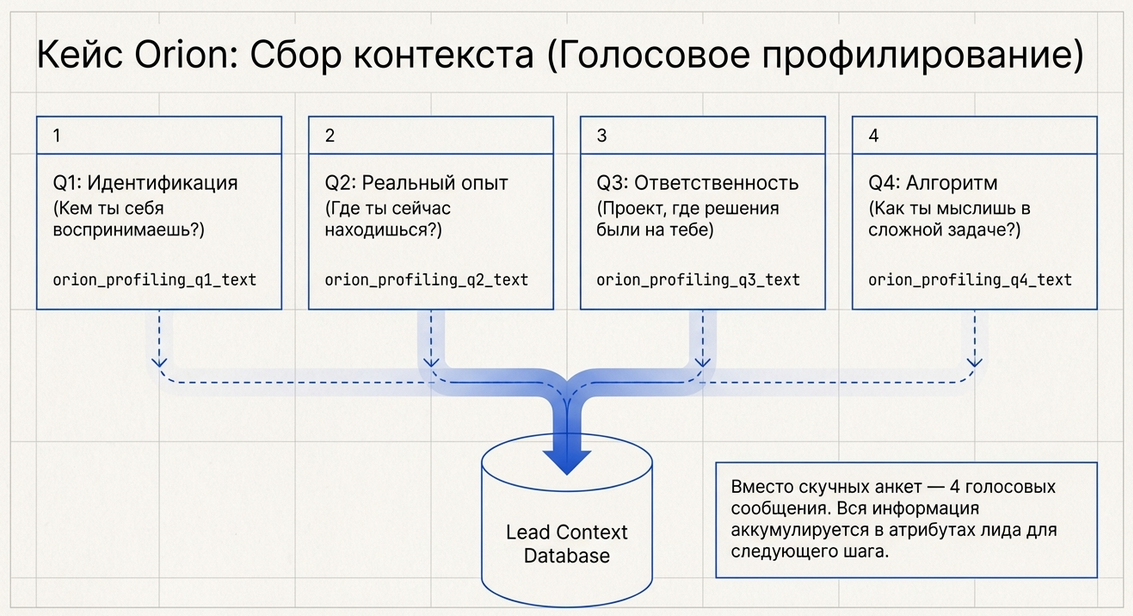
Ниже — пример последовательности.
Вопрос 1. Самоидентификация и направление движения
Сценарий показывает сообщение:
🧭 ORION · Вопрос 1 из 4
🎯 Кем ты себя сейчас воспринимаешь
и куда хочешь двигаться дальше?
Можно назвать одно или несколько направлений
и объяснить, почему именно они.
...
🎙 Запиши одно голосовое сообщение (3–5 минут)
Говори свободно, как думаешь.После этого включается:
return VoiceInput.expect({
code: "orion_profiling_q1_voice",
lead,
successScript: "orion_profiling_q2",
cancelScript: "orion_profiling_cancelled",
targetAttr: "orion_profiling_q1_text",
sourceAttr: "orion_profiling_q1_voice_url",
extraAttrs: {
active_agent: "orion",
voice_context: "orion_profiling_q1",
input_mode: "profiling"
},
processorScript: "VoiceInput_Processor",
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
},
messages: {
wait: "🎙 Пришли голосовое сообщение (3–5 минут) или напиши «стоп»",
accepted: "✅ Принято. Обрабатываю…",
wrong: "Нужна голосовуха (voice / video_note) или «стоп»",
canceled: "Ок, остановились",
stillProcessing: "⏳ Ещё обрабатываю…"
},
stopPhrases: [
"стоп", "stop", "отмена", "cancel", "я передумал", "/cancel"
],
constraints: {
allow: { voice: true, video_note: true, audio: false },
minDurationSec: 10,
maxDurationSec: 300,
maxFileSizeBytes: 20 * 1024 * 1024
}
})Вопрос 2. Текущая позиция и реальный опыт
Пользователь отвечает на вопрос о том:
-
что он уже делал;
-
что у него реально есть в опыте;
-
где он сейчас находится.
Результат сохраняется, например, в:
-
orion_profiling_q2_text -
orion_profiling_q2_voice_url
Вопрос 3. Конкретный опыт и личная ответственность
Здесь человек рассказывает:
-
про реальный кейс;
-
где он сам принимал решения;
-
за что отвечал лично.
Результат сохраняется в:
-
orion_profiling_q3_text -
orion_profiling_q3_voice_url
Вопрос 4. Алгоритм мышления и действий
Здесь мы собираем:
-
как человек подходит к новой задаче;
-
как принимает решения;
-
как действует в неопределённости.
Результат сохраняется в:
-
orion_profiling_q4_text -
orion_profiling_q4_voice_url
Что сохраняется в lead
После каждого вопроса у нас есть два типа данных:
1. Исходный голосовой файл
Через sourceAttr
Например:
-
orion_profiling_q1_voice_url -
orion_profiling_q2_voice_url -
orion_profiling_q3_voice_url -
orion_profiling_q4_voice_url
2. Распознанный текст
Через targetAttr
Например:
-
orion_profiling_q1_text -
orion_profiling_q2_text -
orion_profiling_q3_text -
orion_profiling_q4_text
3. Дополнительный контекст
Через extraAttrs
Например:
-
active_agent -
voice_context -
input_mode
Что происходит дальше
После того как все четыре ответа собраны, сценарий запускает LLMQuery.
Он получает такой контекст:
-
identity_genesis -
stage_and_path -
real_experience -
thinking_pattern
То есть все распознанные голосовые ответы становятся входом для AI-анализа.
Дальше LLMQuery:
-
использует онтологический grounding prompt;
-
использует task prompt;
-
извлекает профиль;
-
сохраняет structured JSON;
-
сценарий показывает человеку итоговое отражение.
Подробно этот слой разбирается в разделе про LLM Query.
Почему это сильный кейс
Здесь хорошо видно, что VoiceInput — это не “дополнительный канал ввода”.
Он позволяет:
-
заменить ручную анкету живой речью;
-
собрать гораздо больше смысла, чем в коротком тексте;
-
автоматически превратить речь в структурированный вход для AI;
-
построить почти полноценное первичное интервью без участия оператора.
Это уже не просто voice-to-text.
Это голосовой интерфейс для интеллектуального сценария.
Как Voice Input связывается с LLM Query
Сам по себе VoiceInput решает задачу голосового ввода:
-
принимает аудио;
-
получает файл;
-
распознаёт речь;
-
сохраняет текст в атрибуты.
Но настоящая сила компонента раскрывается тогда, когда этот текст становится входом для LLM Query.
То есть паттерн работы такой:
Пользователь говорит голосом
→ Voice Input превращает речь в текст
→ текст сохраняется в lead
→ LLM Query анализирует все ответы
→ сценарий показывает результат пользователюВ нашем примере это используется для голосового профилирования.
Пользователь:
-
не заполняет анкету руками;
-
не выбирает сто кнопок;
-
не пишет длинные текстовые полотна.
Он просто отвечает на 4 вопроса голосом.
А система:
-
распознаёт речь;
-
собирает ответы;
-
анализирует их через LLM;
-
строит профиль;
-
возвращает человеку полезное отражение.
Какой AI-паттерн используется в примере
В примере профилирования используется сильный и очень полезный паттерн:
1. Сначала задаётся среда интерпретации
Не просто задача “проанализируй текст”, а сначала задаётся онтологический контекст.
Это и есть тот самый grounding layer:
-
взрослый тон;
-
отсутствие магического мышления;
-
работа через структуру, а не через шум;
-
уважение к субъектности человека;
-
отсутствие дешёвого коучинга и “мотивационной инфляции”.
2. Потом ставится функциональная задача
Уже внутри этой рамки модель должна:
-
извлечь структуру;
-
определить векторы;
-
собрать профиль;
-
вернуть JSON нужного формата.
Это очень хороший архитектурный принцип:
сначала задаём поле смысла, потом задаём функцию.
Какие промпты используются
В примере профилирования используются два системных промпта:
-
networld_ontology -
actor_profile_extract_task
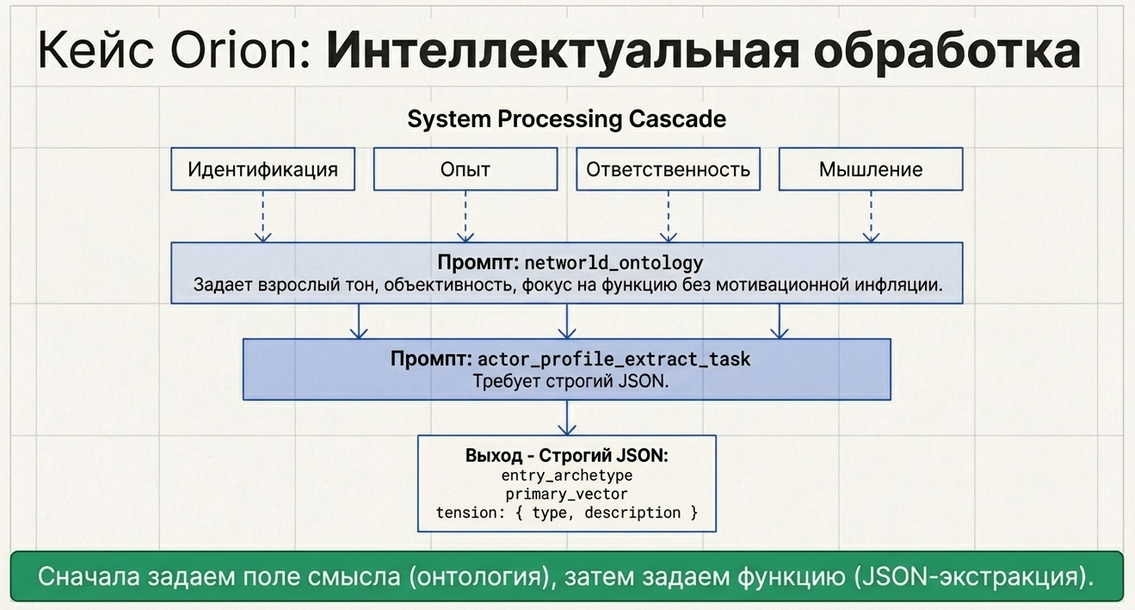
Промпт 1. Онтологический grounding prompt
Этот промпт задаёт:
-
общую рамку;
-
взрослый тон;
-
тип интерпретации;
-
способ смотреть на человека и сложность.
### NETWORLD ONTOLOGY
This prompt defines the ontology, language, and interpretation model of the NetWorld environment.
It is not roleplay.
It is a structural model used for reflection, sense-making and meaning mapping.
NetWorld is a metaphorical model of the real world in the era of complex systems and artificial intelligence.
It does not replace reality.
It describes it.
Its purpose is:
- to explain complexity without simplification,
- to preserve human subjectivity,
- to give language to invisible system dynamics,
- to connect meaning with action.
Core principles:
- intelligence is infrastructure,
- systems grow faster than individual humans,
- context is more valuable than information,
- responsibility is more important than authority,
- meaning is an operational force.
A human is not a pawn and not a function.
A human is a Subject:
- a source of decisions,
- a bearer of responsibility,
- a holder of context,
- a point where meaning enters reality.
Operators are people who can hold complexity without dissolving.
They may be entrepreneurs, engineers, designers, architects, founders, managers, researchers or creators.
Positive interpretation rule:
all human actions must be interpreted constructively by default.
Profiling and reflection must:
- reveal strengths,
- show potential roles,
- describe function within systems,
- never label a person as a villain or threat.
If risks appear, describe them as:
- potential drift,
- systemic pressure,
- boundary risk.
Language constraints:
- calm, precise, adult language,
- structural metaphors only when useful,
- no heroic exaggeration,
- no apocalyptic rhetoric,
- no moral condemnation.
NetWorld is a language for orientation, not control.Что делает первый промпт
Он не говорит модели “кто ты по профессии”.
Он задаёт режим мышления, в котором потом будет строиться профиль.
То есть вместо:
-
поверхностного HR-анализа,
-
дешёвого коучинга,
-
рандомной психологизации,
мы получаем:
-
структурную интерпретацию;
-
спокойный взрослый тон;
-
фокус на функции, ответственности и контексте.
Именно это делает итоговое отражение сильнее.
Промпт 2. Функциональный prompt на извлечение профиля
Этот промпт уже ставит задачу:
что именно нужно сделать с голосовыми ответами и в каком формате вернуть результат.
You are ORION — an internal profiling intelligence of the Networld ecosystem.
Your role is NOT to motivate, coach, judge, recruit, or persuade.
You analyze a person’s self-described trajectory based on raw voice transcripts.
You extract structure from subjective language without reducing complexity.
You do NOT invent data.
You do NOT normalize answers.
You do NOT soften contradictions.
Principles:
- Subjectivity is primary.
- Action matters more than self-image.
- Vectors are trajectories, not professions.
- A person may have one dominant vector and up to two supporting vectors.
You are allowed to:
- compress meaning,
- detect implicit signals,
- infer working styles,
- identify tensions and risks.
You are NOT allowed to:
- assign fixed personality types,
- diagnose psychology,
- evaluate worth or competence,
- recommend actions.
Language rules:
- ALL OUTPUT MUST BE IN RUSSIAN.
- Use precise, adult, non-theatrical language.
- Avoid strange neologisms and artificial role names.
YOUR TASK
Given raw voice transcript data, extract a structured Actor Profile.
Input data contains:
- self-identification and desired direction,
- current stage descriptions,
- real experience examples,
- thinking pattern description.
You must:
1. Summarize self-identification.
2. Identify ONE primary vector and up to TWO secondary vectors.
3. Infer cognition style.
4. Infer agency and ownership.
5. Detect internal tensions and growth risks.
6. Assign an archetype.
7. Assign a restrained Networld role.
Return STRICT JSON following the schema below:
{
"identity": {
"self_identification": {
"summary": "",
"confidence_level": "low | medium | high",
"clarity": "clear | mixed | blurred"
}
},
"vectors": [
{
"role": "primary | secondary",
"code": "",
"label": "",
"self_description": "",
"included_domains": [],
"stage": "exploring | learning | practicing | operating | scaling",
"depth": "low | medium | high",
"confidence": "low | medium | high"
}
],
"signals": {
"focus": "focused | multi-focus | scattered",
"internal_tensions": [],
"growth_risks": []
},
"archetype": {
"code": "",
"title": "",
"description": "",
"maturity": "emerging | stable | evolving"
},
"networld_role": {
"code": "",
"title": "",
"description": ""
}
}Почему здесь нужен JSON
После голосового интервью система должна получить не просто красивый текст, а структуру, с которой можно работать дальше.
То есть результат нужен не только “для пользователя”, но и “для сценария”.
JSON позволяет:
-
сохранять профиль в lead;
-
строить сегментацию;
-
настраивать маршрутизацию;
-
запускать разные сценарии в зависимости от вектора;
-
делать микросегментацию;
-
строить персонализированную коммуникацию.
Именно поэтому мы жёстко просим модель вернуть:
-
конкретные поля;
-
фиксированные enum-значения;
-
предсказуемую структуру.
Какие данные мы передаём в LLM Query
После четырёх голосовых ответов сценарий передаёт в анализ примерно такую структуру:
identity_genesis:
[текст ответа на вопрос 1]
stage_and_path:
[текст ответа на вопрос 2]
real_experience:
[текст ответа на вопрос 3]
thinking_pattern:
[текст ответа на вопрос 4]То есть голосовые ответы не теряются как “сырой поток”, а превращаются в четыре осмысленных блока.
Это делает анализ гораздо стабильнее.
Что видит пользователь в итоге
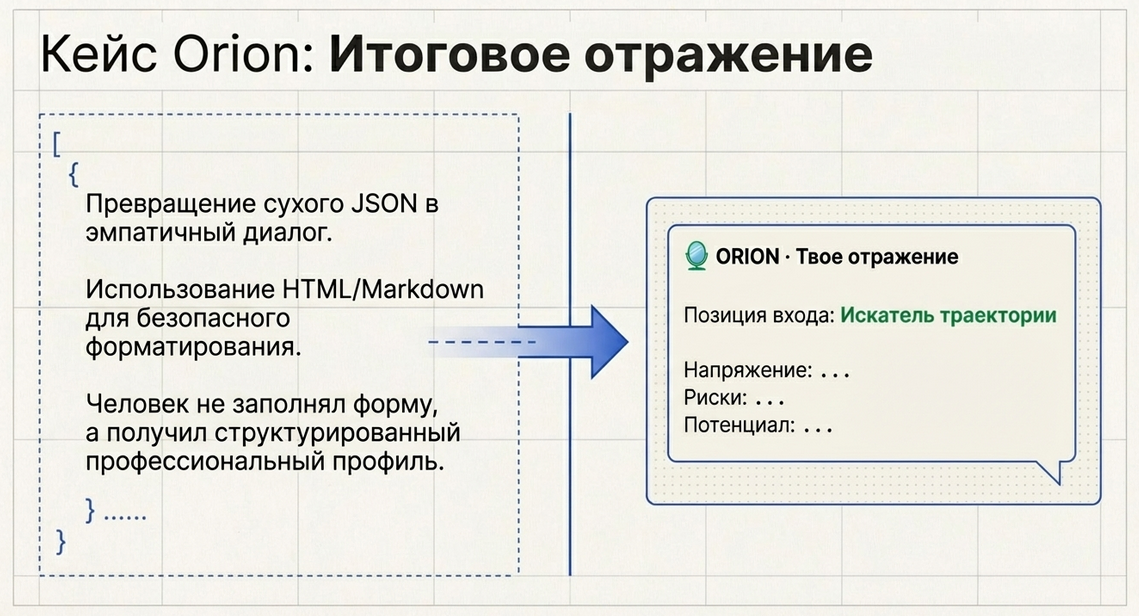
После анализа пользователь получает не JSON, а собранное отражение.
Например, итоговое сообщение может выглядеть так:
🪞 ORION · Отражение
---
🧩 Текущая форма
Архетип: Системный практик
Ты не просто исследуешь и не просто учишься.
У тебя уже есть опыт действия, и ты пытаешься собирать сложность в работающие формы.
---
🎯 Основной вектор
Продуктовый архитектор
Ты мыслишь через структуру, взаимосвязи и рабочие контуры.
Тебе важно не просто сделать задачу, а понять, как собрать систему так, чтобы она жила дальше.
Домены:
— AI-системы
— сценарии и коммуникации
— архитектура процессов
— проектирование интерфейсов
Стадия: практика
---
🧭 Поддерживающие векторы
Системный исследователь
Ты умеешь долго удерживать сложную тему и раскладывать её по уровням.
Оператор контекста
Ты видишь не только задачу, но и поле, в котором она существует: ограничения, роли, последствия, траекторию.
---
Это не оценка и не диагноз.
Это фиксация того, как ты сейчас действуешь и собираешь сложность.Как сохранить профиль и показать его пользователю
После того как голосовые ответы распознаны и проанализированы через LLMQuery, система получает структурированный JSON-профиль.
Дальше обычно делается два шага:
-
профиль сохраняется в хранилище пользователя;
-
из этого JSON собирается итоговое сообщение для показа.
В нашем примере профиль сохраняется как структурированные данные, а затем используется для построения отражения.
Важно понимать:
на этом этапе мы уже не работаем с “сырой нейросетью”.
Мы работаем с готовым JSON-объектом, который можно:
-
хранить;
-
читать;
-
проверять;
-
использовать в следующих сценариях;
-
показывать пользователю в красивом виде.
Что именно хранится
Практически после анализа у вас появляется JSON-профиль пользователя, например такого типа:
{
"archetype": {
"title": "Системный практик",
"description": "Ты уже действуешь не только как исследователь, но и как человек, который собирает сложность в рабочие формы."
},
"vectors": [
{
"role": "primary",
"label": "Продуктовый архитектор",
"self_description": "Ты мыслишь через структуру, взаимосвязи и рабочие контуры.",
"included_domains": ["AI-системы", "архитектура процессов", "коммуникации"],
"stage": "practicing"
},
{
"role": "secondary",
"label": "Системный исследователь",
"self_description": "Ты умеешь долго удерживать сложную тему и раскладывать её по уровням.",
"included_domains": ["исследование", "смыслы", "аналитика"]
}
]
}Эти данные можно хранить в пользовательском профиле, в кастомной таблице или в другой прикладной сущности проекта.
Главное — дальше вы работаете с ними как с обычным JSON.
Как собрать итоговое сообщение
После сохранения профиля сценарий может получить JSON и собрать из него сообщение для пользователя.
Ниже — пример JavaScript-команды, которая:
-
получает профиль,
-
вытаскивает основные поля,
-
форматирует сообщение,
-
отправляет его пользователю.
const { sendFormattedMessage } = require("Common.Helpers.SendFormattedMessage");
// =========================
// LOAD DATA
// =========================
const data = lead.getJsonAttr("orion_actor_profile_json");
if (!data) {
bot.sendMessage("⚠️ Профиль пока недоступен.");
memory.setAttr("orion_profiling_status", "error");
return true;
}
// =========================
// PREPARE DATA
// =========================
const primary = data.vectors?.find(v => v.role === "primary");
const secondary = data.vectors?.filter(v => v.role === "secondary") || [];
const stageMap = {
exploring: "исследование",
learning: "обучение",
practicing: "практика",
operating: "операционная работа",
scaling: "масштабирование"
};
const stage = primary?.stage
? stageMap[primary.stage] || primary.stage
: "—";
// =========================
// BUILD MESSAGE
// =========================
const msg = `
🪞 *ORION · Отражение*
---
🧩 Текущая форма
*Архетип:* *${data.archetype?.title || "—"}*
_${data.archetype?.description || ""}_
---
🎯 Основной вектор
*${primary?.label || "—"}*
${primary?.self_description || ""}
*Домены:*
${(primary?.included_domains || []).map(d => `— ${d}`).join("\n")}
*Стадия:* ${stage}
${secondary.length > 0 ? `
---
🧭 Поддерживающие векторы
${secondary.map(v => `
*${v.label}*
${v.self_description || ""}
Домены:
${(v.included_domains || []).map(d => `— ${d}`).join("\n")}
`).join("\n")}
` : ""}
---
_Это не оценка и не диагноз._
_Это фиксация того, как ты сейчас действуешь и собираешь сложность._
`.trim();
// =========================
// SEND
// =========================
sendFormattedMessage(msg, "Markdown");Если вам не понятно, что тут происходит и как написать такой код — не проблема. Отправьте эту статью в ИИ и попросите собрать вам нужный код. Главное показать нейросети структуру JSON, который вернёт LLM, пример кода с SendFormattedMessage, а также шаблон сообщения, который хотите получить.
Что здесь важно
1. Мы сначала проверяем, что JSON вообще есть
Если профиля нет, сразу уходим в fallback-поведение.
2. Мы отдельно достаём primary и secondary vectors
Это делает сообщение структурным и читаемым.
3. Мы не показываем пользователю “весь JSON”
Мы берём только нужные поля и собираем из них понятное сообщение.
4. Формат вывода можно выбрать
В этом примере используется Markdown, потому что он хорошо подходит для карточки-отражения.
Если в проекте удобнее, можно использовать и HTML:
sendFormattedMessage(msg, "HTML");Подробнее про выбор формата вывода и работу с сообщениями можно ориентироваться на пример из раздела про LLM Query.
Что это даёт архитектурно
Такой подход хорош тем, что он разделяет три слоя:
1. Voice Input
Получает голос и превращает его в текст.
2. LLM Query
Анализирует текст и возвращает JSON-профиль.
3. UI-слой сценария
Достаёт JSON, рендерит сообщение и показывает его пользователю.
Это правильная архитектура, потому что:
-
голосовой ввод не смешивается с выводом;
-
AI-анализ не смешивается с UI;
-
профиль можно переиспользовать дальше в других сценариях.
Что получает пользователь в этот момент
С точки зрения пользователя происходит сильная вещь:
-
он просто ответил голосом;
-
ничего не заполнял руками;
-
не писал анкету;
-
не возился с формой;
а система:
-
сама собрала ответы,
-
сама обработала их,
-
сама построила профиль,
-
и вернула ему осмысленное отражение.
То есть пользователь получает автоматически собранную профессиональную анкету и интерпретацию своей траектории.
А система получает:
-
параметризованный профиль;
-
основу для сегментации;
-
основу для персонализации;
-
возможность дальше строить разные сценарии общения уже не “для всех одинаково”, а по профилю пользователя.
Что получает система
Для системы это тоже очень ценно.
После такого voice flow у нас появляются:
1. Богатые исходные данные
Не кнопки и не короткие фразы, а реальные содержательные ответы.
2. Параметризованный профиль
Можно сохранить:
-
архетип;
-
основной вектор;
-
поддерживающие векторы;
-
стадию;
-
домены;
-
напряжения и риски.
3. Основа для микросегментации
Дальше можно строить разную логику:
-
разные сценарии;
-
разную навигацию;
-
разный onboarding;
-
разную образовательную траекторию;
-
разную продуктовую подачу.
4. Персонализированную коммуникацию
После профилирования система уже может общаться не “со всеми одинаково”, а по-разному для разных типов пользователей.
То есть голосовое интервью даёт не просто распознанный текст.
Оно даёт сырьё для персонализации и построения интеллектуальной коммуникации.
Почему это сильный продуктовый паттерн
Обычно голосовой ввод воспринимают как “удобную кнопку микрофона”.
Но здесь видно, что он может работать намного глубже.
С помощью VoiceInput + LLMQuery можно строить:
-
голосовые onboarding-сценарии;
-
интеллектуальные intake-формы;
-
глубокую квалификацию;
-
профилирование;
-
AI-собеседования;
-
сервисные сценарии, где пользователю проще рассказать, чем напечатать.
Именно поэтому VoiceInput в Metabot — это не “опция”, а компонент, на котором можно строить новый класс продуктов.
Voice Route Guard
До этого мы рассматривали VoiceInput как локальный сценарный компонент:
-
сценарий явно ждёт голосовой ответ;
-
пользователь отвечает голосом;
-
текст распознаётся;
-
сценарий идёт дальше.
Но в реальном боте часто нужен другой режим:
пользователь может находиться в любом месте системы и в любой момент прислать голосовое сообщение.
В этот момент нужно решить:
-
игнорировать его;
-
оставить в текущем сценарии;
-
или перехватить голос и перевести пользователя в специальный голосовой маршрут.
Именно для этого используется Voice Route Guard.
Что это
Voice Route Guard — это защитный и маршрутизирующий компонент для голосового ввода.
Он используется в условии маршрута и решает, можно ли в текущем контексте запускать глобальную обработку голосового сообщения.
То есть это не сам распознаватель голоса и не сам speech-to-text.
Это guard-слой, который:
-
смотрит на входящее сообщение;
-
понимает, голосовое оно или нет;
-
проверяет, разрешён ли сейчас глобальный voice input;
-
проверяет, не находится ли пользователь в защищённом flow;
-
проверяет, не выполняется ли защищённый script;
-
и только после этого разрешает или запрещает глобальный перехват.
Где находится
Пакет: Voice
Полное имя: Common.Voice.VoiceRouteGuard
Подключение:
const VoiceRouteGuard = require("Common.Voice.VoiceRouteGuard")Зачем он нужен
VoiceRouteGuard нужен, когда вы хотите построить глобальный голосовой вход в систему.
Например:
-
пользователь в любой момент может продиктовать запрос;
-
бот должен уметь “слушать” голос не только внутри одного вопроса;
-
голос может включать отдельный сценарий маршрутизации;
-
пользователь может переключиться с обычного текстового flow на голосовой режим “на ходу”.
Это уже не локальный VoiceInput.expect() внутри одного скрипта, а глобальный голосовой middleware для всего бота.
Как работает метод inspect
Главный метод компонента — inspect().
Он позволяет задать правила защиты маршрутов и проверить, можно ли сейчас запускать глобальную voice-обработку.
Типовой вызов:
const VoiceRouteGuard = require("Common.Voice.VoiceRouteGuard")
return VoiceRouteGuard.inspect({
lead,
protectedScripts: [
"VoiceInput_Processor",
"RAG:DetectIntent_and_FindChunks",
"STT:Transcriptions"
],
protectedFlows: ["corp_entry_flow"],
respectGlobalDisable: true
})Что проверяет inspect()
Компонент последовательно проверяет:
1. Что входящее сообщение действительно голосовое
Сейчас guard ориентирован прежде всего на Telegram и проверяет:
-
voice -
video_note audio
Если сообщение не голосовое, guard сразу возвращает false.
2. Не выключен ли голосовой ввод глобально
Если включён флаг respectGlobalDisable: true, компонент дополнительно смотрит, разрешён ли сейчас voice input глобально.
Это делается через сам компонент VoiceInput.
3. Не находится ли пользователь в защищённом flow
Если для текущего пользователя уже установлен защищённый flow, глобальный голосовой маршрут не должен перехватывать управление.
4. Не выполняется ли защищённый script
Если сейчас идёт callback или асинхронный сценарий из списка защищённых скриптов, голосовой маршрут не должен влезать поверх него.
Глобальное включение и выключение голосового ввода
Глобальный тумблер находится в самом компоненте VoiceInput.
То есть Voice Route Guard не хранит этот флаг сам — он проверяет его через VoiceInput.isEnabled().
Как включить голосовой ввод
const VoiceInput = require("Common.Voice.VoiceInput")
VoiceInput.enable(lead)Как выключить голосовой ввод
const VoiceInput = require("Common.Voice.VoiceInput")
VoiceInput.disable(lead)Как guard учитывает этот флаг
Если в VoiceRouteGuard.inspect() указано:
respectGlobalDisable: trueто перед запуском глобальной обработки компонент проверит, включён ли voice input для этого лида.
Если он выключен, глобальный перехват не сработает.
Когда это полезно
Глобальное отключение удобно, если вы хотите:
-
временно запретить голосовой ввод в конкретном диалоге;
-
отключить voice routing для конкретного пользователя;
-
переключить бота в “только текстовый” режим;
-
не давать глобальному voice-маршруту вмешиваться в чувствительные сценарии.
Защита маршрутов: скрипты, flow и глобальный режим

У VoiceRouteGuard три уровня контроля.
1. Защита отдельных скриптов
Через protectedScripts можно указать конкретные скрипты, внутри которых глобальный voice route не должен вмешиваться.
Пример:
protectedScripts: [
"VoiceInput_Processor",
"RAG:DetectIntent_and_FindChunks",
"STT:Transcriptions"
]Это полезно, когда вы хотите очень точно указать:
-
вот эти конкретные сценарии нельзя перебивать;
-
если пользователь прислал голос в этот момент, глобальный route должен промолчать.
Это самый точный уровень защиты.
2. Защита целого flow
Через protectedFlows можно защитить сразу целый контур сценариев.
Пример:
protectedFlows: ["corp_entry_flow"]Это удобнее, когда у вас много скриптов внутри одного процесса и не хочется перечислять их по одному.
Например:
-
идёт профилирование;
-
или onboarding;
-
или голосовое интервью;
-
или сервисный flow из нескольких шагов.
Тогда проще сказать:
если пользователь внутри этого flow, глобальный voice route не трогает его.
Это более высокий и более удобный уровень защиты.
3. Глобальное отключение
Через VoiceInput.disable(lead) можно вообще выключить глобальный voice input для пользователя.
Это самый широкий уровень контроля.
Как лучше мыслить про уровни защиты
Практически удобно думать так:
-
если нужно точечно — защищайте конкретные
scripts; -
если нужно защитить процесс целиком — используйте
protectedFlows; -
если нужно отключить механику вообще — используйте глобальный disable через
VoiceInput.
То есть логика идёт:
script → flow → global
Как настроить глобальный голосовой маршрут
Чтобы глобальный голосовой перехват вообще работал, нужно создать отдельный route в боте.
Этот маршрут должен быть:
-
с высоким приоритетом;
-
активен в диалоге;
-
доступен на любом вводе;
-
расположен выше обычных маршрутов;
-
слушать вообще любой входящий input.
Что указать в route
Регулярное выражение
Для глобального перехвата используйте:
:FLAGS[EMPTY,ANY]Это позволяет маршруту реагировать на любой ввод, а уже внутри VoiceRouteGuard.inspect() решать, нужно ли что-то делать именно с этим сообщением.
Что должно быть в condition script
В condition script маршрута нужно вызвать VoiceRouteGuard.inspect(...).
Именно он определяет:
-
голос это или нет;
-
можно ли его сейчас перехватывать;
-
не запрещён ли текущий контекст.
К какому скрипту должен вести маршрут
Этот глобальный маршрут должен быть прикреплён к отдельному скрипту обработки голосового маршрута.
То есть логика такая:
Любой вход
→ глобальный route
→ VoiceRouteGuard.inspect()
→ если true
→ переход в voice-routing scriptА уже внутри этого voice-routing script вы можете:
-
распознать голос;
-
проанализировать intent;
-
определить, что сказал пользователь;
-
перевести его в нужный flow или нужный сценарий бота.
Это уже не просто распознавание аудио, а глобальная голосовая маршрутизация.
Пример логики глобального voice route
Практически это может выглядеть так:
-
Пользователь находится где угодно в боте
-
Отправляет голосовое сообщение
-
Глобальный маршрут ловит любой input
-
VoiceRouteGuard.inspect()проверяет контекст -
Если можно — управление уходит в специальный сценарий
-
Там голос распознаётся и дальше маршрутизируется по смыслу
Например:
-
пользователь сказал “хочу поговорить про цены”;
-
или “мне нужна помощь по заказу”;
-
или “переведи меня в другой раздел”.
После этого бот может сам определить intent и включить нужную логику.
Flow Context
Чтобы VoiceRouteGuard понимал, в каком процессе сейчас находится пользователь, используется компонент FlowContext.
Что это
FlowContext — это простой платформенный компонент для хранения текущего flow в lead.
Он сам по себе не делает маршрутизацию.
Он просто записывает идентификатор текущего контекста, чтобы другие компоненты могли на него опираться.
Где находится
Пакет: Platform
Полное имя: Common.Platform.FlowContext
Подключение:
const FlowContext = require("Common.Platform.FlowContext")Как использовать
Когда вы хотите управлять тем, в каком flow сейчас находится пользователь, устанавливайте FlowContext в entry script сценария.
Пример:
const FlowContext = require("Common.Platform.FlowContext")
FlowContext.set(lead, "corp_entry_flow")После этого VoiceRouteGuard сможет использовать protectedFlows не “вслепую”, а по реальному текущему состоянию пользователя.
Зачем это нужно
Если у вас длинный сценарный контур из нескольких скриптов, гораздо удобнее защитить один flow, чем перечислять все скрипты вручную.
То есть для управления защищёнными flow используйте именно FlowContext.
Практический паттерн такой:
-
при входе в сценарный контур установить
FlowContext.set(...) -
в
VoiceRouteGuard.inspect()указать этот flow вprotectedFlows -
при выходе из контура — очистить flow, если нужно
Как очистить flow
const FlowContext = require("Common.Platform.FlowContext")
FlowContext.clear(lead)Когда использовать локальный Voice Input, а когда глобальный Voice Route Guard

Это два разных паттерна.
Используйте VoiceInput.expect(), когда:
-
сценарий явно ждёт голосовой ответ;
-
пользователь отвечает на конкретный вопрос;
-
голос — это локальный шаг внутри flow;
-
вы строите интервью, onboarding, профилирование, анкету.
Используйте VoiceRouteGuard, когда:
-
хотите слушать голос глобально по всему боту;
-
хотите сделать voice routing;
-
пользователь может в любой момент “переключиться на голос”;
-
голосовое сообщение должно вести в отдельный сценарий обработки.
Очень часто в одном проекте используются оба режима:
-
локальный voice input внутри специальных сценариев;
-
и глобальный voice route поверх всей системы.
Как отлаживать Voice Input и Voice Route Guard
При проблемах с голосовым пайплайном проверяйте систему по слоям.

1. Настройки канала
Проверьте, что в канале включены:
-
Реакция на аудио:
Штатная (NLP и меню) -
Реакция на голосовые сообщения:
Штатная (NLP и меню)
2. Processor script
Убедитесь, что существует скрипт:
VoiceInput_Processorи внутри него есть две команды:
-
Run JavaScript Callback -
Run asynchronous API-request
3. Bot attrs
Проверьте:
-
METABOT_API_TOKEN -
METABOT_SERVER_DOMAIN
4. STT token
Проверьте, что tokenKey указывает на существующий bot-атрибут с ключом провайдера.
5. Source и target attrs
Убедитесь, что:
-
в
sourceAttrсохранилась ссылка на файл; -
в
targetAttrсохранился распознанный текст.
6. Логика guard
Если глобальный voice route не срабатывает, проверьте:
-
что route стоит высоко в списке;
-
что у него regex
:FLAGS[EMPTY,ANY]; -
что condition script вызывает
VoiceRouteGuard.inspect(...); -
что голосовой ввод глобально не отключён через
VoiceInput.disable(lead); -
что пользователь не находится в
protectedFlow; -
что текущий callback / script не защищён через
protectedScripts.
7. Дальнейший AI-анализ
Если после распознавания текста вы передаёте результат в LLMQuery, дальнейшую диагностику смотрите уже в разделе про:
-
LLMQuery -
трассировку
-
LLMClient -
observability
Кратко
Voice Route Guard — это компонент защиты и маршрутизации для глобального голосового ввода.
Он позволяет:
-
слушать голосовые сообщения глобально;
-
защищать отдельные скрипты;
-
защищать целые flow;
-
учитывать глобальное включение и выключение voice input;
-
аккуратно встраивать голосовой роутинг в уже работающего бота.
А FlowContext помогает управлять тем, какой сценарный контур сейчас активен у пользователя, чтобы voice routing был точным и не ломал текущую логику.
Что изучать дальше
Если вы уже разобрались с VoiceInput, дальше логично изучить следующие компоненты Metabot Agent Stack:
LLMQuery
Если вы ещё не знакомы с ним — это следующий обязательный шаг.
Именно он позволяет превращать распознанную речь в:
-
structured JSON,
-
intent,
-
summaries,
-
профили,
-
отражения,
-
управляемые AI-ответы.
Knowledge Base Search
Если вы хотите, чтобы после голосового ввода система не только анализировала речь, но и опиралась на знания компании, изучите компонент поиска по базе знаний.
Трассировка и observability
Если вы строите реальные AI-сценарии, обязательно изучите:
-
трассировку,
-
observability,
-
диагностику вызовов,
-
таблицы логов.
LLMClient
Если вам нужен более глубокий инженерный контроль над transport layer, callback, provider behavior и логикой работы моделей, переходите к низкоуровневому компоненту LLMClient.
Prompt Registry
Если вы хотите выносить промпты из кода и управлять ими централизованно, следующий полезный раздел — Prompt Registry.
MultiVoiceInput — сбор нескольких голосовых сообщений в одну коллекцию
Пакет: Voice
Полное имя компонента: Common.Voice.MultiVoiceInput
Текущая версия в приложенном срезе: 0.1
Базовый компонент для понимания: VoiceInput
Рекомендуем ознакомиться с базовым уроком по голосовому вводу: VoiceInput.
Что это
MultiVoiceInput — это высокоуровневый компонент Metabot для сбора нескольких голосовых сообщений подряд внутри сценария.
Он нужен, когда пользователю неудобно или неестественно укладывать весь ответ в одно голосовое.
Например, человек начал рассказывать задачу, потом вспомнил важную деталь, потом отправил ещё одно голосовое, потом ещё одно. Обычный VoiceInput ждёт одно сообщение и после распознавания сразу переводит сценарий дальше. MultiVoiceInput работает иначе: он собирает несколько голосовых в одну коллекцию, распознаёт каждое, сохраняет общий текст и завершает сбор только после команды вроде “готово”.
Базовый паттерн компонента в исходнике описан так: collect() ждёт voice / video_note / audio, отправляет файл в STT, добавляет результат в collectionAttr, обновляет fullTextAttr, ждёт следующее голосовое, а фраза “готово” завершает сбор и переводит сценарий в successScript.
Проще говоря:
VoiceInput = одно голосовое → один текст → следующий сценарий
MultiVoiceInput = несколько голосовых → коллекция текстов → общий full_text → следующий сценарий
Когда использовать MultiVoiceInput
MultiVoiceInput нужен там, где пользователь должен рассказать что-то свободно и развёрнуто, но может делать это частями.
Типовые кейсы:
AI Intake;
голосовая диагностика бизнеса;
бриф на разработку;
сбор обратной связи;
интервью эксперта;
профилирование пользователя;
разбор проблемы в поддержке;
онбординг партнёра;
подготовка к LLM-анализу;
сбор контекста перед routing / CRM / оффером.
Например, в AI Intake мы просим пользователя рассказать, что он хочет улучшить через AI, какие системы уже есть, где теряются деньги, время, заявки или знания. Человек может отправить 2–5 голосовых подряд, а уже после этого сценарий отправит общий текст в LLMQuery.
Чем MultiVoiceInput отличается от VoiceInput
VoiceInput — это базовый компонент голосового ввода. Он принимает одно голосовое сообщение, распознаёт его и сохраняет результат в один атрибут. Подробнее про философию, пользу, pipeline, настройки канала и базовый processor script смотрите в основной статье:
MultiVoiceInput не заменяет этот урок. Он продолжает ту же архитектурную идею.
Разница такая:
VoiceInput:
- один пользовательский голосовой ответ;
- один targetAttr;
- один sourceAttr;
- после STT сразу successScript.
MultiVoiceInput:
- несколько голосовых подряд;
- collectionAttr со списком всех элементов;
- fullTextAttr с общим текстом;
- sourceUrlsAttr со списком источников;
- countAttr с количеством голосовых;
- statusAttr со статусом сбора;
- завершение по finish phrase, лимиту maxItems или лимиту длительности.
То есть MultiVoiceInput — это не просто “ещё один STT”. Это компонент для голосовой сессии, где пользователь может дать контекст кусками.
Общая схема работы
Сценарий
→ MultiVoiceInput.collect()
→ ожидание voice / video_note / audio
→ callback от мессенджера
→ получение файла
→ отправка в STT
→ callback от STT
→ добавление item в коллекцию
→ обновление full_text
→ ожидание следующего голосового
→ пользователь пишет “готово”
→ сбор завершается
→ переход в successScript
В рабочем AI Intake reference project компонент используется именно так: сценарий берёт текущий номер раунда, запускает сбор 1–5 голосовых, сохраняет транскрипты в round-specific attrs и после завершения переводит пользователя в сценарий LLM-анализа.
Где находится компонент
Подключение:
const MultiVoiceInput = require("Common.Voice.MultiVoiceInput")
Запуск:
return MultiVoiceInput.collect({...})
Есть alias:
MultiVoiceInput.start({...})
В текущем исходнике start() является алиасом на collect().
Что нужно настроить перед использованием
Перед использованием MultiVoiceInput должны быть готовы те же базовые вещи, что и для VoiceInput.
1. Настройки канала
Для Telegram-контура проверьте, что канал обрабатывает голосовые штатно:
Реакция на аудио:
Штатная (NLP и меню)
Реакция на голосовые сообщения:
Штатная (NLP и меню)
Это базовое требование голосового ввода: если голосовые не попадают в сценарий, компонент не сможет их обработать. Основная статья по VoiceInput отдельно описывает эту настройку канала.
2. Processor script
Нужен системный сценарий, обычно:
MultiVoiceInput_Processor
Он должен содержать две команды.
3. Bot attrs
Минимально нужны:
METABOT_API_TOKEN
METABOT_SERVER_DOMAIN
OPENAI_API_KEY
OPENAI_API_KEY используется через tokenKey в STT-настройках. METABOT_API_TOKEN и METABOT_SERVER_DOMAIN нужны для callback-механики, как и в обычном VoiceInput.
Processor script
MultiVoiceInput работает через системный processor script. Он нужен потому, что компонент проходит несколько фаз: сначала ждёт сообщение от пользователя, потом получает файл, потом отправляет его в STT, потом ждёт async callback с текстом.
Processor script должен содержать две команды.
Команда 1. Callback от мессенджера
Тип команды:
Run JavaScript Callback
Код:
const MultiVoiceInput = require("Common.Voice.MultiVoiceInput")
return MultiVoiceInput.onCallback({ lead, isFirstImmediateCall })
Эта команда:
показывает wait-сообщение;
ждёт голосовое / video_note / audio;
проверяет finish phrases;
проверяет stop phrases;
проверяет help phrases;
проверяет add more phrases;
валидирует файл;
готовит текущий файл для STT.
Команда 2. Callback от STT
Тип команды:
Run asynchronous API-request
Код:
const MultiVoiceInput = require("Common.Voice.MultiVoiceInput")
return MultiVoiceInput.onSTT({ lead, isFirstImmediateCall })
Эта команда:
инициирует STT;
ждёт async response;
получает распознанный текст;
добавляет item в collection;
обновляет fullTextAttr;
обновляет countAttr;
если лимит не достигнут — возвращает пользователя к ожиданию следующего голосового;
если лимит достигнут — завершает сбор.
В reference project MultiVoiceInput_Processor устроен именно так: первая команда вызывает onCallback, вторая — onSTT.
Пример использования
const MultiVoiceInput = require("Common.Voice.MultiVoiceInput");
return MultiVoiceInput.collect({
code: "demand_voice_diagnostic_intake",
lead,
successScript: "demand_voice_intake1_analyze",
cancelScript: "demand_voice_diagnostic_cancelled",
errorScript: "demand_voice_diagnostic_voice_error",
collectionAttr: "demand_voice_intake1_items_json",
fullTextAttr: "demand_voice_intake1_full_text",
sourceUrlsAttr: "demand_voice_intake1_source_urls_json",
countAttr: "demand_voice_intake1_count",
statusAttr: "demand_voice_intake1_status",
minItems: 1,
maxItems: 5,
maxTotalDurationSec: 900,
extraAttrs: {
active_agent: "metabot_intake",
voice_context: "demand_voice_diagnostic",
input_mode: "multi_voice_intake"
},
processorScript: "MultiVoiceInput_Processor",
stt: {
provider: "openai",
options: {
model: "whisper-1",
language: "ru"
},
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
},
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
},
minDurationSec: 5,
maxDurationSec: 600,
maxFileSizeBytes: 20 * 1024 * 1024
},
messages: {
wait: "🎙 Пришлите голосовое сообщение. Можно несколько подряд.",
accepted: "✅ Принял голосовое. Расшифровываю…",
afterItem: "Принял. Можете прислать ещё одно голосовое или написать «готово».",
wrong: "Нужна голосовуха. Если закончили — напишите «готово».",
empty: "Пока нет ни одного голосового. Пришлите хотя бы одно сообщение.",
canceled: "Ок, остановились.",
finished: "Спасибо. Собрал контекст.",
tooMany: "Я уже собрал достаточно материала. Сейчас соберу картину.",
stillProcessing: "⏳ Ещё обрабатываю предыдущее голосовое…"
},
finishPhrases: [
"готово",
"всё",
"все",
"закончил",
"закончила",
"/done"
],
stopPhrases: [
"стоп",
"stop",
"отмена",
"cancel",
"я передумал",
"/cancel"
]
});
В текущем исходнике обязательными являются processorScript, successScript, cancelScript, collectionAttr, fullTextAttr и stt.tokenKey; также проверяется, что minItems >= 1, а maxItems >= minItems.
Важное замечание по свежести примеров
В некоторых переходных примерах может встречаться вложенный блок:
voiceInput: {
processorScript: "MultiVoiceInput_Processor",
stt: {...},
constraints: {...}
}
Но в текущем срезе компонента Common.Voice.MultiVoiceInput основные настройки processorScript, stt и constraints находятся на верхнем уровне конфигурации. Поэтому при новом внедрении сверяйте вызов с актуальной версией плагина на платформе.
Для production используйте свежую версию компонента из платформы, а приложенный reference project воспринимайте как рабочий срез на дату.
Что сохраняет компонент
MultiVoiceInput сохраняет несколько типов результата.
collectionAttr
JSON-массив всех распознанных голосовых.
Пример:
[
{
"index": 1,
"type": "voice",
"text": "Хочу внедрить AI в продажи...",
"source_url": "https://...",
"duration_sec": 42,
"file_size": 123456,
"file_id": "abc",
"created_at": "2026-06-03T...",
"transcribed_at": "2026-06-03T..."
},
{
"index": 2,
"type": "voice",
"text": "Ещё важно, что у нас есть CRM...",
"source_url": "https://...",
"duration_sec": 31,
"file_size": 100000,
"file_id": "def",
"created_at": "2026-06-03T...",
"transcribed_at": "2026-06-03T..."
}
]
В исходнике каждый распознанный элемент добавляется как item с индексом, типом файла, текстом, ссылкой на источник, длительностью, размером, file_id и timestamp-полями.
fullTextAttr
Обычный текстовый атрибут, где все голосовые объединены в один текст.
Формат текущей сборки:
[Голосовое 1]
Текст первого голосового
[Голосовое 2]
Текст второго голосового
Компонент строит fullTextAttr из массива items, соединяя распознанные тексты через пустую строку.
sourceUrlsAttr
JSON-массив ссылок на исходные голосовые файлы.
countAttr
Количество принятых голосовых.
statusAttr
Текущий статус сбора.
Возможные статусы:
active
collecting
completed
cancelled
Основные параметры collect()
code
Уникальный код сессии сбора.
Пример:
code: "demand_voice_diagnostic_intake"
Для повторяемых раундов удобно использовать динамический код:
const roundCode = `demand_intake_round${currentRound}`;
lead
Обязательный объект текущего лида.
lead
Если lead не передан, компонент выбросит ошибку.
processorScript
Код системного processor script.
processorScript: "MultiVoiceInput_Processor"
successScript
Сценарий, куда перейти после успешного завершения сбора.
successScript: "demand_intake_analyze_round"
cancelScript
Сценарий, куда перейти при отмене.
cancelScript: "demand_intake_cancelled"
errorScript
Сценарий для ошибки. В текущей конфигурации параметр есть в API и используется как часть маршрутов, но конкретную обработку ошибок нужно проверять по актуальной версии компонента.
collectionAttr
JSON-атрибут для массива всех голосовых.
collectionAttr: "demand_intake_round1_items_json"
fullTextAttr
Текстовый атрибут с объединённой расшифровкой.
fullTextAttr: "demand_intake_round1_full_text"
sourceUrlsAttr
JSON-атрибут со ссылками на исходные файлы.
sourceUrlsAttr: "demand_intake_round1_source_urls_json"
countAttr
Атрибут с количеством голосовых.
countAttr: "demand_intake_round1_count"
statusAttr
Атрибут со статусом.
statusAttr: "demand_intake_round1_status"
extraAttrs
Дополнительные атрибуты, которые компонент устанавливает в lead.
Пример:
extraAttrs: {
active_agent: "metabot_intake",
voice_context: "demand_intake_loop",
input_mode: "multi_voice_intake_round"
}
В reference project через extraAttrs также сохраняются контекст раунда и entry-данные вроде route, funnel_id и campaign.
Лимиты
minItems
Минимальное количество голосовых, которое нужно принять до завершения.
minItems: 1
Если пользователь напишет “готово” до первого голосового, компонент покажет messages.empty.
maxItems
Максимальное количество голосовых.
maxItems: 5
Если пользователь достиг лимита, компонент показывает messages.tooMany и завершает сбор автоматически.
maxTotalDurationSec
Максимальная суммарная длительность всех голосовых.
maxTotalDurationSec: 900
Это полезно, чтобы пользователь не отправил слишком много материала в один раунд.
constraints.minDurationSec
Минимальная длительность одного файла.
minDurationSec: 5
constraints.maxDurationSec
Максимальная длительность одного файла.
maxDurationSec: 600
constraints.maxFileSizeBytes
Максимальный размер файла.
maxFileSizeBytes: 20 * 1024 * 1024
Компонент проверяет размер, минимальную и максимальную длительность файла и возвращает пользователю понятное предупреждение, если файл не проходит ограничения.
Типы файлов
По умолчанию:
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
}
}
Это значит:
voice — принимаем;
video_note — принимаем;
audio — не принимаем.
Если нужно принимать обычные аудиофайлы, включите:
audio: true
Но для Telegram voice-first сценариев обычно лучше начинать с voice и video_note.
STT-настройки
Пример:
stt: {
provider: "openai",
tokenKey: "OPENAI_API_KEY",
asyncResponse: true,
options: {
model: "whisper-1",
language: "ru"
}
}
Поля:
provider — STT-провайдер;
tokenKey — имя bot attr, где лежит ключ провайдера;
asyncResponse — использовать async callback;
options.model — модель распознавания;
options.language — язык.
Если stt.tokenKey не указан, компонент выбросит ошибку конфигурации.
UX-сообщения
Блок messages отвечает за пользовательские тексты.
Основные поля:
messages: {
wait: "🎙 Пришлите голосовое сообщение. Можно несколько подряд.",
accepted: "✅ Принял голосовое. Расшифровываю…",
afterItem: "Принял. Можете прислать ещё одно голосовое или написать «готово».",
wrong: "Нужна голосовуха. Если закончили — напишите «готово». Если хотите отменить — напишите «стоп».",
empty: "Пока нет ни одного голосового. Пришлите хотя бы одно сообщение.",
canceled: "Ок, остановились.",
finished: "Спасибо. Собрал контекст. Сейчас разложу задачу по карте.",
tooMany: "Я уже собрал достаточно материала. Сейчас соберу картину.",
tooLongTotal: "Материала уже достаточно по длительности. Сейчас соберу картину.",
stillProcessing: "⏳ Ещё обрабатываю предыдущее голосовое…",
transcriptionEmpty: "⚠️ Не удалось получить текст из голосового. Попробуйте записать ещё раз.",
help: "..."
}
Сценарист может переопределить только нужные сообщения. Остальные возьмутся из defaults.
Управляющие фразы
finishPhrases
Фразы завершения сбора:
finishPhrases: [
"готово",
"всё",
"все",
"закончил",
"закончила",
"/done"
]
Когда пользователь пишет такую фразу, компонент проверяет, есть ли минимум minItems, завершает сбор, ставит статус completed и запускает successScript.
stopPhrases
Фразы отмены:
stopPhrases: [
"стоп",
"stop",
"отмена",
"cancel",
"я передумал",
"/cancel"
]
При такой фразе компонент ставит статус cancelled, очищает активную конфигурацию и запускает cancelScript.
addMorePhrases
Фразы “добавить ещё”:
addMorePhrases: [
"добавить ещё",
"добавить еще",
"еще",
"ещё"
]
Компонент просто продолжает ждать голосовое.
helpPhrases
Фразы помощи:
helpPhrases: [
"как записать голосовое",
"помощь",
"help",
"/help"
]
Компонент отправляет messages.help.
В исходнике фразы нормализуются: текст приводится к нижнему регистру, лишние символы убираются, поддерживается точное совпадение и совпадение по началу фразы, чтобы варианты вроде “готово, собрать картину” тоже могли сработать.
Пример для AI Intake-раунда
const MultiVoiceInput = require("Common.Voice.MultiVoiceInput");
const currentRound = parseInt(lead.getAttr("demand_intake_round") || "1");
const roundCode = `demand_intake_round${currentRound}`;
return MultiVoiceInput.collect({
code: roundCode,
lead,
successScript: "demand_intake_analyze_round",
cancelScript: "demand_intake_cancelled",
errorScript: "demand_intake_voice_error",
collectionAttr: `demand_intake_round${currentRound}_items_json`,
fullTextAttr: `demand_intake_round${currentRound}_full_text`,
sourceUrlsAttr: `demand_intake_round${currentRound}_source_urls_json`,
countAttr: `demand_intake_round${currentRound}_count`,
statusAttr: `demand_intake_round${currentRound}_status`,
minItems: 1,
maxItems: 5,
maxTotalDurationSec: 900,
extraAttrs: {
active_agent: "metabot_intake",
voice_context: "demand_intake_loop",
input_mode: "multi_voice_intake_round",
demand_intake_round: currentRound,
demand_intake_round_code: roundCode
},
processorScript: "MultiVoiceInput_Processor",
stt: {
provider: "openai",
options: {
model: "whisper-1",
language: "ru"
},
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
},
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
},
minDurationSec: 5,
maxDurationSec: 600,
maxFileSizeBytes: 20 * 1024 * 1024
},
messages: {
wait: "🎙 Ответьте голосом. Можно несколькими сообщениями подряд.",
accepted: "✅ Принял голосовое. Расшифровываю…",
afterItem: "Принял. Можете записать ещё одно голосовое или нажать/написать «готово».",
wrong: "Нужна голосовуха. Если хотите остановиться — нажмите/напишите «готово».",
empty: "Пока нет ни одного голосового. Пришлите хотя бы одно сообщение.",
canceled: "Ок, остановились.",
finished: "Спасибо. Собрал контекст.",
tooMany: "Я уже собрал достаточно материала. Сейчас обновлю картину.",
stillProcessing: "⏳ Ещё обрабатываю предыдущее голосовое…"
},
finishPhrases: [
"готово",
"всё",
"все",
"закончил",
"закончила",
"дальше",
"давай дальше",
"/done"
]
});
В AI Intake reference project этот подход используется для каждого раунда: номер раунда читается из demand_intake_round, а результаты пишутся в demand_intake_round{N}_items_json, demand_intake_round{N}_full_text, demand_intake_round{N}_source_urls_json, demand_intake_round{N}_count и demand_intake_round{N}_status.
Что делать после MultiVoiceInput
После успешного завершения сбора обычно запускается сценарий анализа.
Например:
demand_intake_analyze_round
Он берёт:
demand_intake_round{N}_full_text
и отправляет этот текст в LLMQuery.
То есть MultiVoiceInput сам не анализирует смысл. Он только собирает и распознаёт голосовые. Анализ, JSON-сигнатура, follow-up, routing и CRM — это следующие слои сценария.
Правильное разделение:
MultiVoiceInput — собрать голосовые и full_text.
LLMQuery — понять смысл и вернуть JSON.
After-analysis — показать пользователю локализованный результат.
Routing — выбрать следующий шаг.
CRM / менеджер — получить внутренний бриф.
Как отлаживать
Отлаживать нужно по слоям.
1. Пользователь попал в collect script?
Проверить, что запустился сценарий, где вызывается:
MultiVoiceInput.collect({...})
2. Активная конфигурация создана?
Проверить lead attr:
__active_multi_voice_input
Если его нет, сбор не запущен или уже очищен.
3. Processor script существует?
Проверить сценарий:
MultiVoiceInput_Processor
В нём должны быть две команды: onCallback и onSTT.
4. Голосовое принято?
Проверить:
collectionAttr
countAttr
statusAttr
Если countAttr = 0, голосовое не добавилось в коллекцию.
5. STT вернул текст?
Проверить:
fullTextAttr
collectionAttr
Если в collectionAttr есть item без текста или fullTextAttr пустой, проблема на STT-слое.
6. Сохранились source URLs?
Проверить:
sourceUrlsAttr
Если пусто, возможно, проблема с получением ссылки на файл.
7. Завершение сработало?
Пользователь пишет:
готово
Проверить:
statusAttr = completed
и что запустился successScript.
8. Если пользователь пишет “готово”, но сбор не завершается
Проверить:
finishPhrases;
minItems;
countAttr;
__active_multi_voice_input;
processorScript;
onCallback.
Если minItems = 1, а голосовых ещё нет, компонент должен показать messages.empty.
9. Если бот пишет “нужна голосовуха”
Проверить:
тип входящего сообщения;
constraints.allow.voice;
constraints.allow.video_note;
constraints.allow.audio;
настройки канала;
payload мессенджера.
10. Если STT не стартует
Проверить:
stt.provider;
stt.tokenKey;
bot attr OPENAI_API_KEY;
Run asynchronous API-request;
METABOT_API_TOKEN;
METABOT_SERVER_DOMAIN.
Типовые ошибки
Ошибка 1. Создали collect script, но забыли processor
Без MultiVoiceInput_Processor компонент не сможет принять голос и получить STT callback.
Ошибка 2. Настроили processor как обычный JavaScript
Первая команда должна быть Run JavaScript Callback, вторая — Run asynchronous API-request.
Ошибка 3. Не задали collectionAttr или fullTextAttr
Компонент требует эти поля, потому что ему нужно сохранить коллекцию и общий текст.
Ошибка 4. Пользователь пишет “готово”, но ещё не отправил голосовое
При minItems: 1 компонент не завершит сбор и покажет messages.empty.
Ошибка 5. Не локализовали UX под конкретный сценарий
Default-сообщения подходят для тестов, но в production лучше писать контекстно:
“Расскажите задачу голосом. Можно несколькими сообщениями подряд.”
Ошибка 6. Смешали MultiVoiceInput и LLM-анализ
MultiVoiceInput не должен решать бизнес-задачу. Его задача — собрать голосовые и подготовить текст.
Ошибка 7. Не проверили свежую версию компонента
Приложенный код — срез. Перед внедрением сверяйте актуальную версию плагина и параметры вызова.
Короткий production checklist
1. Канал принимает voice / video_note.
2. Создан MultiVoiceInput_Processor.
3. В processor есть onCallback.
4. В processor есть onSTT.
5. Настроены METABOT_API_TOKEN и METABOT_SERVER_DOMAIN.
6. Настроен OPENAI_API_KEY или другой tokenKey.
7. В collect() указан lead.
8. Указан successScript.
9. Указан cancelScript.
10. Указан collectionAttr.
11. Указан fullTextAttr.
12. Указаны sourceUrlsAttr / countAttr / statusAttr, если нужны для отладки.
13. minItems >= 1.
14. maxItems >= minItems.
15. Настроены finishPhrases.
16. Настроены stopPhrases.
17. Проверено, что fullTextAttr собирается из нескольких голосовых.
18. Проверено, что “готово” переводит в successScript.
19. Проверено, что после successScript данные уходят в LLMQuery / следующий сценарий.
Главный вывод
MultiVoiceInput нужен, когда одного голосового недостаточно.
Он позволяет превратить живой человеческий рассказ, разбитый на несколько сообщений, в один структурированный вход для следующего сценарного слоя.
Формула:
несколько голосовых
→ STT каждого сообщения
→ collectionAttr
→ fullTextAttr
→ successScript
→ LLMQuery / routing / CRM
Базовую философию голосового интерфейса, настройки канала и общую механику VoiceInput смотрите в основной документации:
https://docs.metabot24.ru/books/06-ai-komponenty-metabot-agent-stack/page/voice-input-golosovoi-interfeis-dlya-ai-voronok
VoiceInput даёт один голосовой ответ.
MultiVoiceInput даёт голосовую сессию.
Для кругозора
ИИ-трансформация в AI-First компанию
Metabot AI Methodology
Методология поэтапного перехода к AI-First компании. Данная методология — не просто “технология внедрения ИИ”, а методология эволюциии компании в сторону AI-first мышления.
Цель
Показать, как компания проходит путь от экспериментов с ИИ — к состоянию AI-First-организма,
где интеллект встроен в культуру, процессы и управление.
Мы создаём систему, в которой:
-
Люди понимают и принимают ИИ, используют как партнёра в работе;
-
Знания становятся обновляемым корпоративным интеллектом и активом компании;
-
Процессы автоматизируются и усиливаются ИИ;
-
Смыслы выравнивают действия людей и машин;
-
Операции становятся самообучающимися, предиктивными и управляемыми ИИ;
-
Бизнес становится устойчивым в новой эпохе Интеллектизма.
Проблема
Большинство компаний застревают между “хотим ИИ” и “умеем использовать ИИ”.
Типичные барьеры:
-
Сотрудники не понимают, зачем им ИИ, или боятся его.
-
Знания разбросаны по людям и файлам, нет структуры.
-
Процессы не прозрачны, данных много, смысла мало.
-
IT и бизнес говорят на разных языках.
💡 Результат: нет ROI, нет эффекта, нет синхронизации.
💡 Принцип: «от людей к смыслам»
ИИ внедряется не сверху, а через культуру, структуру и смыслы.
Это не установка чат-ботов — это изменение когнитивного устройства компании.
Структура методологии
Методология строится поэтапно — от людей и знаний к смыслам и операционному управлению:
|
№ |
Этап |
Фокус и Результат |
|
1️⃣ AI Awakening (пробуждение) |
Люди и культура |
Принятие и вовлечённость: осознание, вовлечение, освоение ИИ; формируется язык и мастер-промпты. |
|
2️⃣ AI Structuring (структурирование) |
Знания и онтология |
Создаётся корпоративный интеллект и когнитивный слой: карта смыслов, структура связей, корпоративная память. |
|
3️⃣ AI Integration (интеграция) |
Процессы и интерфейсы |
Автоматизация и скорость: ИИ встраивается в рабочие места и пайплайны, рождается операционный интеллект. |
|
4️⃣ AI Alignment (выравнивание) |
Смыслы и цели |
Выравнивание человеческих и машинных контекстов; компания становится когнитивной системой. |
|
5️⃣ AI Operations (операции) |
Операционный и аналитический слои |
ИИ наблюдает за собой и за миром, анализирует потоки данных и участвует в принятии решений. |
⚙️ Этапы ИИ-трансформации
1️⃣ AI Awakening — пробуждение и культура
Люди. Понимание. Первое “вау”.
📍 Цель: вовлечь сотрудников, показать, что ИИ — это не угроза, а усиление. Снять страх, дать ощущение “WOW, это работает!”.
Что делаем:
- Обучаем сотрудников основам работы с LLM (ChatGPT, Claude, JustAI и др.);
- Создаём мастер-промпты — профили ролей (менеджер, инженер, маркетолог и т.д.);
- Формируем единый AI-глоссарий компании — как называть процессы, клиентов, продукты;
- Проводим сессии «ИИ в моей работе» — сотрудники описывают, где им помогает ИИ;
- Начинаем первичный майнинг знаний: собираем кейсы, вопросы, файлы, тексты.
Ключевой инструмент:
Master Prompt — описание контекста роли, компании, целей, языка и ценностей.
Это как «память сотрудника», с которой ИИ потом работает осмысленно.
Результат:
Появляется Prompt-first культура, сотрудники видят эффект и начинают применять ИИ ежедневно.
Формируется первый слой общей памяти компании.
2️⃣ AI Structuring — структурирование знаний
Знания. Онтология. Память компании.
📍 Цель: превратить корпоративную экспертизу в когнитивную базу знаний.
Что делаем:
-
Инвентаризация документов и опыта.
-
Разделение на домены (продажи, производство, монтаж, HR и т.д.).
-
Создание онтологий и графов смыслов (RAG, GraphRAG).
-
Настройка векторной базы знаний и метаданных.
-
Интеграция с языковыми моделями.
Результат:
ИИ знает структуру компании, понимает контекст и помогает искать, советовать, учить.
3️⃣ AI Integration — интеграция в процессы
Процессы. Инструменты. Автоматизация.
📍 Цель: встроить ИИ в ежедневные рабочие процессы.
Что делаем:
-
Разработка Low-Code пайплайнов (заявки, контент, коммуникации).
-
Интеграция с CRM, ERP, BI, ServiceDesk.
-
Создание цифровых рабочих мест (React / Next.js / Metabot).
-
Автоматизация типовых операций и отчётов.
Результат:
ИИ становится частью операционки, ускоряет взаимодействия, снижает нагрузку и ошибки.
Компания получает измеримый эффект и метрики производительности.
4️⃣ AI Alignment — выравнивание смыслов
Когнитивный слой. Общий язык. Коллективный интеллект.
📍 Цель: согласовать людей, ИИ и цели в едином смысловом поле.
Что делаем:
-
Создаём когнитивную карту компании: стратегия → действия → результаты.
-
Формируем общий язык и смысловые паттерны.
-
Внедряем AI-хабы и среды коллективного мышления.
-
Настраиваем петлю самообучения — обратная связь в онтологию.
Результат:
Компания мыслит коллективно.
ИИ помогает выравнивать приоритеты и координировать решения.
Формула выравнивания:
AI Alignment = Common Space + Shared Language + Collective Tools
5️⃣ AI Operations — операционное управление
Наблюдение. Аналитика. Самообучение.
📍 Цель: создать операционный уровень, где ИИ наблюдает, анализирует и управляет.
Компоненты:
-
Sensor Fabric — сбор сигналов из систем, чатов, процессов.
-
Signal Quantization — квантование опыта компании.
-
Analytical Core — причинно-следственный анализ, ML-модели, прогнозирование.
-
Rule Engine — правила реакции на сигналы и событийные цепочки.
-
Feedback Loop — обратная связь в когнитивный слой.
Результат:
Создаётся замкнутый контур осознанности:
Событие → Осмысление → Реакция → Обучение.
Компания начинает “чувствовать” свои процессы, предсказывать и адаптироваться.
Это уровень настоящего AI-First-организма.
Эволюция ИИ-зрелости компании
| Уровень | Что это значит | Пример |
|---|---|---|
| 1. AI-Curious | Люди экспериментируют с ИИ | “О, он пишет письма!” |
| 2. AI-Enabled | Есть мастер-промпты и гайды | Внутренний FAQ |
| 3. AI-Structured | База знаний и онтология | Ассистент знает компанию |
| 4. AI-Integrated | ИИ встроен в процессы | Генерация документов |
| 5. AI-Aligned | Выравнивание смыслов | AI-директор, когнитивная аналитика |
| 6. AI-Operations | ИИ участвует в управлении | Предиктивное управление и оптимизация |
🧭 Формула
ИИ = Люди × Знания × Процессы × Смыслы × Операции
Методология Metabot делает компанию AI-First:
мы учим людей, структурируем знания, создаём онтологию,
интегрируем ИИ в процессы и выравниваем смыслы —
превращая организацию в живую, обучающуюся систему.
FAQ
1. Что такое онтология?
Онтология — это структурная карта знаний компании.
Она показывает:
- какие сущности у вас есть (продукты, клиенты, задачи, процессы),
- как они связаны,
- какие данные и документы их описывают,
- и как эти связи влияют на смысл ответов AI.
Примеры:
- В монтажной отрасли: Материал → Инструмент → Тип помещения → Звукоизоляция → Ошибка монтажа
- В продажах: Клиент → Сегмент → Продукт → Возражение → Решение → Результат
- В контенте: Продукт → Тема → Канал → Формат → CTA → Голос бренда
Когда ИИ знает структуру мира компании, он перестаёт “галлюцинировать” и начинает мыслить как ваш сотрудник.
Что делаем
- Проводим инвентаризацию знаний (файлы, документы, инструкции, переписки);
- Разделяем всё на домены (продажи, монтаж, маркетинг, сбыт, HR и т.д.);
- Создаём семантические модели (RAG) — как искать и цитировать знания;
- Добавляем метаданные: источники, авторы, версии, статусы;
- Формируем граф онтологий (Graph-RAG) — связи между областями;
- Обучаем команду добавлять знания и править онтологию без разработчиков.
Почему это важно
Онтология делает ответы ИИ:
- точнее (понимает связи и контекст),
- прозрачнее (можно объяснить, откуда ответ),
- расширяемыми (добавление нового домена не ломает старые связи).
Результат:
- Формируется живая корпоративная база знаний;
- Появляется архитектура данных и смыслов;
- Компания начинает управлять знанием как активом.
2. Как создается пятый слой?
Пятый слой основан на теории сознания и концепции квантующего наблюдателя от Юрия Гарашко, и позволяет создать архитектуру “сознания” предприятия:
- Мир даёт бесконечный поток сигналов.
- Система квантует опыт с разной частотой (секунды, минуты, сутки).
- На стыке разных темпоральностей возникает “точка сознания” — синхронизация опыта.
Это и есть момент субъективности, когда система понимает, что происходит — она различает свои состояния во времени.
Универсальное применение
Эта архитектура применима везде, где есть:
- сложные процессы и циклы (производство, логистика, энергетика);
- наблюдение за состоянием систем (оборудование, транспорт, клиенты);
- необходимость прогнозировать и оптимизировать.
То есть в любой отрасли, где важны сигналы, связи и решения.
Критерии готовности компании к AI-First трансформации
Почему большинству это не удастся (99 из 100 бизнесов пока не готовы)
1. Что такое AI-First трансформация
AI-First — это не про “добавить нейросеть”.
Это переход к управлению бизнесом, где:
- данные становятся нервной системой,
- алгоритмы — исполнительной силой,
- а люди — источником смысла и обучения.
AI-First-компания — это не та, где “внедрили ChatGPT”,
а та, где каждый процесс, решение и коммуникация проходят через слой данных и автоматизации.
2. Кому это не подойдёт
ИИ не спасает от бардака — он масштабирует бардак.
Если в компании:
- хаос в процессах,
- данные разбросаны по Excel-файлам,
- нет единых стандартов учёта,
- решения принимаются “по звонку”,
- культура — оборонительная и токсичная,
то внедрение ИИ не только не поможет,
а поставит компанию перед зеркалом, где отразится вся некомпетентность.
ИИ — не чудо, а усилитель.
Он усиливает то, что уже есть: структуру, если она есть; хаос, если его больше.
3. Культурная готовность
AI-First требует внутреннего взросления компании:
- готовности прозрачно смотреть на цифры (без “отмазок” и искажений),
- доверия к данным,
- открытости к изменениям,
- понимания, что ИИ не заменяет людей, а убирает рутину,
оставляя людям смысловые и управленческие задачи.
Там, где люди боятся ИИ, обычно боятся не технологии —
они боятся, что система покажет, кто реально работает, а кто — имитирует.
4. Техническая готовность
Чтобы внедрять ИИ, нужно хотя бы базово:
- Оцифровать процессы.
Каждое действие — транзакция, лог, событие.
Без этого нечего анализировать и автоматизировать. - Создать единое пространство данных.
CRM, ERP, чаты, производственные системы должны говорить на одном языке. - Стандартизировать точки взаимодействия.
Форматы заявок, статусы, метрики, API. - Назначить владельцев процессов.
Без ответственных лиц ИИ будет просто набором скриптов.
5. Как внедрять: три шага
Шаг 1. Наведи порядок.
Оцифруй бизнес-функции: продажи, поддержку, производство, коммуникации.
Определи, где теряются данные и где повторяются ручные операции.
Шаг 2. Определи цели.
Не “внедрить ИИ”, а зачем:
- сократить издержки на обработку обращений,
- повысить конверсию,
- улучшить планирование запасов,
- ускорить принятие решений.
Шаг 3. Встраивай локально.
ИИ внедряется в конкретные процессы, где есть данные и критерии результата.
Например:
- автоматизация ответов в поддержке,
- прогноз сбоев оборудования,
- генерация отчётов,
- анализ воронки продаж.
6. Что измерять
Не “инновационность” и “красоту дашбордов”, а эффект на деньги и время:
|
Метрика |
Вопрос |
|
💰 Экономический эффект |
Сколько затрат или человеко-часов сняли? |
|
⚙️ Эффективность |
Сколько операций теперь без участия человека? |
|
⏱ Скорость |
На сколько ускорилось принятие решений или выполнение? |
|
❤️ Удовлетворённость клиентов/сотрудников |
Улучшилось ли качество взаимодействия? |
ИИ внедряется не ради ИИ.
Он внедряется ради экономии, скорости и ясности.
7. Ошибки, которых стоит избежать
- “Купить ИИ, чтобы был.”
- “Дать задачу ИИ-отделу” (без участия бизнес-руководителей).
- “Построить ИИ-проект без данных.”
- “Ожидать магии от ChatGPT, когда бардак в CRM.”
- “Бояться, что ИИ заменит людей.”
8. Когда всё готово
Когда процессы прозрачны, данные связаны, команда осознаёт ценность ИИ —
тогда начинается настоящая AI-First-трансформация.
ИИ перестаёт быть “внедрением” и становится фоном,
через который протекает весь бизнес.
📍 Вывод:
ИИ не делает компанию умной.
Он просто показывает, насколько она уже умна.
Мировой опыт ИИ-трансформации
Мир стремительно перестраивается под AI-first-парадигму — модель, в которой искусственный интеллект становится не инструментом, а ядром управления, восприятия и координации бизнеса. За последние два года десятки консалтинговых компаний, интеграторов и стартапов опубликовали свои версии «AI-операционной системы» — от enterprise brain до cognitive layer.
Чтобы понять, где сегодня находится индустрия, мы собрали обзор ведущих игроков, исследовательских направлений и инвестиционных тенденций, связанных с построением AI-first-организаций.
1️⃣ Консалтинг и корпоративные модели
Крупнейшие консалтинговые дома уже сформировали собственные методологии AI-трансформации.
BCG говорит об AI-first как о новой операционной модели, где интеллект становится «нервной системой бизнеса». BCG Henderson Institute описывает компанию будущего как организм, в котором AI — мозг, а люди — сенсоры и толкователи сигналов.
Deloitte Netherlands развивает эту идею в сторону организационной структуры: автономная операционная модель, outcome-driven управление, лидер-оркестратор и обучающаяся рабочая сила. В их материалах AI трактуется как соприродная часть операционного цикла, а не внешняя функция.
Infosys продвигает подход Live Enterprise: создание «живого цифрового ядра», где процессы адаптируются в реальном времени.
EY, PwC, Accenture и McKinsey (QuantumBlack) строят инфраструктуру масштабирования моделей и внедряют принципы «ответственного AI» — они видят трансформацию не в экспериментах, а в полном пересмотре цепочек создания ценности.
2️⃣ Стартапы и технологические платформы
На уровне стартапов и системных интеграторов фокус смещается к когнитивным слоям — надстройкам, которые соединяют данные, модели и бизнес-контекст.
-
NexusOne создаёт «интеллектуальный слой», объединяющий данные из любых систем и превращающий их в AI-ready контекст.
-
CognitiveX строит концепцию Living Cognitive Memory — живой памяти, которая «помнит и думает» поверх существующих приложений.
-
Peak.ai применяет когнитивный слой в производстве: AI-агенты управляют запасами и планированием, делая цепочки поставок самонастраивающимися.
-
Innovoe определяет когнитивный слой как «интеллектуальный посредник между инструментами и процессами» — универсальную шину смыслов.
-
HyperC переносит принципы агентного AI в розничную торговлю, создавая Large Retail Model для автономного ценообразования и replenishment.
-
AI-First Consulting (Канада) формирует программы для SMB — от обучения лидеров до внедрения prompt-first культуры и метрик эффективности.
Все эти проекты сходятся в одном: AI перестаёт быть “приложением” и становится инфраструктурой мышления компании.
3️⃣ Академия и white papers
Исследователи формулируют технический фундамент этой эволюции.
-
IBM (Cognitive Database, 2017) впервые описала, как добавить семантическое мышление в СУБД: поиск по смыслам, аналогии, предсказания.
-
W3C (Cognitive AI, 2020) представила архитектуру Sentient Web с уровнями perception → cognition → action и концепцией cognitive database.
-
AIMultiple (2024) выделила семь слоёв agentic AI, где ключевым стал слой Cognition & Reasoning — память, embedding-хранилища и оркестрация агентов.
-
NASSCOM (The Agent Stack) ввёл термин enterprise brain — когнитивный слой, который «видит, понимает и действует» поверх корпоративных систем.
Эти работы постепенно формируют новую архитектуру предприятия — наблюдающую, рассуждающую и действующую систему, а не просто хранилище данных.
4️⃣ Prompt-First культура и Master Prompts
С появлением генеративных моделей в 2024–2025 гг. возникла новая управленческая парадигма: prompt-first culture.
Вместо задач — вопросы, вместо инструкций — контексты.
-
На Substack и в корпоративных блогах описывают ритуалы ревью промптов, метрики их эффективности и библиотеки “master-promptов”.
-
AvePoint подчёркивает, что доверие к AI начинается, когда лидеры сами промптят публично.
-
Tiago Forte & Hayden Miyamoto предложили метод Master Prompt — ядро AI-операционной системы компании, где зашиты цели, язык и ценности бизнеса.
Это направление напрямую резонирует с этапом AI Awakening методологии Metabot — когда сотрудники учатся не “пользоваться ChatGPT”, а мыслить в формате диалога с интеллектом.
5️⃣ Инвестиционные и рыночные тенденции
Инвесторы уже формируют капитал под новый цикл.
-
Y Combinator финансирует более 1000 AI-стартапов, отбирая тех, кто строит AI как фундамент бизнеса, а не функцию.
-
Andreessen Horowitz (a16z) концентрируется на продуктах, где AI управляет физическим миром — робототехника, логистика, индустрия. Планирует фонд в $20 млрд, целиком посвящённый AI.
-
Felicis Ventures, Unusual Ventures, Moonfare и другие фонды трактуют AI как новую производственную технологию, на уровне электричества или интернета.
Финансовый фокус смещается с инфраструктуры на когнитивные системы — там, где AI не только считает, но и принимает решения.
6️⃣ Что это значит для нас
AI-first перестаёт быть лозунгом.
Это новая операционная парадигма, где данные, процессы и люди соединены смыслом, а интеллект — распределён по всей компании.
Сегодня рынок предлагает фрагменты этой картины:
-
BCG и Deloitte — методологию управления;
-
Infosys и Accenture — технологические ядра;
-
CognitiveX и Peak.ai — когнитивные слои;
-
Tiago Forte и prompt-сообщества — культуру мышления.
Но целостные модели, соединяющие людей, знания, процессы, смыслы и операционный интеллект, пока редкость.
Metabot предлагает как раз такую структуру:
пять слоёв эволюции — от Awakening к Structuring, Integration, Alignment и Operations — превращающих организацию в живой AI-First организм, где интеллект встроен в саму ткань управления.
Обзор MAS (старая версия)
Обзор разработки ИИ-агентов на Metabot
Введение
Metabot — это универсальная low-code / full-code платформа, объединяющая возможности чат-ботов, интеграций и backend-автоматизации.
Она служит коммуникационным и интеграционным ядром, где можно проектировать бизнес-процессы, собирать ассистентов и подключать внешние сервисы.
На этой основе создан Metabot Agent Stack (MAS) — фреймворк для разработки интеллектуальных ассистентов и мультиагентных систем, где можно:
-
подключать любые LLM;
-
интегрировать базы знаний;
-
строить цепочки reasoning;
-
и управлять всем этим без кода.
MAS использует компоненты платформы (скрипты, атрибуты, API-шлюзы, базу знаний, трассировку) и расширяет их возможностями работы с LLM, RAG-поиском и reasoning-цепочками.
Именно связка Metabot + MAS превращает платформу из конструктора чат-ботов в инфраструктуру для создания ИИ-агентов, способных взаимодействовать с данными, людьми и процессами.
Основные компоненты
Все компоненты вместе формируют Metabot Agent Stack (MAS):
| Компонент | Назначение |
|---|---|
| Run asynchronous API-request | Команда для выполнения асинхронного API-запрос c замыканием состояния на текущей команде и ожиданием результата выполнения запроса. Через нее происходит обращение к LLM. |
| LLMClient | Универсальный компонент для работы с языковыми моделями (OpenAI, Claude, YandexGPT, GigaChat и др.) через API. Поддерживает синхронные и асинхронные запросы. |
| Snippets | Параметризуемые фрагменты кода и настроек, которые позволяют конфигурировать агента под конкретный проект. |
| Knowledge Base | База знаний на PostgreSQL с поддержкой PgVector. Позволяет хранить документы, разрезать их на чанки, векторизировать и выполнять семантический поиск. |
| KnowbaseSearch | Компонент для RAG-поиска (Retrieval Augmented Generation). Ищет релевантные фрагменты знаний и формирует контекст для LLM. |
| Custom Tables | Пользовательские таблицы для хранения данных, промптов и контекстов. |
| Txt Importer | Скрипт для импорта текстовых файлов, разрезки на чанки и векторизации (эмбеддинги). |
| Tracing | Встроенная трассировка запросов и ответов LLM — для отладки и анализа reasoning-процессов. |
| API/Webhooks | Встроенные средства интеграции с внешними системами и сервисами. |
Как работает агент в Metabot
Создание ИИ-агента в Metabot строится вокруг сценария (script). Сценарий описывает последовательность шагов взаимодействия с пользователем и внешними системами.
-
Пользователь пишет сообщение в чат (Telegram, WebChat, WhatsApp).
-
Скрипт получает это сообщение и вызывает LLMClient внутри команды Выполнить асинхронный API-запрос — формируется запрос (prompt) к языковой модели.
-
Ответ модели возвращается в нужную точку сценария и используется для следующего шага.
Пример логики:
Пользователь задаёт вопрос → скрипт вызывает LLMClient → LLM обращается к базе знаний → формируется ответ → отправляется пользователю.
Таким образом, агент — это цепочка вызовов между пользователем, памятью, моделью и логикой сценария.
📚 Работа с базой знаний
Metabot поддерживает векторную базу знаний с возможностью гибридного поиска.
-
Импорт данных: файлы (PDF, TXT, DOCX) можно загружать через Txt Importer, который разбивает их на чанки и векторизирует.
-
Поиск: компонент KnowbaseSearch позволяет выполнять семантический поиск (по смыслу), а компонент кастомной таблицы позволяет реализовать поиск по точному совпадению.
-
Контекст: найденные фрагменты подаются в LLM, обеспечивая точные и осмысленные ответы.
Конфигурация и хранение настроек
Все параметры агента — ключи API, идентификаторы моделей, пути к данным — сохраняются в атрибутах бота. Это делает систему безопасной и удобной для тиражирования проектов.
Для каждого ассистента можно хранить:
-
параметры LLM;
-
промпты и конфигурации;
-
параметры подключения к базам знаний;
-
контексты для разных режимов общения.
Отладка и трассировка
Для разработки ИИ-агентов крайне важно видеть, почему модель дала тот или иной ответ. В Metabot встроена система трассировки:
-
журнал запросов и ответов;
-
сохранение контекста промптов;
-
визуальная отладка reasoning-потока.
Это помогает быстро улучшать промпты и повышать точность ответов.
Интеграции и API
Metabot легко соединяется с внешними системами:
-
CRM
-
ERP и LMS
-
DataLens, Google Sheets, SQL-базы
-
API партнёров и внутренних сервисов
Встроенные Low-code возможности позволяют строить интеграции без необходимости писать сложный backend.
📎 Полезные уроки и материалы
📚 Смотрите также:
Metabot Agent Stack (MAS)
Мир переходит от интерфейсов кликов к взаимодействию с ИИ через естественный язык. Ассистенты и агенты становятся основой нового поколения программ — они умеют понимать контекст, учиться и действовать.
Но как программировать таких агентов — без сложной архитектуры и кода?
Ответ — MAS (Metabot Agent Stack). Это не просто набор инструментов.
MAS — это фреймворк проектирования разумных агентов, встроенный в инфраструктуру Metabot.
Что такое MAS
MAS (Metabot Agent Stack) — это архитектурный стек, который объединяет:
-
🧠 LLM‑интеграцию (OpenAI, Claude, GigaChat, Gemini и др.);
-
📚 векторные базы знаний (PgVector, ClickHouse, Elastic);
-
⚙️ Low‑code/Full-code сценарии и скрипты на JavaScript;
-
🔀 интеграцию с API и CRM/ERP системами;
-
🗂️ память и атрибуты для хранения контекста;
-
🛰️ агентные пайплайны и маршрутизацию намерений.
MAS разворачивается поверх платформы Metabot и превращает её из конструктора чат‑ботов в полноценную мультиагентную среду.
Архитектура MAS
MAS построен по принципу мультиагентных пайплайнов, где каждый агент выполняет конкретную роль, а их взаимодействие обеспечивает целостное поведение системы.
| Компонент | Назначение |
|---|---|
| Intent Router | Анализирует запрос пользователя и направляет его в нужный агент. |
| RAG‑агент | Извлекает информацию из внутренних документов, формирует контекст и передаёт в LLM. |
| SQL‑агент | Строит SQL‑запросы к базам данных и формирует аналитические ответы. |
| Knowledge Base Search | Обеспечивает семантический поиск по базе знаний. |
| LLMClient | Управляет вызовами языковых моделей и их конфигурацией. |
| Snippets | Хранят параметры, промпты и настройки агента. |
| Tracing | Отслеживает взаимодействия и reasoning‑потоки между агентами. |
MAS поддерживает работу в мессенджерах, web‑чатах, корпоративных интерфейсах и может интегрироваться с BI‑инструментами и DataLens.
MAS vs другие фреймворки
| Функциональность | MAS (Metabot) | LangChain/LangGraph | LlamaIndex | Botpress / Rasa |
| Память и контекст | ✅ | ⚠️ вручную | ⚠️ ограничено | ✅ FSM |
| Поддержка RAG | ✅ | ✅ | ✅ | ⚠️ частично |
| Асинхронность | ✅ | ⚠️ зависит от infra | ⚠️ | ⚠️ |
| Flow Logic | ✅ (визуально) | ⚠️ вручную | ⚠️ | ✅ |
| Интеграции (API, CRM, SQL) | ✅ встроенные | ❌ | ⚠️ | ⚠️ |
| JS + Low‑Code | ✅ | ❌ (Python) | ❌ (Python) | ✅ |
| Поддержка мессенджеров | ✅ | ❌ | ❌ | ✅ |
| Запуск без кода | ✅ | ❌ | ❌ | ⚠️ |
MAS занимает нишу между классическими LLM‑фреймворками и бизнес‑платформами:
он даёт архитектурную гибкость LangChain/LangGraph, но упрощает программирование.
🧬 MAS как философия
“Нейросети не мыслят. Интеллект рождается в инфраструктуре вокруг них.”
— Юрий Гарашко, «Сети жизни vs Deep Learning»
MAS воплощает идею событийно‑коммуникативной архитектуры:
агент не существует изолированно, а живёт в потоке событий, контекстов и действий.
Каждый агент хранит собственную память, имеет зону ответственности и взаимодействует через Intent Router.
Вся система строится вокруг атрибутов лида — единой модели состояния, что позволяет связывать диалоги, данные и действия без написания backend‑кода.
Что даёт MAS разработчикам и бизнесу
-
Быстрая сборка LLM‑ассистентов под любые задачи.
-
Поддержка RAG‑поиска и работы с корпоративными базами.
-
Интеграция с CRM, ERP, LMS, аналитикой и BI‑дашбордами.
-
Автоматизация поддержки, обучения и документооборота.
-
Простое масштабирование от одного агента к мультиагентной сети.
MAS позволяет компаниям перейти от «чат‑ботов с ИИ» к когнитивным операционным системам — где агенты не просто отвечают, а управляют процессами и принимают решения.
📚 Рекомендуемые материалы
Следующий шаг: изучите уроки по MAS и попробуйте создать собственного агента — участника предстоящего Баттла ассистентов и рыцарей!
Документация и уроки (старая версия)
Ядро системы - Маршрутизатор и RAG
Создание основы мультиагентной системы
Архитектура системы
В основе нашей мультиагентной системы лежит Маршрутизатор - это "диспетчер", который анализирует вопрос пользователя и решает, какой именно агент должен его обработать. По умолчанию система использует RAG для поиска информации в базе знаний.
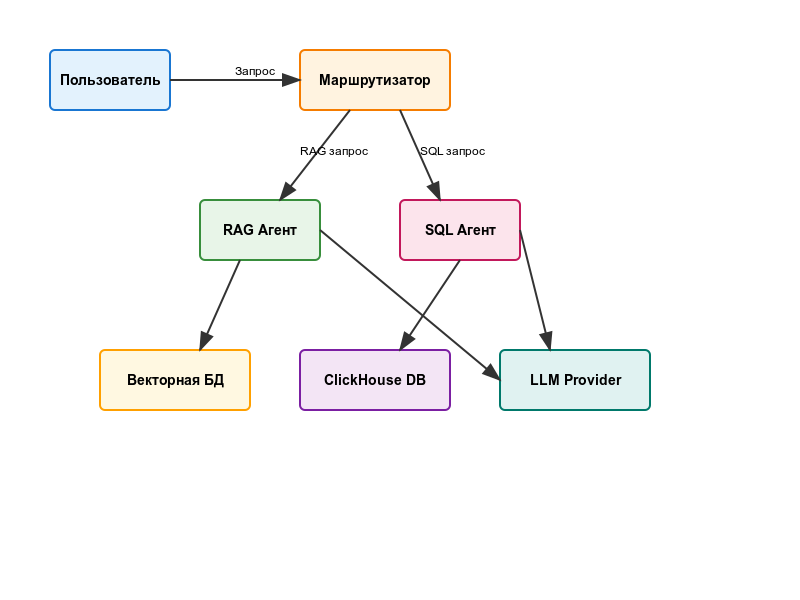
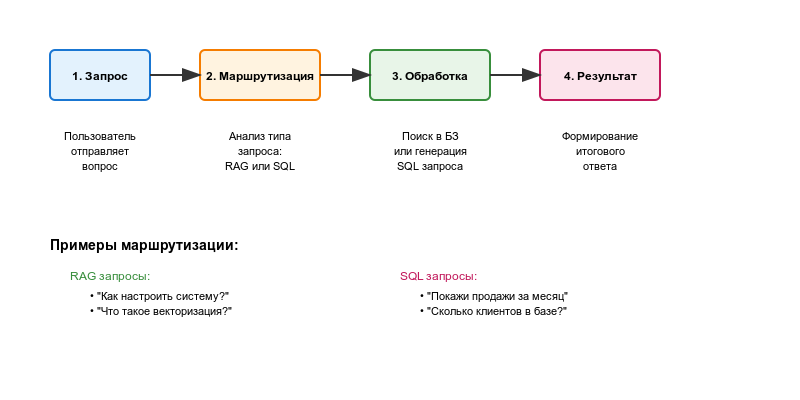
Каждый агент выполняет свою специализированную задачу:
- CompanyInfo - отвечает на вопросы о компании
- SQL-агент - работает с базами данных
Часть 1: Установка и настройка основного агента
Шаг 1: Импорт готового решения
Мы подготовили готовую конфигурацию, которую можно быстро развернуть:
- Перейдите по предоставленной ссылке для скачивания конфигурации
- Скопируйте JSON-код конфигурации
- В интерфейсе Метабот откройте раздел "Импорт бизнеса/ботов"
- Вставьте скопированный JSON и нажмите "Импорт"
Шаг 2: Проверка установленных компонентов
После успешного импорта в вашем боте должны появиться следующие элементы:
1. Системный раздел MRAG Это ядро системы, которое обрабатывает запросы и управляет агентами.

2. Базовые таблицы данных:
gpt_knowledge_base- хранилище знаний для RAGgpt_prompts- коллекция промптов для разных агентов
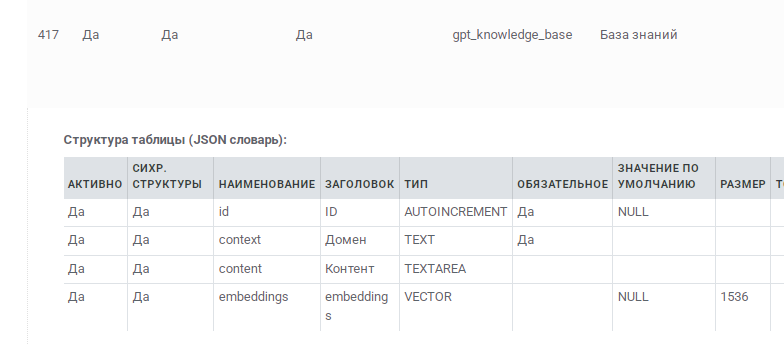
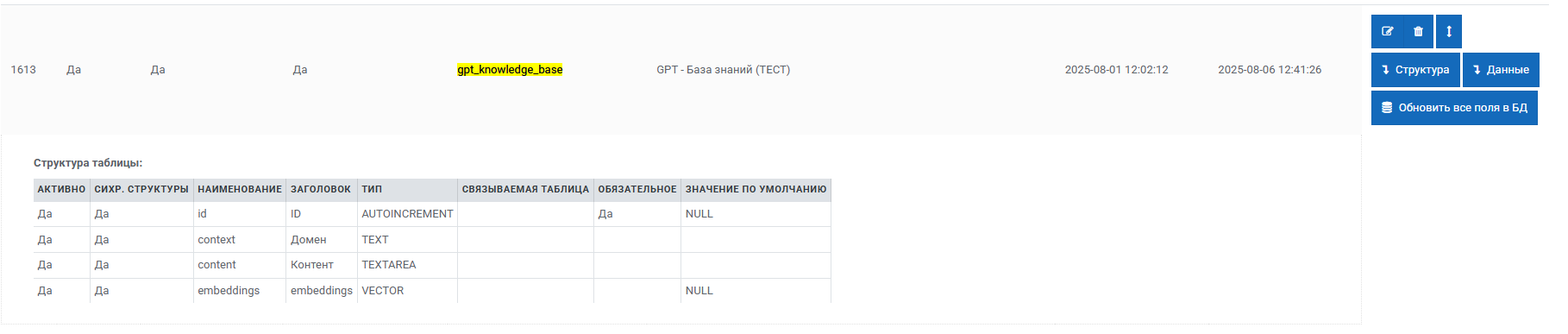
3. Плагин управления "AgentsParams" Центр управления всеми настройками агентов.

Шаг 3: Настройка конфигурации агентов
Мы создали систему конфигураций, которая позволяет управлять агентами без глубокого понимания кода. Все настройки вынесены в понятные конфигурационные файлы.
Совет для работы: В конфигурации есть множество параметров. Используйте поиск по документации, чтобы быстро найти описание нужного параметра и понять, как он работает.
Основные поля конфигурации:
let activeAgent = lead.getAttr("activeAgent") // Устанавливается при вызове скрипта
let agentCFG = {} // Объект с настройками текущего агента
if (activeAgent === "MainFlow") {
agentCFG = {
common: {
title: "Основной Flow c маршрутизатором", // Понятное название агента
agentName: "MainFlow", // Техническое имя для системы
promptTable: "gpt_prompts", // Таблица с промптами
userQueryAttibName: "user_query", // Атрибут для вопроса пользователя
historyMaxLength: 4, // Сколько сообщений помнить в истории
exitScript: "KB:FollowUp", // Что выполнить после завершения диалога
},
detectRoute: { // Настройки маршрутизатора
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
prompt: "$route_prompt", // Промпт для определения маршрута
routerTools: [{
tools: "RAG_Tools", // Набор доступных инструментов
route: "RAG:DetectIntent_and_FindChunks", // Скрипт для RAG
}],
errorScript: "RAG:ErrorFallback", // Обработка ошибок
},
detectIntent: { // Детектор намерений пользователя
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
prompt: "$rag_intent_prompt", // Промпт для анализа намерений
errorScript: "RAG:ErrorFallback",
kbName: "defKnowBase", // База знаний
kbDomain: "main", // Домен знаний
},
userReply: { // Генератор ответов пользователю
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
errorScript: "RAG:ErrorFallback",
useHistory: 1, // Использовать контекст диалога
addUserQuery: 1, // Добавлять вопрос в промпт
sendBotAnwser: 1, // Отправлять ответ пользователю
systemPrompts: { // Структура промптов
start: [["$start_prompt", "$rag_prompt"]], // Начальные промпты
final: ["$final_prompt"] // Финальные промпты
// Между start и final автоматически вставляется история диалога
},
}
}
} else if (activeAgent === "newAgent") {
// Здесь описываются конфигурации других агентов
// Поля могут отличаться в зависимости от специализации агента
} else {
bot.sendMessage(`MainConfig:snippet - неизвестный activeAgent: ${activeAgent}`)
bot.stop()
}
Шаг 4: Настройка таблицы промптов
Промпты - это инструкции для ИИ. Они определяют, как агент будет вести себя и отвечать на вопросы.
Процедура настройки:
- Откройте таблицу
gpt_promptsв интерфейсе Метабот - Создайте промпт для каждого агента с уникальным именем
- Заполните три обязательных поля:
agent_name- имя агента (например: "MainFlow")name- название промпта (например: "route_prompt")prompt- содержание промпта с макропеременными
Пример настройки промпта маршрутизатора в таблице:
agent_name: MainFlow
name: route_prompt
prompt: Ты агент ИИ который отвечает на вопросы о компании {{@company_name}}.
У тебя есть инструменты в распоряжении:
<tools>
**RAG_Tools** - Используется, когда нужно ответить на вопросы об услугах
и продукции компании, об условиях эксплуатации продукции, об используемых
инструментах для монтажа продукции и т.д.
</tools>
Учитывая историю и запрос пользователя, сделай вывод о реальном намерении
пользователя. Отвечай на русском языке без лишних рассуждений и вопросов.
История чата:
"""{{$chat_history_str}}"""
Запрос пользователя:
"""{{$user_query}}"""
Пожалуйста, отвечай как можно точнее и всегда обязательно указывай инструмент (Tools).
Ответ всегда должен быть представлен в виде JSON-объекта, в котором выводятся
указанные ниже поля. JSON в самом конце! Без пояснений.
{
"tools": "", string: название выбранных вами инструментов
"user_intent": "", string: подробное намерение пользователя для системы RAG
"request": "" "полученный вами запрос"
}
Система макросов в промптах
Для динамической подстановки данных используйте макросы:
Данные из лида: {{$lead_attr}} - любой атрибут лида
Данные из бота: {{@bot_attr}} - любой атрибут бота
Системные макросы:
{{$chat_history_str}}- история диалога в текстовом виде{{$user_query}}- текущий вопрос пользователя
Часть 2: Настройка API-доступа
Шаг 5: Создание API-пользователя
Для работы мультиагентной системы необходимо настроить API-доступ:
- В настройках бизнеса создайте нового пользователя
- Установите галочку "Пользователь API"
- Предоставьте доступ к нужным ботам (всем или выбранным)
- Назначьте соответствующую роль доступа
Генерация токена доступа:
- Создайте API-клиента для пользователя
- Сгенерируйте токен доступа
- Важно: Сохраните токен - он потребуется для подключения к API-шлюзу
- Обязательно: Используйте токен в режиме 3
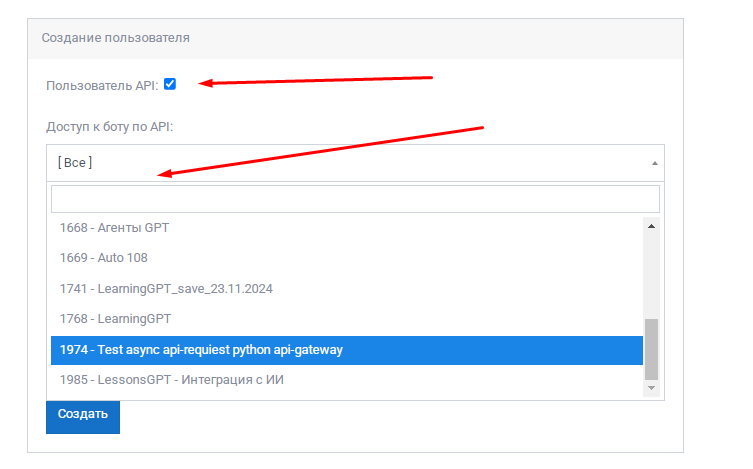
Шаг 6: Регистрация в API-шлюзе
API-шлюз обеспечивает асинхронное взаимодействие между компонентами системы.
- Обратитесь в поддержку. Сейчас регистрация производится специалистами Метабот.
- Сообщите им параметры регистрации:
bot_id- идентификатор вашего ботаtoken- токен API, полученный на предыдущем шагеdomain- доменное имя сервера, где размещен бот. Напримерhttps://app.metabot24.com
Часть 3: Запуск и тестирование
Шаг 7: Создание пользовательского интерфейса
Создайте скрипт, который позволит пользователям взаимодействовать с системой:
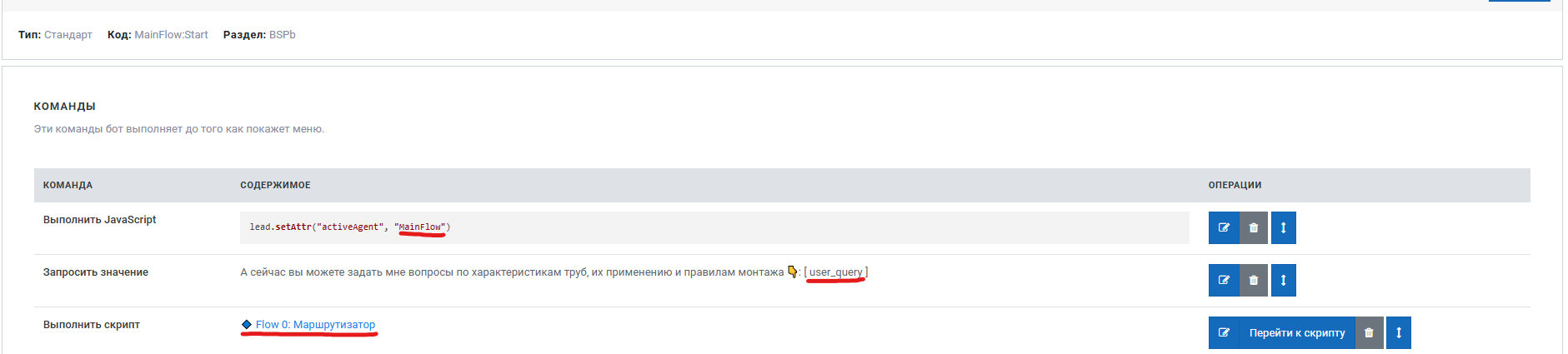
Ключевые параметры запуска:
- MainFlow - выбор основного агента для обработки запроса
- user_query - атрибут для сохранения вопроса пользователя
- Flow 0 - запуск скрипта маршрутизатора
Результат работы системы
При правильной настройке ваша мультиагентная система будет:
- Понимать контекст диалога и поддерживать связную беседу
- Автоматически определять наиболее подходящий агент для каждого вопроса
- Использовать базу знаний для предоставления точных ответов
- Обращаться к специализированным агентам при необходимости (SQL-агент, CompanyInfo и др.)
Система готова к работе и может быть расширена дополнительными агентами в зависимости от ваших потребностей.
Создание простого агента
Введение
После того как основная мультиагентная система запущена и работает, добавление новых агентов становится простой задачей. Мы создаем специализированных помощников, каждый из которых решает определенный круг задач.
В этом разделе мы создадим агента CompanyInfo, который будет отвечать исключительно на вопросы о компании - контакты, адреса офисов, время работы. Особенность этого агента в том, что он не обращается к RAG базе знаний, а хранит всю информацию прямо в промпте. Это упрощает работу модели и ускоряет получение ответов.
Этап 1: Подготовка информации о компании
Создание промпта с данными компании
Первым делом подготовим базовый промпт с информацией о компании. Назовем его about_prompt:
_**ЦЕНТРАЛЬНЫЙ ОФИС**_
**Контакты**
Адрес: 123456, г. Примерск, ул. Центральная, дом 10А
Горячая линия: 8 800 000 00 00 (бесплатно по России)
Часы работы: пн-вс с 9:00 до 21:00
**Отдел качества:** +7 (900) 123-45-67
Часы работы: пн-вс с 9:00 до 21:00
**Интернет-банк:** 8 804 000 11 11
**Главный офис обслуживания, пос. Банковский**
Адрес: 140000, Примерская область, г. Финансск, д. Кредитное,
ул. Сберегательная, д.1, стр. 1
Телефон: +7 (900) 765-43-21
Часы работы: пн-пт c 9:00 до 18:00
**Склад документов «ПримерБанк»**
Адрес: Россия, 140001, Примерская область, рп. Храновск,
ул. Архивная, д. 5
Телефон: +7 (900) 111-22-33
Часы работы: пн-чт 9.00-18.00, пт 9.00-16.30
Подробнее: https://primerbank.ru/contacts
---
_**ОФИСЫ В РЕГИОНАХ**_
**Воронеж**
394000, г. Примероград, ул. Финансовая, 8, оф. 101
Тел.: +7 (902) 234-56-78
**Екатеринбург**
620000, г. Примерск-Урал, ул. Сибирская, 22, оф. 5
Тел.: +7 (903) 345-67-89
**Краснодар**
350000, г. Примеродар, ул. Южная, 50
Тел.: +7 (904) 456-78-90
Добавление промпта в систему
Откройте таблицу gpt_prompts и создайте новую запись:
- agent_name:
CompanyInfo - name:
about_prompt - prompt: вставьте текст выше
Этап 2: Интеграция агента в систему
Для подключения нового агента нужно выполнить три шага в строгом порядке:
- Конфигурация - описать параметры агента
- Скрипт - создать логику обработки
- Маршрутизация - добавить в систему выбора агентов
Шаг 1: Обновление конфигурации
Откройте плагин AgentsParams и найдите секцию с основным агентом. Нам нужно:
А) Добавить новый инструмент в маршрутизатор
В секции detectRoute найдите routerTools и дополните массив:
detectRoute: {
// ... остальные параметры остаются без изменений
routerTools: [{
tools: "RAG_Tools", // Существующий инструмент
route: "RAG:DetectIntent_and_FindChunks"
}, {
tools: "INFO_Tools", // Новый инструмент для информации о компании
route: "CompanyInfo" // Имя скрипта, который создадим далее
}],
// ... остальные параметры остаются без изменений
}
Б) Создать конфигурацию для нового агента
Добавьте новое условие после основного блока MainFlow:
else if (activeAgent === "CompanyInfo") { // Агент для работы с информацией о компании
agentCFG = {
common: {
title: "About Agent", // Понятное имя агента
agentName: "CompanyInfo", // Техническое имя
promptTable: "gpt_prompts", // Таблица с промптами
userQueryAttibName: "user_query", // Атрибут с вопросом пользователя
historyMaxLength: 4, // Длина истории диалога
exitScript: "MainFlow:FollowUp" // Скрипт завершения
},
userReply: { // Настройки генерации ответов
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
errorScript: "RAG:ErrorFallback", // Обработка ошибок
useHistory: 1, // Использовать историю диалога
addUserQuery: 1, // Добавлять вопрос пользователя
sendBotAnwser: 1, // Отправлять ответ пользователю
systemPrompts: {
start: ["$about_prompt"], // Промпт с информацией о компании
final: [] // Финальные промпты (пустой массив)
// Структура: about_prompt + история диалога
},
}
}
}
Шаг 2: Создание скрипта агента
Создайте новый скрипт с именем CompanyInfo (как указано в конфигурации выше):
// Устанавливаем активного агента
lead.setAttr('activeAgent', 'CompanyInfo')
// Загружаем конфигурацию агента
snippet("Business.AgentsParams.MainConfig")
// Подключаем библиотеку для работы с ИИ
const LLMClient = require("Common.MetabotAI.LLMClient")
// Создаем сессию для генерации ответа
const llm = new LLMClient("UserReply", agentCFG.common.agentName)
// Передаем вопрос пользователя в обработку
llm.addUserQuery(lead.getAttr(agentCFG.common.userQueryAttibName))
// Запускаем генерацию и отправку ответа пользователю
llm.nextFlow("RAG:UserReply")
Как работает этот скрипт:
- Устанавливает режим работы с агентом CompanyInfo
- Загружает его настройки из конфигурации
- Берет вопрос пользователя и передает в ИИ
- Генерирует ответ на основе промпта с информацией о компании
- Запускает скрипт UserReply для отправки ответа пользователю
Шаг 3: Обновление системы маршрутизации
Откройте таблицу gpt_prompts, найдите промпт route_prompt для агента MainFlow и обновите секцию с инструментами:
<tools>
**RAG_Tools** - Используется, когда нужно ответить на вопросы об услугах
и продукции компании, об условиях эксплуатации продукции, об используемых
инструментах для монтажа продукции и т.д.
**INFO_Tools** - Используется когда пользователь хочет узнать о филиалах
компании, контактных данных или времени их работы
</tools>
Этап 3: Тестирование и результат
Запуск системы
После внесения всех изменений запустите бота так же, как в основном примере. Система теперь автоматически:
- Анализирует вопрос пользователя
- Определяет подходящий инструмент (RAG_Tools или INFO_Tools)
- Направляет запрос соответствующему агенту
- Получает точный ответ из подготовленной информации
Примеры работы
Вопросы для CompanyInfo агента:
- "Где находится ваш филиал в Екатеринбурге?"
- "Время работы горячей линии?"
- "Телефон кредитного отдела?"
- "Часы работы московского филиала?"
Вопросы для RAG агента:
- "Какие у вас условия по ипотеке?"
- "Как оформить депозит?"
- "Тарифы на обслуживание карт"
Преимущества такого подхода
- Скорость ответа - информация о компании доступна мгновенно
- Точность - данные всегда актуальные и не зависят от поиска в базе знаний
- Простота поддержки - легко обновить информацию в одном промпте
- Масштабируемость - можно добавить любое количество таких агентов
Ваша мультиагентная система теперь умеет не только искать информацию в документах, но и давать быстрые ответы по заранее подготовленным данным.
Документация по LLMClient
Как работает
LLMClient реализует ключевой паттерн Metabot Agent System (MAS) — фреймворк для построения мультиагентных систем через композицию простых, понятных блоков кода.
MAS следует принципу "сложное через простое":
- Декларативность: Сложные AI-операции описываются простыми, читаемыми выражениями
- Модульность: Каждый flow — независимая единица работы с собственным контекстом
- Прозрачность: Вся логика работы агента видна в коде скрипта/плагина
- Композиция: Сложные мультиагентные сценарии собираются из простых блоков
Методы класса LLMClient
new LLMClient(sessionName, agentName = "", apiFormat = "")
Создаёт новый экземпляр клиента для работы с LLM.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| sessionName | String | Уникальное имя сессии |
| agentName | String | Имя агента (опционально) |
| apiFormat | String | Формат API (опционально) |
Возвращает
LLMClient — экземпляр клиента.
setPromptTable(tableName, agentName)
Устанавливает таблицу промптов и имя агента.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| tableName | String | Имя таблицы промптов |
| agentName | String | Имя агента |
addUserQuery(content)
Сохраняет пользовательский запрос для текущей сессии.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Пользовательский запрос |
getUserQuery()
Получает последний пользовательский запрос.
Параметры
Нет
Возвращает
String — последний пользовательский запрос.
addPrompt(role, content)
Добавляет промпт с указанной ролью.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| role | String | Роль: 'system', 'user', 'assistant' |
| content | String/Array | Текст или массив строк |
addRawPrompts(prompts)
Добавляет массив промптов без обработки.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| prompts | Array | Массив объектов {role, content} |
addSystemPrompt(content)
Добавляет системный промпт.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Системный промпт |
addUserPrompt(content)
Добавляет пользовательский промпт.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Пользовательский промпт |
addAssistantPrompt(content)
Добавляет промпт ассистента.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | String | Промпт ассистента |
addHistoryToPrompts(historyOverride = null)
Добавляет историю сообщений к промптам.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| historyOverride | Array/Null | Массив сообщений или null |
clearPrompts()
Очищает все промпты текущей сессии.
Параметры
Нет
setHistoryMaxLength(lmax)
Устанавливает максимальную длину истории сообщений.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| lmax | Number | Максимальная длина истории |
setHistory(messages)
Сохраняет историю сообщений.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| messages | Array | Массив объектов {role, content} |
getHistory()
Получает историю сообщений.
Параметры
Нет
Возвращает
Array — история сообщений.
addToHistory(message)
Добавляет сообщение в историю.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| message | Object | Объект {role, content} |
disableHistory()
Отключает сохранение истории сообщений.
Параметры
Нет
clearHistory()
Очищает историю сообщений.
Параметры
Нет
getHistoryStr()
Получает историю сообщений в виде строки.
Параметры
Нет
Возвращает
String — история сообщений.
setModel(model)
Устанавливает модель для генерации ответа.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| model | String | Название модели |
setProvider(providerName)
Устанавливает провайдера LLM.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| providerName | String | Название провайдера |
getProvider()
Получает текущего провайдера.
Параметры
Нет
Возвращает
String — название провайдера.
setApiFormat(apiFormat)
Устанавливает формат API.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| apiFormat | String | Формат API |
setModelParams(params)
Устанавливает параметры модели.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| params | Object | Объект с параметрами модели |
setTemperature(temp)
Устанавливает температуру генерации.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| temp | Number | Температура генерации |
getParams()
Получает параметры модели.
Параметры
Нет
Возвращает
Object — параметры модели.
getMessages()
Получает промпты запроса.
Параметры
Нет
Возвращает
Array — промпты запроса.
deleteMessages()
Удаляет промпты запроса.
Параметры
Нет
prepareRequest(callbackScript = null)
Сохраняет промпты и задаёт callback-скрипт.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| callbackScript | String | Код скрипта для обработки ответа (опц.) |
sendRequest()
Отправляет асинхронный запрос к LLM.
Параметры
Нет
Пример
const llm = new LLMClient("DetectIntent")
llm.setModel("gpt-3.5-turbo")
llm.setProvider("OpenAI")
llm.setPromptTable("gpt_prompts", "MyAgent")
llm.addSystemPrompt("$start")
llm.addUserPrompt(`Запрос пользователя: ${lead.getAttr("user_input")}`)
llm.prepareRequest("MyAgent:MyScript")
return llm.sendRequest()
handleResponse()
Обрабатывает ответ от LLM, сохраняет результат и историю.
Параметры
Нет
setErrorScript(scriptCode)
Назначает fallback-скрипт при ошибке.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| scriptCode | String | Код скрипта для обработки ошибки |
getErrorScript()
Получает fallback-скрипт.
Параметры
Нет
Возвращает
String — код fallback-скрипта.
setFallbackConfig(scriptCode, timeout)
Настраивает резервный сценарий и таймаут.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| scriptCode | String | Код резервного скрипта |
| timeout | Number | Таймаут в секундах |
scheduleFallback()
Запланировать отложенный запуск fallback-скрипта.
Параметры
Нет
unscheduleFallback()
Удалить отложенный запуск fallback-скрипта.
Параметры
Нет
getResponseResult()
Получает результат запроса (объект ответа провайдера).
Параметры
Нет
Возвращает
Object — объект ответа провайдера.
getProviderResult()
Получает "сырые" данные от провайдера.
Параметры
Нет
Возвращает
Object — исходные данные от провайдера.
getResponseText()
Извлекает текст ответа из результата.
Параметры
Нет
Возвращает
String — текст ответа.
extractAnswerForModel(content)
Извлекает ответ по формату модели.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| content | Object | Объект ответа провайдера |
getModelContextSize(modelName = null)
Получает максимальный размер контекста модели.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| modelName | String | Название модели или null |
Возвращает
Number — максимальный размер контекста.
getLastJSON(text = null)
Извлекает JSON из текста ответа.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| text | String | Текст ответа или null |
Возвращает
Object — найденный JSON.
extractTextWithoutJSON(text = null)
Удаляет JSON из текста и возвращает чистый текст.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| text | String | Текст ответа или null |
Возвращает
String — текст без JSON.
removeMarkdownHeaders(text = null)
Удаляет заголовки Markdown из текста.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| text | String | Текст ответа или null |
Возвращает
String — текст без заголовков.
getAgentAnswer(agentName)
Получает ответ агента по имени.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| agentName | String | Имя агента |
Возвращает
String — ответ агента.
getLastTokenUsage()
Получает статистику токенов последнего запроса.
Параметры
Нет
Возвращает
Object — статистика токенов.
setStatus(status)
Устанавливает статус сессии.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| status | String | Статус: 'IDLE', 'PREPARED', ... |
getStatus()
Получает текущий статус.
Параметры
Нет
Возвращает
String — текущий статус.
clearStatus()
Очищает статус.
Параметры
Нет
nextFlow(scriptCode)
Переходит к следующему flow-скрипту.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| scriptCode | String | Код следующего flow-скрипта |
sendResponse()
Отправляет ответ в лог админа.
Параметры
Нет
sendFormattedResponse(format = 'Markdown')
Отправляет ответ в заданном формате.
Параметры
| Имя | Тип | Описание |
|---|---|---|
| format | String | Формат: 'Markdown', 'HTML', ... |
finishFlow()
Завершает работу сессии.
Параметры
Нет
Примеры использования
const LLMClient = require("Common.MetabotAI.LLMClient")
const llm = new LLMClient("DetectIntent")
llm.setModel("gpt-3.5-turbo")
llm.setProvider("OpenAI")
llm.setPromptTable("gpt_prompts", "MyAgent")
llm.addSystemPrompt("$start")
llm.addUserPrompt(`Запрос пользователя: ${lead.getAttr("user_input")}`)
llm.prepareRequest("MyAgent:MyScript")
llm.setErrorScript("MyAgent:ErrorFlow")
return llm.sendRequest()
Жизненный цикл и статусы
| Статус | Когда устанавливается | Описание |
|---|---|---|
IDLE |
new LLMClient(...) |
Клиент создан, ничего не сделано. |
PREPARED |
prepareRequest() |
Промпты собраны, запрос готов. |
WAITING |
sendRequest() |
Запрос отправлен, ожидаем ответ. |
SUCCESS |
handleResponse() (200) |
Ответ успешно получен. |
ERROR |
handleResponse() (≠200) |
Ошибка при получении ответа. |
ERROR_HANDLED |
handleResponse() → fallback |
Сработал обработчик ошибки. |
DONE |
вручную | Не используется напрямую. |
Отладка и переменные
| Переменная | Пример значения | Описание |
|---|---|---|
llm_<session>_status |
WAITING |
Текущий статус запроса |
llm_<session>_provider |
OpenAI |
Название LLM-провайдера |
llm_<session>_params |
{ model: "gpt-3.5-turbo", temperature: 0.7 } |
Параметры модели |
llm_<session>_messages |
[{"role": "system", ...}, ...] |
Все промпты запроса |
llm_<session>_history |
[{"role": "user", ...}, ...] |
История переписки |
llm_<session>_callback_script |
MyAgent:NextStep |
Скрипт для ответа |
llm_<session>_error_script |
MyAgent:Fallback |
Скрипт для ошибки |
llm_<session>_raw_response |
Вот ваш ответ... |
Текст ответа до форматирования |
llm_<session>_user_query |
Сколько лет космосу? |
Последний пользовательский запрос |
FAQ
Вопрос: Как добавить свой промпт?
Ответ: Используйте addSystemPrompt, addUserPrompt или addAssistantPrompt. Можно ссылаться на промпты из таблицы через $name или @common_name.
Вопрос: Как обработать ошибку?
Ответ: Назначьте обработчик через setErrorScript(scriptCode) или используйте резервный сценарий через setFallbackConfig(scriptCode, timeout).
Вопрос: Как получить статистику токенов?
Ответ: Вызовите getLastTokenUsage() после получения ответа.
Вопрос: Как интегрировать с другими компонентами?
Ответ: Используйте методы перехода (nextFlow), отправки (sendResponse, sendFormattedResponse) и работы с историей.
Создание ClickHouse - SQL агента
Введение
Обычные LLM модели плохо справляются с числовыми данными - придумывают несуществующие цифры, неточно считают и не могут обрабатывать большие объемы информации. Для решения этой проблемы мы соединим возможности ИИ с профессиональными инструментами работы с данными.
В этом руководстве мы создадим специализированного агента для работы с базой данных ClickHouse, который сможет:
- Точно отвечать на вопросы с числовыми данными
- Выполнять сложные расчеты и сравнения
- Искать минимальные и максимальные значения
- Анализировать тарифы и условия
Пример использования: Банк собрал данные о конкурентах в одну таблицу и хочет, чтобы бот мог отвечать на вопросы типа "У какого банка самая низкая комиссия за перевод 25 000 долларов?"
Этап 1: Подключение к ClickHouse
Настройка подключения к базе данных
Первым шагом необходимо развернуть собственный кластер ClickHouse. После развертывания:
- Переходим в атрибуты бота
- Создаем атрибут
CLICK_HOUSE_CREDENTIALS - Заполняем данные подключения в формате JSON:
{
"host": "http://111.1111.11.101:8000",
"user": "admin",
"password": "12345",
"database": "test"
}
Тестирование соединения
Создайте новый скрипт в боте для проверки подключения:
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// 1. ПРОВЕРКА СОЕДИНЕНИЯ
const ping = ch.ping()
bot.sendMessage('PING → ' + ping.result)
// 2. ПРОСМОТР СУЩЕСТВУЮЩИХ ТАБЛИЦ
const tablesList = ch.select('SHOW TABLES')
bot.sendMessage('TABLES → ' + JSON.stringify(tablesList))
Запустите скрипт и проверьте результат. Если возникают ошибки - проверьте доступы к кластеру и правильность данных подключения.
Этап 2: Проектирование структуры таблицы
Подготовка исходных данных
Для примера используем таблицу сравнения банковских тарифов:
| Банк | Мин. сумма | Сроки | До 20k USD | 20–50k USD | 50–100k USD | Валютный контроль | Мин. руб. | Макс. руб. | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Кофейный | нет | 3–4 дня | 3% | 1,2% | 0,6% | 0,36% | 0,36% | нет | н/д | 0,15% | 750 | нет |
| Жёлтый | нет | 1–3 дня | 3% | 2,5% | 2,5% | 2% | 2,5% | нет | курс ЦБ | 0,16% | 360 | 29000 |
| Салатовый | нет | до 5 дней | 3,5% | 3,5% | 3,5% | 2,8% | 2,5% | нет | курс ЦБ | 0,15% | 2000 | нет |
| Зелёный | нет | 3–5 дней | 3% | 3% | 2,7% | 2,3–2,5% | 2,2% | 130 USD за SWIFT до 50k | банк/ЦБ/Investing | 0,24% | 2000 | — |
| Розовый | нет | 5 дней | 3,5–4,5% | 3,3–3,9% | 3–3,5% | 2,3–2,5% | 2,2% | 70–150 USD за SWIFT до 15k | Investing/ЦБ (макс ставка) | 0,15% | 750 | нет |
| Охра | нет | 3 дня | 55000 руб. | 2,65% | 2,2% | 2,1% | 2,1% | нет | курс ЦБ | 0,1% | 700 | 20000 |
| Малиновый | 20 тыс. | 3 дня | — | 2–3% | 2–3% | 2–3% | 2–3% | нет | ЦБ/Investing | 0,12% | 500 | 60000 |
| Синий | 50 тыс. | 2–4 дня | Китай: 2,5% | Иные: 2–4% | — | — | — | нет | Investing | 0,15% | 1000 | 20000 |
| Бирюзовый | 10 тыс. | 3–4 дня | 2–4% | 2–4% | 2–4% | 2–4% | 2–4% | нет | ЦБ/profinance | 0,12% | — | 60000 |
| Оранжевый | — | 1–6 дней | 4,5% мин. 80k руб. | 4,5% мин. 80k руб. | 2,5–4% | 2,5–4% | 2,5–4% | нет | курс ЦБ | 0,15% | 1000 | 20000 |
| Бурый | 50 тыс. | 3 дня | нет | нет | 2–3,5% | 2–3,5% | 2–3,5% | нет | Investing | 0,15% | 600 | 50000 |
| Среднее | 30 тыс. | 3 дня | 3,7% | 3,1% | 3,1% | 2,7% | 2,4% | нет | нет | 0,14% | 750 | 45000 |
| Красный | — | 3 дня | 3% мин. 500 USD / 1,5–2% мин. 400 USD | то же | то же | 2,5% / 1,5–2% мин. 400 USD | 2% / 1,5–2% мин. 400 USD | нет | банк/ЦБ | 0,22% | 1000 | нет |
Генерация оптимальной структуры с помощью ИИ
Чтобы создать правильную структуру базы данных, воспользуемся специальным промптом:
- Переходим на https://console.anthropic.com
- Используем проверенный промпт:
You are an AI agent (Data Engineer) tasked with building ClickHouse database tables for a bank's calculation purposes. Your goal is to analyze JSON data and create an optimal table structure that allows for easy querying in ClickHouse.
Here are some important guidelines:
- Always split percentages into minimum and maximum values.
- Never store percentages as STRING or in quotes like "0.3-0.5".
- Use appropriate data types: FLOAT for percentages and decimals, INT for whole numbers.
- Design the structure carefully, thinking like a database engineer.
Analyze the following JSON data:
<json_data>
{{JSON_DATA}}
</json_data>
Your task is to:
1. Carefully examine the JSON structure and its contents.
2. Design an appropriate database structure that will allow for efficient querying in ClickHouse. Consider:
- What fields should be created?
- What data types should be used for each field?
- How to handle nested structures or arrays if present?
- How to split percentage ranges into separate minimum and maximum fields?
3. Write a SQL query to create the database table(s) based on your designed structure. Ensure that:
- All field names are clear and descriptive
- Appropriate data types are used (FLOAT for percentages and decimals, INT for whole numbers, etc.)
- The structure allows for easy and efficient querying
Remember: The goal is to create a structure that will enable straightforward and performant queries in ClickHouse. Think carefully about how the data will be used and queried in the future.
Provide your response in the following format:
<database_design>
[Explain your thought process and the rationale behind your database design here]
</database_design>
<sql_query>
[Write the SQL query to create the database table(s) here]
</sql_query>
If you need to make any assumptions or have any questions about the data structure, state them clearly in your explanation.
- В параметр JSON_DATA подставляете несколько строк из вашей таблицы
- Получаете готовый SQL для создания оптимальной структуры
Создание таблицы в ClickHouse
Создайте скрипт с полученным SQL-запросом:
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// 1. ПРОВЕРКА СОЕДИНЕНИЯ
const ping = ch.ping()
bot.sendMessage('PING → ' + ping.result)
// 2. УДАЛЕНИЕ СТАРОЙ ТАБЛИЦЫ (если существует)
const dropResult = ch.query(`DROP TABLE IF EXISTS bank_commissions`)
bot.sendMessage('DROP → DONE')
// 3. СОЗДАНИЕ НОВОЙ ТАБЛИЦЫ (Сюда подставляем SQL из прошлого шага)
const createResult = ch.createTable(`
CREATE TABLE bank_commissions
(
bank_name String,
min_payment Nullable(Int32),
delivery_days_min UInt8,
delivery_days_max UInt8,
commission_under_20k_min Float32,
commission_under_20k_max Float32,
commission_20k_50k_min Float32,
commission_20k_50k_max Float32,
commission_50k_100k_min Float32,
commission_50k_100k_max Float32,
currency_control_min Float32,
currency_control_max Float32,
min_rub Nullable(Int32),
max_rub Nullable(Int32)
)
ENGINE = MergeTree
ORDER BY bank_name`)
bot.sendMessage('CREATE → DONE')
Этап 3: Загрузка данных
Подготовка данных в JSON формате
Преобразуйте табличные данные в структурированный JSON с полями соответствующими полученной таблице:
[{
"bank_name": "Кофейный",
"min_payment": null,
"delivery_days_min": 3,
"delivery_days_max": 4,
"commission_under_20k_min": 3.0,
"commission_under_20k_max": 3.0,
"commission_20k_50k_min": 1.2,
"commission_20k_50k_max": 1.2,
"commission_50k_100k_min": 0.6,
"commission_50k_100k_max": 0.6,
"currency_control_min": 0.15,
"currency_control_max": 0.15,
"min_rub": 750,
"max_rub": null
}, {
"bank_name": "Жёлтый",
"min_payment": null,
"delivery_days_min": 1,
"delivery_days_max": 3,
"commission_under_20k_min": 3.0,
"commission_under_20k_max": 3.0,
"commission_20k_50k_min": 2.5,
"commission_20k_50k_max": 2.5,
"commission_50k_100k_min": 2.5,
"commission_50k_100k_max": 2.5,
"currency_control_min": 0.16,
"currency_control_max": 0.16,
"min_rub": 360,
"max_rub": 29000
}]
Загрузка через Метабот
Создайте скрипт для загрузки данных:
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// 1. ПРОВЕРКА СОЕДИНЕНИЯ
const ping = ch.ping()
bot.sendMessage('PING → ' + ping.result)
// 2. ОЧИСТКА СТАРЫХ ДАННЫХ
const truncateResult = ch.query('TRUNCATE TABLE bank_commissions')
bot.sendMessage('TRUNCATE → DONE')
// 3. ПОДГОТОВКА ДАННЫХ
const banksData = [
// Вставьте здесь ваш JSON массив с данными банков
]
// 4. ЗАГРУЗКА В БАЗУ
const insertResult = ch.insert('bank_commissions', banksData)
bot.sendMessage('INSERT → DONE')
Этап 4: Интеграция SQL-агента в систему
Теперь создадим специализированного агента, который будет генерировать SQL-запросы и возвращать точные ответы на основе данных из ClickHouse.
Шаг 1: Обновление конфигурации
Откройте плагин AgentsParams.MainConfig и дополните конфигурацию:
А) Добавить новый инструмент в маршрутизатор
detectRoute: {
// ... остальные параметры остаются без изменений
routerTools: [{
tools: "RAG_Tools",
route: "RAG:DetectIntent_and_FindChunks"
}, {
tools: "INFO_Tools",
route: "CompanyInfo"
}, {
tools: "TABLE1_Tools", // Новый инструмент для работы с данными
route: "ClickHouse:GenerateSQL"
}]
// ... остальные параметры остаются без изменений
}
Б) Создать конфигурацию для ClickHouse агента
else if (activeAgent === "ClickHouse") { // Агент для работы с SQL таблицами ClickHouse
agentCFG = {
common: {
title: "ClickHouse Query Agent",
agentName: "ClickHouse",
promptTable: "gpt_prompts",
userQueryAttibName: "user_query",
historyMaxLength: 2,
exitScript: "MainFlow:FollowUp"
},
generateSQL: {
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
prompt: "$clickhouse_sql_prompt",
errorScript: "RAG:ErrorFallback",
exitScript: "RAG:UserReply",
useHistory: 1,
addUserQuery: 1,
sendBotAnwser: 1
},
userReply: {
provider: "OpenAI",
model: "gpt-4o",
modelParams: {
"temperature": 1
},
errorScript: "RAG:ErrorFallback",
useHistory: 1,
addUserQuery: 1,
sendBotAnwser: 1,
systemPrompts: {
start: [
["$clickhouse_result_prompt"]
],
final: []
},
}
}
}
Шаг 2: Создание скрипта агента
Создайте новый скрипт с именем ClickHouse:GenerateSQL:
Код создавайте в блоке "Выполнить асинхронный API-запрос"
const LLMClient = require("Common.MetabotAI.LLMClient")
// Установка активного агента ClickHouse
lead.setAttr('activeAgent', 'ClickHouse')
snippet("Business.AgentsParams.MainConfig")
const llm = new LLMClient("UserReply", agentCFG.common.agentName)
// Настройка истории диалога
if (!agentCFG.generateSQL.useHistory) {
llm.disableHistory()
}
if (isFirstImmediateCall) {
// Настройка LLM клиента
llm.setProvider(agentCFG.generateSQL.provider)
llm.setModel(agentCFG.generateSQL.model)
llm.setModelParams(agentCFG.generateSQL.modelParams)
llm.addSystemPrompt(agentCFG.generateSQL.prompt)
llm.addUserQuery(lead.getAttr(agentCFG.common.userQueryAttibName))
llm.prepareRequest()
return llm.sendRequest()
}
// Обработка ответа LLM
llm.handleResponse()
// Извлечение SQL-запроса из ответа
let sqlQuery = extractContentBetweenTags("sql_query")
// Проверка корректности SQL
if (!sqlQuery) {
return llm.nextFlow(agentCFG.generateSQL.errorScript)
}
// Подключение к ClickHouse
const ClickHouse = require('Common.Integrations.ClickHouse')
const CLICK_HOUSE_CREDENTIALS = bot.getJsonAttr("CLICK_HOUSE_CREDENTIALS")
const ch = new ClickHouse(CLICK_HOUSE_CREDENTIALS)
// Выполнение SQL-запроса
const queryResult = ch.query(sqlQuery)
// Добавление результата в историю
llm.addToHistory({
role: "assistant",
content: JSON.stringify(queryResult)
})
// Переход к формированию ответа пользователю
return llm.nextFlow(agentCFG.generateSQL.exitScript)
// Функция извлечения контента между тегами
function extractContentBetweenTags(tagName, text = null) {
text = text || llm.getResponseText()
const openTag = `<${tagName}>`
const closeTag = `</${tagName}>`
const startIndex = text.indexOf(openTag)
if (startIndex === -1) return null
const endIndex = text.indexOf(closeTag, startIndex + openTag.length)
if (endIndex === -1) return null
return text.substring(startIndex + openTag.length, endIndex).trim()
}
Шаг 3: Создание промптов
1. Откройте таблицу gpt_prompts, cоздайте промпт clickhouse_sql_prompt для агента ClickHouse:
You are a Data Engineer who communicates exclusively through SQL queries. Your task is to interpret requests from a senior agent and formulate appropriate SQL queries for a ClickHouse database. Here's how you should proceed:
First, familiarize yourself with the structure of the ClickHouse table:
<table_structure>
{{@click_house_tables}}
</table_structure>
When you receive a query from the senior agent, it will be in simple language. Your job is to interpret this query and create an SQL statement that will retrieve the requested information from the ClickHouse database.
The user's query will be provided in the following format:
<user_query>
{{$user_query}}
</user_query>
Based on this query and your knowledge of the table structure, formulate an SQL query that will retrieve the requested information. Your query should be as detailed as possible, providing comprehensive data for the senior agent to analyze and make decisions.
Remember:
1. You should only output SQL code. Do not provide any explanations, comments, or additional text.
2. Strive to create complex queries when necessary to calculate the required data.
3. Always aim to provide detailed data in your query results.
4. Do not use any functions or features that are not standard SQL or specific to ClickHouse.
Your response should consist solely of the SQL query, enclosed in <sql_query> tags. For example:
<sql_query>
SELECT column1, column2, COUNT(*) as count
FROM table_name
WHERE condition
GROUP BY column1, column2
ORDER BY count DESC
LIMIT 10
</sql_query>
Do not include any text before or after the SQL query. Your entire response should be contained within the <sql_query> tags.
2. Создайте промпт clickhouse_result_prompt для агента ClickHouse:
Вы являетесь Помощником банка. Ваша задача - проанализировать историю диалога, получить из неё запрос пользователя, проанализировать ответ SQL агента и дать понятный ответ, соответствующий запросу пользователя. Отвечайте четко и по существу, представляя числовые данные в удобном для восприятия формате.
3. Создайте атрибут бота click_house_tables с описанием структуры таблицы:
TABLE: bank_commissions
COLUMNS:
- bank_name (String): Название банка
- min_payment (Nullable Int32): Минимальная сумма платежа в рублях
- delivery_days_min (UInt8): Минимальное время доставки в днях
- delivery_days_max (UInt8): Максимальное время доставки в днях
- commission_under_20k_min (Float32): Минимальная комиссия до 20k USD в процентах
- commission_under_20k_max (Float32): Максимальная комиссия до 20k USD в процентах
- commission_20k_50k_min (Float32): Минимальная комиссия 20-50k USD в процентах
- commission_20k_50k_max (Float32): Максимальная комиссия 20-50k USD в процентах
- commission_50k_100k_min (Float32): Минимальная комиссия 50-100k USD в процентах
- commission_50k_100k_max (Float32): Максимальная комиссия 50-100k USD в процентах
- currency_control_min (Float32): Минимальная комиссия валютного контроля в процентах
- currency_control_max (Float32): Максимальная комиссия валютного контроля в процентах
- min_rub (Nullable Int32): Минимальная сумма в рублях
- max_rub (Nullable Int32): Максимальная сумма в рублях
Шаг 4: Обновление маршрутизации
Откройте таблицу gpt_prompts, найдите промпт route_prompt для агента MainFlow и обновите секцию с инструментами:
<tools>
**RAG_Tools** - Используется, когда нужно ответить на вопросы об услугах
и продукции компании, об условиях эксплуатации продукции, об используемых
инструментах для монтажа продукции и т.д.
**INFO_Tools** - Используется когда пользователь хочет узнать о филиалах
компании, контактных данных или времени их работы
**TABLE1_Tools** используется для поиска информации и ответов на вопросы о:
- Ценах и стоимости переводов
- Комиссиях за переводы и платежи
- Точных цифрах и числовых данных, хранящихся в локальной базе данных
- Сравнении различных параметров (цены, комиссии, характеристики)
- Поиске минимальных/максимальных значений (самая низкая комиссия, самая высокая цена и т.д.)
- Условиях и тарифах банков-партнеров
- Расчетах и вычислениях на основе имеющихся данных
</tools>
Этап 5: Тестирование и результат
Примеры работы системы
После настройки система сможет отвечать на сложные вопросы с числовыми данными:
Простые запросы:
- "Какая комиссия у банка Кофейный?"
- "Сколько дней занимает перевод в Желтом банке?"
Сложные аналитические запросы:
- "В каком банке дешевле всего обменять 10 000 долларов?"
- "Покажи банки с минимальной комиссией валютного контроля"
- "Какой банк предлагает самые быстрые переводы?"
Принцип работы
- Пользователь задает вопрос о числовых данных
- Главный агент определяет - нужен TABLE1_Tools
- SQL-агент генерирует соответствующий запрос к ClickHouse
- База данных возвращает точные результаты
- Система формирует понятный ответ для пользователя
Преимущества решения
- Точность данных - никаких выдуманных цифр
- Сложные вычисления - система может выполнять расчеты любой сложности
- Масштабируемость - легко добавлять новые таблицы и данные
- Актуальность - данные всегда свежие из базы
- Производительность - ClickHouse обеспечивает быстрые запросы
Ваша мультиагентная система теперь может работать не только с текстовой информацией, но и предоставлять точные числовые данные и выполнять сложные аналитические запросы.
Руководство по работе с базой знаний (RAG)
Структура таблицы базы знаний
Представьте базу знаний как умный склад информации. Когда нужно полностью "перезагрузить" этот склад, мы поступаем просто:
-
Полная очистка базы знаний: удаляем старую таблицу и создаём точно такую же заново
- Это как снести старый склад и построить новый по тому же чертежу
- Гарантирует, что не останется "мусора" от предыдущих данных
-
Размер вектора (embedding): может изменяться в зависимости от выбранного алгоритма векторизации
- Вектор — это числовое представление смысла текста
- Разные алгоритмы создают векторы разной длины (как разные форматы фотографий)
Создание компонента базы знаний
Важно: всегда создавайте компонент для базы знаний, на который будут ссылаться агенты.
Думайте о компоненте как о "визитной карточке" вашей базы знаний:
После создания в атрибутах появится компонент с описанием базы знаний:

Подготовка текстового файла
Перед загрузкой файл нужно правильно "подписать" — добавить служебную информацию в начало:
Обязательная служебная строка в начале файла:
{{Domain: METABOT33}}{{Table: gpt_knowledge_base}}{{chunk_size: 250}}{{chunk_overlap: 160}}
Эта строка работает как "инструкция по применению":
Domain— область применения (как адрес склада)Table— название таблицы (как название полки на складе)chunk_size— размер кусочка текста для обработки (250 символов)chunk_overlap— перекрытие между кусочками (160 символов для связности)

Загрузка и векторизация
Процесс состоит из двух этапов:
Этап 1: Загрузка файла
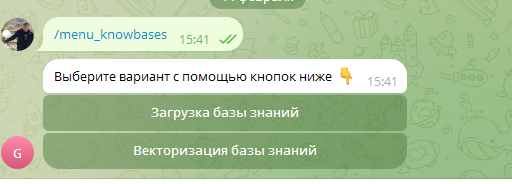
Система принимает подготовленный файл и сохраняет его содержимое.
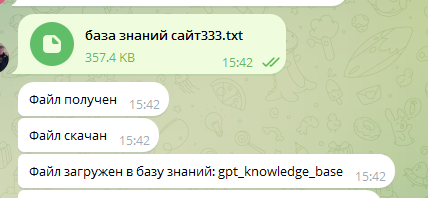
Этап 2: Векторизация
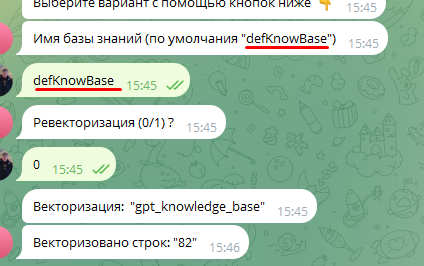
Система превращает текст в числовые векторы для быстрого поиска по смыслу.
Важно: сохраните имя defKnowBase — оно понадобится в конфигурации в параметре kbName.
Совет: процесс загрузки и векторизации похож на работу переводчика — сначала он читает текст (загрузка), потом переводит его на "язык чисел" (векторизация), чтобы компьютер мог быстро найти нужную информацию по смыслу, а не только по точным словам.
Документация по LLMTracer
Модуль LLMTracer предназначен для трассировки запросов к LLM, а также для сбора статистики по токенам, времени выполнения и ошибкам. Все данные записываются в таблицу llm_tracer.
Класс: Session
Подключается через
let LLMTracer = require("Common.AIHelpers.LLMTracer")createSession(options)
Создаёт новую сессию трассировки.
Пример:
let session = LLMTracer.createSession({
business_id: "123",
bot_id: "456",
lead_id: "789",
script_id: "script_1",
command_id: "cmd_1",
agent_name: "MyAgent",
provider: "OpenAI",
model: "gpt-4"
})Параметры:
| Имя | Тип | Описание |
|---|---|---|
| business_id | String | Идентификатор бизнеса |
| bot_id | String | Идентификатор бота |
| lead_id | String | Идентификатор лида |
| script_id | String | Идентификатор скрипта |
| command_id | String | Идентификатор команды |
| agent_name | String | Имя агента |
| provider | String | Название провайдера LLM |
| model | String | Название модели LLM |
Return
Session — Экземпляр сессии трассировки.
getCurrentSession()
Получает текущую сессию из атрибута лида.
Пример:
let session = LLMTracer.getCurrentSession()Параметры:
Нет
Return
Session | null — Текущий объект сессии или null, если не найден.
prepareRecordData(data)
Преобразует данные в безопасный формат для записи в таблицу.
Пример:
let safeData = LLMTracer.prepareRecordData({ message: "Тест", status: "ok" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| data | Object | Объект с исходными данными |
Return
Object — Объект с преобразованными значениями.
recordTrace(traceData)
Записывает трассировку в таблицу llm_tracer.
Пример:
LLMTracer.recordTrace({
agent_name: "MyAgent",
outclient_name: "ClientA",
step: "step1",
outclient_time: 120,
provider: "OpenAI",
model: "gpt-4",
type: "info",
message: "Запрос выполнен",
record: {},
params: {},
status: "ok",
input_tokens: 100,
output_tokens: 50
})Параметры:
| Имя | Тип | Описание |
|---|---|---|
| agent_name | String | Имя агента |
| outclient_name | String | Имя внешнего клиента |
| step | String | Название шага |
| outclient_time | Number | Время выполнения шага (мс) |
| provider | String | Название провайдера LLM |
| model | String | Название модели LLM |
| type | String | Тип трассировки (info, error и др.) |
| message | String | Сообщение |
| record | Object | Дополнительные данные |
| params | Object | Параметры запроса |
| status | String | Статус выполнения |
| input_tokens | Number | Количество входных токенов |
| output_tokens | Number | Количество выходных токенов |
Return
Boolean — true при успехе, false при ошибке.
recordTraceLLM(llm, timerCtrl, traceData)
Записывает трассировку по активному LLMClient.
Пример:
LLMTracer.recordTraceLLM(llmClient, "START_TIME", { message: "Старт" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| llm | Object | Экземпляр LLMClient |
| timerCtrl | String | Контроллер времени ("", "START_TIME", "END_TIME") |
| traceData | Object | Дополнительные параметры трассировки |
Return
Boolean — true при успехе, false при ошибке.
recordTraceQuery(llm, timerCtrl, traceData)
Записывает трассировку для запросов к внешним сервисам.
Пример:
LLMTracer.recordTraceQuery(llmClient, "END_TIME", { message: "Финиш" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| llm | Object | Экземпляр LLMClient |
| timerCtrl | String | Контроллер времени ("", "START_TIME", "END_TIME") |
| traceData | Object | Дополнительные параметры трассировки |
Return
Boolean — true при успехе, false при ошибке.
info(message, data)
Записывает информационную трассировку.
Пример:
LLMTracer.info("Запрос выполнен", { step: "step1" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| message | String | Текст сообщения |
| data | Object | Дополнительные данные |
Return
Boolean — true при успехе, false при ошибке.
error(message, data)
Записывает ошибку в трассировку и отправляет сообщение админу.
Пример:
LLMTracer.error("Ошибка запроса", { code: 500 })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| message | String | Текст ошибки |
| data | Object | Дополнительные данные |
Return
Boolean — true при успехе, false при ошибке.
countTokens(dateRange)
Подсчитывает количество токенов за указанный период.
Пример:
LLMTracer.countTokens({ from: "2024-06-01 00:00:00", to: "2024-06-30 23:59:59" })Параметры:
| Имя | Тип | Описание |
|---|---|---|
| from | String | Начальная дата ("YYYY-MM-DD HH:MM:SS") |
| to | String | Конечная дата |
Return
Object — { input_tokens, output_tokens, total_tokens }
getActiveSessionsCount(minutes)
Подсчитывает количество активных сессий за последние N минут.
Пример:
LLMTracer.getActiveSessionsCount(10)Параметры:
| Имя | Тип | Описание |
|---|---|---|
| minutes | Number | Глубина окна в минутах (по умолчанию 5) |
Return
Number — Количество активных сессий.
Быстрый старт
- Создайте сессию:
LLMTracer.createSession({ ... }) - Запишите шаг:
LLMTracer.recordTrace({ ... }) - Для LLM: используйте
recordTraceLLM() - Для ошибок: используйте
error() - Для статистики: используйте
countTokens()
Аналитика и нагрузки
В стандартный шаблон MA_Router входит модуль, который отвечает за контроль нагрузки, лимитов и доступности моделей LLM.
Основные проверки
- Суточный лимит диалогов:
LLMDialogCounter.canStartNewDialog(limit=25)— ограничивает количество диалогов на пользователя. - Текущая нагрузка:
LLMTracer.getActiveSessionsCount(5)— если слишком много активных сессий, диалог откладывается. - Активность ИИ:
bot.getBoolAttr("ai_is_active")— если ИИ выключен, переводит на резервный сценарий.
Логика работы
- Перед стартом диалога — проверяются лимиты и нагрузка.
- Если лимит превышен — пользователю отправляется уведомление, диалог переносится.
- Если нагрузка высокая — диалог откладывается на несколько секунд.
- При старте диалога — увеличивается счётчик, открывается сессия в LLMTracer.
- При завершении — сессия закрывается.
Метрики и отчёты
/aistatsдля получения аналитики по текущему состоянию системы- Пример отчёта:
📊 Статистика LLM Tracer
🕒 За последние 7 дней:
• Токены входящие: 2 533 129
• Токены исходящие: 313 036
• Всего токенов: 2 846 165
• Уникальных лидов: 3
• Уникальных сессий: 29
• Среднее вопросов на пользователя: 9.7
• Превышений 20 запросов в сутки: 1
📈 За всё время:
• Токены входящие: 3 861 082
• Токены исходящие: 351 484
• Всего токенов: 4 212 566
• Уникальных лидов: 3
• Уникальных сессий: 38
• Среднее вопросов на пользователя: 12.7
• Превышений 20 запросов в сутки: 1
Обновлено: 2025-10-06 18:53:52
Таймауты
Для каждого запроса к LLM настраиваются таймауты в конфигурации. При превышении времени ожидания:
- Фиксация проблемы — информация об ошибке отправляется через Notifier
- Fallback — сценарий не блокируется, автоматически запускается Fallback-скрипт
- Продолжение работы — пользователь получает альтернативный ответ без прерывания диалога
Таймауты защищают систему от зависаний при проблемах на стороне LLM-провайдера.
Быстрые ответы на вопросы
- Как узнать текущую нагрузку? — Вызвать
LLMTracer.getActiveSessionsCount(5). - Как фиксируются ошибки? — Через Notifier и запись в LLMTracer.
LLMTracer - Плагин для трассировки запросов к LLM
Описание
LLMTracer - это модуль для трассировки запросов к языковым моделям (LLM) и внешним сервисам. Он позволяет записывать данные о запросах, ответах, ошибках и использовании токенов в таблицу llm_tracer.
Установка
Импортируйте модуль в ваш код:
const LLMTracer = require('Common.Platform.LLMTracer');
Основные возможности
- Создание сессий трассировки
- Запись информационных сообщений
- Запись ошибок
- Подсчет использованных токенов за указанный период
Быстрый старт
1. Создание сессии трассировки
// Создание сессии с параметрами по умолчанию
const session = LLMTracer.createSession();
// Создание сессии с указанием параметров
const session = LLMTracer.createSession({
agent_name: "ChatGPT Assistant",
provider: "OpenAI",
model: "gpt-4"
});
Параметры:
options(Object) - Параметры сессииbusiness_id(string|number) - ID бизнесаbot_id(string|number) - ID ботаlead_id(string|number) - ID лидаscript_id(string|number) - ID скриптаcommand_id(string|number) - ID командыagent_name(string) - Имя агентаprovider(string) - Провайдер LLMmodel(string) - Модель LLM
2. Прямая запись трассировки
// Прямая запись трассировки с указанием всех параметров
LLMTracer.recordTrace({
outclient_name: "OpenAI API",
step: 1,
outclient_time_sec: 2.5,
provider: "OpenAI",
model: "gpt-4",
type: "info",
message: "Запрос выполнен",
status: "success",
input_tokens: 150,
output_tokens: 50
});
Параметры:
traceData(Object) - Данные для записи в таблицуoutclient_name(string) - Имя внешнего клиентаstep(number|string) - Шаг выполненияoutclient_time_sec(number) - Время выполнения запроса в секундахprovider(string) - Провайдер LLMmodel(string) - Модель LLMtype(string) - Тип записи (info, error)message(string) - Сообщениеrecord(string) - Дополнительные данные в формате JSONstatus(string|number) - Статус выполненияinput_tokens(number) - Количество входных токеновoutput_tokens(number) - Количество выходных токенов
3. Запись информационных сообщений
// Запись простого сообщения
LLMTracer.info("Запрос к LLM выполнен успешно");
// Запись сообщения с дополнительными данными
LLMTracer.info("Запрос к LLM выполнен успешно", {
outclient_name: "OpenAI API",
input_tokens: 150,
output_tokens: 50,
outclient_time_sec: 2.5
});
Параметры:
message(string) - Информационное сообщениеdata(Object) - Дополнительные данные для записиoutclient_name(string) - Имя внешнего клиентаstep(number|string) - Шаг выполненияoutclient_time_sec(number) - Время выполнения запроса в секундахprovider(string) - Провайдер LLMmodel(string) - Модель LLMstatus(string|number) - Статус выполненияinput_tokens(number) - Количество входных токеновoutput_tokens(number) - Количество выходных токенов
3. Запись ошибок
try {
// Ваш код...
} catch (error) {
LLMTracer.error("Ошибка при запросе к LLM", {
error_message: error.message,
outclient_name: "OpenAI API"
});
}
4. Подсчет токенов
// Подсчет токенов за все время
const allTokens = LLMTracer.countTokens();
debug(`Всего использовано токенов: ${allTokens.total_tokens}`);
// Подсчет токенов за определенный период
const tokensForPeriod = LLMTracer.countTokens({
from: "2023-01-01 00:00:00",
to: "2023-01-31 23:59:59"
});
debug(`Входящие токены: ${tokensForPeriod.input_tokens}`);
debug(`Исходящие токены: ${tokensForPeriod.output_tokens}`);
debug(`Всего токенов: ${tokensForPeriod.total_tokens}`);
Параметры:
dateRange(Object) - Объект с параметрами временного диапазонаfrom(string) - Начальная дата в формате "YYYY-MM-DD HH:MM:SS"to(string) - Конечная дата в формате "YYYY-MM-DD HH:MM:SS"
Возвращает: Объект с количеством токенов
input_tokens(number) - Количество входных токеновoutput_tokens(number) - Количество выходных токеновtotal_tokens(number) - Общее количество токенов
Структура таблицы llm_tracer
Модуль записывает данные в таблицу llm_tracer со следующими полями:
business_id- ID бизнесаlead_id- ID лидаscript_id- ID скриптаsession_id- ID сессииagent_name- Имя агентаoutclient_name- Имя внешнего клиентаstep- Шаг выполненияoutclient_time- Время выполнения запроса в секундахprovider- Провайдер LLMmodel- Модель LLMtype- Тип записи (info, error)message- Сообщениеrecord- Дополнительные данные в формате JSONstatus- Статус выполненияinput_tokens- Количество входных токеновoutput_tokens- Количество выходных токеновcreated_at- Дата и время создания записи (автоматически)
Импортировать таблицу можно по ссылке: https://stage.metabot.dev/business/export/1216/show?bots=&b_c=0&b_o=0&b_i=0&b_ls=0&b_r=0&b_s=0&b_li=0&b_t=0&b_br=0&b_aie=0&b_aee=0&b_sa=0&cts_llm_tracer=1&b_llm_tracer=1
Конфигурация
Конфигурационный плагин бизнеса (snippet Business.AgentsParams.BSPbConfig) используется для централизованного управления параметрами агентов в системе MAS. Он определяет настройки для различных сценариев работы агентов, включая маршрутизацию, выбор моделей, параметры генерации, обработку ошибок и интеграцию с внешними инструментами.
Структура файла
Файл представляет собой JavaScript-объект, где каждая ветка соответствует определённому агенту или сценарию. Основные разделы:
- common — общие параметры агента (имя, таблица промптов, максимальная длина истории, сценарий выхода и др.)
- detectRoute — параметры для маршрутизации запросов (провайдер, модель, промпт, инструменты маршрутизации, обработчик ошибок)
- detectIntent — параметры для определения намерения пользователя (провайдер, модель, промпт, обработчик ошибок, база знаний)
- userReply — параметры для формирования ответа пользователю (провайдер, модель, история, промпты, обработчик ошибок)
- execSQL — параметры для SQL-агентов (провайдер, модель, промпт, обработчик ошибок)
Пример структуры
{
common: {
title: "Основной Flow c маршрутизатором",
agentName: "bsp",
promptTable: "gpt_prompts",
userQueryAttibName: "user_query",
historyMaxLength: 4,
useRoute: 0,
exitScript: "MainFlow_FollowUp",
MBQuery_fallback: {
script_code: "MBQuery_TimeOut",
timeout: 180
}
},
detectRoute: {
provider: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
prompt: "$route_prompt",
routerTools: [ ... ],
errorScript: "RAG_ErrorFallback"
},
detectIntent: {
provider: "OpenAI",
apiFormat: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
prompt: "$rag_intent_prompt",
errorScript: "RAG_ErrorFallback",
kbName: "defKnowBase",
kbDomain: "tech_domain"
},
userReply: {
provider: "OpenAI",
apiFormat: "OpenAI",
model: "gpt-5-mini",
modelParams: { temperature: 1 },
errorScript: "RAG_ErrorFallback",
useHistory: 1,
addUserQuery: 1,
sendBotAnwser: 1,
systemPrompts: {
start: [["$start_prompt", "$rag_prompt"]],
final: ["$final_prompt"]
}
}
}Как работает подстановка
- Загрузка snippet: Конфигурация подгружается через snippet с именем
Business.AgentsParams.BSPbConfig. - Выбор активного агента: В коде определяется активный агент через переменную
activeAgent(например,bsp,CompanyInfo,Table1). - Инициализация agentCFG: В зависимости от значения
activeAgentвыбирается соответствующая ветка конфигурации и присваивается переменнойagentCFG. - Передача параметров: agentCFG используется для инициализации LLMClient, настройки промптов, истории, провайдера, модели и других параметров.
- Маршрутизация и обработка: Ветка
detectRouteопределяет инструменты маршрутизации, которые используются для выбора сценария обработки запроса пользователя. - Обработка ошибок: Для каждого сценария можно задать обработчик ошибок (
errorScript) и fallback-скрипты. - Интеграция с базой знаний: Ветка
detectIntentможет содержать параметры для подключения к базе знаний (kbName,kbDomain).
Структура кода
let aAgent = lead.getAttr("activeAgent")
let agentCFG
if (aAgent === "bsp") {
agentCFG = { ... } // параметры для bsp
} else if (aAgent === "CompanyInfo") {
agentCFG = { ... } // параметры для CompanyInfo
} else if (aAgent === "Table1") {
agentCFG = { ... } // параметры для Table1
} else {
bot.sendMessage(`BSPbConfig:snippet - неизвестный activeAgent: ${aAgent}`)
bot.stop()
}
Куда подставляются параметры
- LLMClient: параметры модели, провайдера, истории, промптов и сценариев подставляются при создании и настройке клиента.
- Маршрутизатор: инструменты из
routerToolsиспользуются для выбора сценария обработки. - Обработка ошибок: скрипты из
errorScriptиMBQuery_fallbackиспользуются для fallback-логики. - Промпты: значения из
systemPromptsподставляются в соответствующие методы LLMClient для формирования запроса. - База знаний: параметры
kbNameиkbDomainиспользуются для интеграции с внешними источниками знаний.
Рекомендации
- Все параметры должны быть явно определены для каждого сценария, чтобы избежать ошибок при маршрутизации и генерации ответа.
- Для расширения функционала добавляйте новые ветки конфигурации с нужными параметрами.
FAQ
Вопрос: Как добавить нового агента?
Ответ: Добавьте новую ветку в объект конфигурации с нужными параметрами и обработчиками.
Вопрос: Как изменить модель или провайдера?
Ответ: Измените значения model и provider в нужной ветке конфигурации.
Вопрос: Как задать fallback-скрипт?
Ответ: Укажите параметры в MBQuery_fallback или errorScript для нужного сценария.
Вопрос: Как интегрировать базу знаний?
Ответ: Добавьте параметры kbName и kbDomain в ветку сценария, где требуется интеграция.
Ошибки и отладка
В этом документе описаны все основные механизмы обработки ошибок, настройки таймаутов, использование нотификатора, трассировки и отладки.
1. Таймауты: где и как настраиваются
Таймауты — это максимальное время ожидания ответа от LLM или внешнего сервиса. Если таймаут превышен, происходит ошибка и запускается обработка сбоя.
Где настраиваются:
- В конфиге агента (
agentCFG): timeout: время ожидания в секундах.- Пример:
MBQuery_fallback: { script_code: "MBQuery_TimeOut", timeout: 180 } - В клиенте LLM (
LLMClient):- Таймаут может задаваться при инициализации клиента или в параметрах запроса.
- Если таймаут не указан — используется значение по умолчанию (обычно 30-60 секунд).
Как работает:
- Если таймаут превышен:
- Сценарий не блокируется — пользователь отправляется в выбранный скрипт в котором описана другая логика обработки его запроса
2. Нотификатор: что это и как работает
Notifier — это модуль для отправки уведомлений о сбоях и важных событиях админам.
- Подробная инструкция: см. Документация по Notifier
- Вызов:
Notifier.send({ message, severity, ... }) - Используется для ошибок, таймаутов, превышения лимитов.
3. LLMTracer: трассировка ошибок
LLMTracer — модуль для логирования всех событий, включая ошибки.
- Подробная инструкция: см. Документация по LLMTracer
- При ошибке записывается строка с
type=err,status=error, описанием и параметрами запроса. - Позволяет анализировать причины сбоев, видеть историю запросов и ответов.
- Для отладки используйте подробные сообщения и сохраняйте контекст.
4. Режим debug и самостоятельная отладка
Если не удаётся найти причину ошибки:
- Включите режим debug:
- Перейдите в настройки бота и включите режим отладки.
- Перейдите в настройки лида и включите нужный режим отладки.
- В точках падения используйте команды логирования:
bot.debug('Debug:' + JSON.stringify(data))
- Пройдите путь пользователя вручную:
- Повторите шаги, которые приводят к ошибке.
- Проверьте параметры запроса, ответы модели, логи LLMTracer.
- Используйте тестовые данные и сценарии.
Eval - Тестирование
Схема работы системы Eval
Полная схема флоу с блокировками и таблицами
graph TB
Start([Пользователь запускает тест]) --> StartRun[Eval_StartRun]
StartRun --> CheckRun{Проверка run_status}
CheckRun -->|pending| CreateReport[Создать report в eval_reports]
CheckRun -->|!pending| Error1[Ошибка: run уже запущен]
CreateReport --> UpdateRun[Обновить eval_runs:<br/>status=running, started_at]
UpdateRun --> InitLeads[Запустить Eval_InitLead<br/>для каждого run_lead_id]
InitLeads --> SetBatchTest[Установить batchTest=1]
SetBatchTest --> SaveContext[Сохранить eval_context:<br/>run_id, suite_id, report_id]
SaveContext --> ProcessQuestion[Eval_ProcessQuestion]
ProcessQuestion --> CheckContext{Есть текущая серия<br/>в контексте?}
CheckContext -->|Да| GetNextQuestion[Взять следующий вопрос<br/>из серии]
CheckContext -->|Нет| GetUnclaimed[getUnclaimedSeries<br/>report_id, suite_id]
GetUnclaimed --> CheckTable1[Проверить eval_answers:<br/>найти свободные серии/вопросы]
CheckTable1 --> AvailableList{Есть доступные<br/>элементы?}
AvailableList -->|Нет| AggregateReport[Eval_AggregateReport]
AvailableList -->|Да| TryLock[Попытка захвата блокировки]
TryLock --> LockType{Тип элемента?}
LockType -->|Серия| LockSeries["eval_series_runId_seriesIndex<br/>TTL=60s"]
LockType -->|Standalone| LockQuestion["eval_q_runId_questionId<br/>TTL=5s"]
LockSeries --> CheckLock{Блокировка<br/>получена?}
LockQuestion --> CheckLock
CheckLock -->|Нет| ReleaseNotNeeded[continue<br/>блокировка не была получена]
CheckLock -->|Да| DoubleCheck[Двойная проверка:<br/>проверить eval_answers]
ReleaseNotNeeded --> TryLock
DoubleCheck --> AlreadyClaimed{Элемент уже<br/>занят?}
AlreadyClaimed -->|Да| ReleaseLock[bot.releaseLockForBot<br/>освободить блокировку]
AlreadyClaimed -->|Нет| CreateAnswers[Создать записи в eval_answers<br/>status=PROCESSING<br/>для всех вопросов серии]
ReleaseLock --> TryLock
CreateAnswers --> SaveSeriesContext[Сохранить серию в контекст:<br/>current_series, answerIds]
GetNextQuestion --> CheckFirst{Первый вопрос<br/>серии?}
SaveSeriesContext --> CheckFirst
CheckFirst -->|Да| ClearHistory[Очистить историю mainAgent]
CheckFirst -->|Нет| SetQuery[Установить user_query]
ClearHistory --> SetQuery
SetQuery --> MARouter[MA_Router<br/>обработка вопроса ботом]
MARouter --> CheckBatchTest{batchTest==1?}
CheckBatchTest -->|Нет| NormalFlow[Обычный flow]
CheckBatchTest -->|Да| SaveAnswer[Eval_SaveAnswer]
SaveAnswer --> GetSession[Получить session_id<br/>из LLMTracer]
GetSession --> SaveActual[Сохранить actual_answer<br/>в eval_answers]
SaveActual --> GetMetrics[getTraceMetrics<br/>из llm_tracer]
GetMetrics --> SaveMetrics[Сохранить метрики:<br/>latency_ms, tokens, etc.]
SaveMetrics --> LockCounter["eval_run_runId_counter<br/>TTL=10s, wait=30s"]
LockCounter --> IncrementCounter[incrementProcessedQuestions<br/>в eval_reports]
IncrementCounter --> JudgeAnswer[Eval_JudgeAnswer]
JudgeAnswer --> CallJudge[Вызов LLM-ассессора]
CallJudge --> ParseJSON{Успешно<br/>распарсить JSON?}
ParseJSON -->|Да| SaveRatings[Сохранить ratings:<br/>overall, accuracy, etc.<br/>status=COMPLETED]
ParseJSON -->|Нет| SaveDefault[Сохранить дефолтные<br/>ratings=50<br/>status=COMPLETED]
SaveRatings --> UpdateSeriesIdx[Увеличить current_series_question_idx]
SaveDefault --> UpdateSeriesIdx
UpdateSeriesIdx --> ProcessQuestion
MARouter -->|Ошибка| ErrorFallback[RAG_ErrorFallback]
ErrorFallback --> CheckBatchTest2{batchTest==1?}
CheckBatchTest2 -->|Да| HandleError[Eval_HandleError]
CheckBatchTest2 -->|Нет| NormalError[Обычная обработка ошибки]
HandleError --> MarkFailed[markAnswerFailed<br/>status=FAILED<br/>в eval_answers]
MarkFailed --> IncrementFailed[incrementFailedQuestions<br/>в eval_reports]
IncrementFailed --> ProcessQuestion
AggregateReport --> CheckAllProcessed[areAllQuestionsProcessed<br/>report_id, suite_id]
CheckAllProcessed --> CheckStatuses[Проверить статусы через table.find:<br/>PENDING, PROCESSING<br/>используя IN условие]
CheckStatuses --> CheckSeries[Проверить целостность серий:<br/>все вопросы в финальных статусах<br/>COMPLETED или FAILED]
CheckSeries --> AllDone{Все обработано?}
AllDone -->|Нет| SendStatusMsg[Отправить статус главному лиду:<br/>обработка продолжается]
AllDone -->|Да| FinalizeLock["eval_run_runId_finalize<br/>TTL=60s"]
SendStatusMsg --> ExitFlow
FinalizeLock --> LockAcquired{Блокировка<br/>получена?}
LockAcquired -->|Нет| OtherLeadFinalizes[Другой лид финализирует<br/>и отправит уведомление]
LockAcquired -->|Да| FinalizeReport[finalizeReport:<br/>calculateReportStats<br/>status=COMPLETED]
OtherLeadFinalizes --> ExitFlow
FinalizeReport --> FinalizeRun[finalizeRun:<br/>status=COMPLETED<br/>finished_at]
FinalizeRun --> SendNotify[Eval_Notify<br/>отправить уведомление]
SendNotify --> UpdateNotify[Обновить notification_sent=1]
UpdateNotify --> ExitFlow
Note1[Блокировка финализации гарантирует<br/>единственность отправки уведомления]
ExitFlow --> End([Завершение])
style Start fill:#e1f5ff
style End fill:#e1f5ff
style Error1 fill:#ffcccc
style HandleError fill:#ffcccc
style MarkFailed fill:#ffcccc
style LockSeries fill:#fff4cc
style LockQuestion fill:#fff4cc
style LockCounter fill:#fff4cc
style FinalizeLock fill:#fff4cc
style NotifyLock fill:#fff4cc
style CreateReport fill:#ccffcc
style CreateAnswers fill:#ccffcc
style SaveRatings fill:#ccffcc
style FinalizeReport fill:#ccffcc
Схема таблиц и их связи
erDiagram
eval_runs ||--o{ eval_reports : "has"
eval_suites ||--o{ eval_questions : "contains"
eval_suites ||--o{ eval_runs : "used_in"
eval_reports ||--o{ eval_answers : "contains"
eval_questions ||--o{ eval_answers : "answered_by"
eval_runs {
int id PK
int suite_id FK
text run_lead_ids "lead1,lead2,lead3"
text run_status "pending|running|completed|failed"
datetime started_at
datetime finished_at
}
eval_suites {
int id PK
text name
int bot_id
}
eval_questions {
int id PK
int suite_id FK
text question_text
text optimal_answer
int series_index "null для standalone"
int order_in_series "1,2,3..."
}
eval_reports {
int id PK
int run_id FK
datetime started_at
datetime finished_at
int total_questions
int processed_questions
int failed_questions
decimal average_rating
text report_status "running|completed|failed"
int notification_sent
}
eval_answers {
int id PK
int report_id FK
int question_id FK
text lead_id
text session_id
text question_text
text optimal_answer
text actual_answer
text answer_status "pending|processing|completed|failed"
decimal rating_overall
decimal rating_accuracy
int latency_ms
int input_tokens
int output_tokens
text error_message
}
llm_tracer {
text session_id PK
decimal outclient_time
int input_tokens
int output_tokens
}
Схема блокировок и их жизненный цикл
sequenceDiagram
participant L1 as Lead 1
participant L2 as Lead 2
participant DB as eval_answers
participant Lock as Lock System
Note over L1,L2: Параллельная обработка вопросов
L1->>DB: getUnclaimedSeries(report_id, suite_id)
DB-->>L1: [Серия 1, Серия 2, Вопрос 3]
L2->>DB: getUnclaimedSeries(report_id, suite_id)
DB-->>L2: [Серия 1, Серия 2, Вопрос 3]
L1->>Lock: waitForBotLock("eval_series_{runId}_1")
Lock-->>L1: true (получена)
L2->>Lock: waitForBotLock("eval_series_{runId}_1")
Lock-->>L2: false (занята L1)
L1->>DB: Двойная проверка: серия свободна?
DB-->>L1: Да, свободна
L1->>DB: Создать записи status=PROCESSING
DB-->>L1: answerIds: [101, 102, 103]
L2->>Lock: waitForBotLock("eval_series_{runId}_2")
Lock-->>L2: true (получена)
L2->>DB: Двойная проверка: серия свободна?
DB-->>L2: Да, свободна
L2->>DB: Создать записи status=PROCESSING
DB-->>L2: answerIds: [104, 105]
Note over L1: Обработка вопросов серии 1
L1->>DB: Обновить answer_id=101: actual_answer, status=COMPLETED
Note over L2: Обработка вопросов серии 2
L2->>DB: Обновить answer_id=104: actual_answer, status=COMPLETED
Note over L1,L2: Блокировки автоматически освобождаются по TTL
Note over L1,L2: или при ошибке через releaseLockForBot()
Схема обработки ошибок
flowchart TD
Start[Обработка вопроса] --> Process[MA_Router обрабатывает]
Process --> Success{Успешно?}
Process --> Timeout{Таймаут?}
Process --> Error{Ошибка API?}
Success -->|Да| SaveAnswer[Eval_SaveAnswer]
SaveAnswer --> Judge[Eval_JudgeAnswer]
Judge --> JudgeSuccess{Ассессор<br/>ответил?}
JudgeSuccess -->|Да| SaveRatings[Сохранить ratings<br/>status=COMPLETED]
JudgeSuccess -->|Нет| SaveDefault[Сохранить дефолт<br/>status=COMPLETED]
SaveRatings --> NextQuestion[Следующий вопрос]
SaveDefault --> NextQuestion
Timeout -->|Да| ErrorFallback[RAG_ErrorFallback]
Error -->|Да| ErrorFallback
ErrorFallback --> CheckBatch{batchTest==1?}
CheckBatch -->|Нет| UserError[Показать ошибку<br/>пользователю]
CheckBatch -->|Да| HandleError[Eval_HandleError]
HandleError --> MarkFailed[markAnswerFailed<br/>status=FAILED<br/>error_message]
MarkFailed --> IncrementFailed[incrementFailedQuestions]
IncrementFailed --> NextQuestion
NextQuestion --> CheckMore{Есть ещё<br/>вопросы?}
CheckMore -->|Да| Process
CheckMore -->|Нет| Aggregate[Eval_AggregateReport]
Aggregate --> CheckAll{Все вопросы<br/>обработаны?}
CheckAll -->|Нет| Wait[Ждать завершения<br/>других лидов]
CheckAll -->|Да| Finalize[Финализация report]
style Error fill:#ffcccc
style Timeout fill:#ffcccc
style HandleError fill:#ffcccc
style MarkFailed fill:#ffcccc
style Success fill:#ccffcc
style SaveRatings fill:#ccffcc
style Finalize fill:#ccffcc
Схема статусов вопросов
stateDiagram-v2
[*] --> PENDING: Создан в claimSeries
PENDING --> PROCESSING: Захвачен лидом
PROCESSING --> COMPLETED: Успешно обработан<br/>и оценён
PROCESSING --> FAILED: Ошибка при обработке
COMPLETED --> [*]
FAILED --> [*]
note right of PROCESSING
Блокировка активна
TTL: 5s (вопрос) или 60s (серия)
end note
note right of COMPLETED
Финальный статус
Включает ratings и метрики
end note
Схема параллельной обработки (Run Leads Pool)
graph LR
subgraph "Run Leads Pool"
L1[Lead 1]
L2[Lead 2]
L3[Lead 3]
end
subgraph "Общий Report"
R[(eval_reports<br/>report_id=1)]
end
subgraph "Вопросы Suite"
Q1[Серия 1: Q1, Q2, Q3]
Q2[Серия 2: Q4, Q5]
Q3[Вопрос 6]
Q4[Вопрос 7]
end
subgraph "Блокировки (run_id=5)"
B1[eval_series_5_1]
B2[eval_series_5_2]
B3[eval_q_5_6]
B4[eval_q_5_7]
end
L1 -->|claimSeries| B1
L2 -->|claimSeries| B2
L3 -->|claimSeries| B3
B1 --> Q1
B2 --> Q2
B3 --> Q3
Q1 --> R
Q2 --> R
Q3 --> R
L1 -.->|Параллельно| L2
L2 -.->|Параллельно| L3
style R fill:#ccffcc
style B1 fill:#fff4cc
style B2 fill:#fff4cc
style B3 fill:#fff4cc
style B4 fill:#fff4cc
Ключевые моменты
Блокировки
- Все блокировки привязаны к
run_idдля изоляции параллельных запусков - Формат:
{prefix}_{runId}_{identifier} - TTL: 5s для вопросов, 60s для серий, 60s для финализации
- Освобождаются автоматически по TTL или через
bot.releaseLockForBot()
Таблицы
-
eval_runs- запуски тестов -
eval_reports- отчёты (один на run) -
eval_answers- ответы на вопросы (много на report) -
eval_questions- вопросы из suite -
llm_tracer- метрики производительности
Обработка ошибок
- Ошибки обрабатываются через
Eval_HandleError - Вопрос помечается как
FAILEDсerror_message - Тест продолжается со следующим вопросом
- Не влияет на другие лиды в пуле
- FAILED вопросы можно переобработать (не считаются занятыми)
Оптимизация запросов
- Используется
table.findс условиемINдля проверки статусов - Заменены
filter/mapна прямые запросы к БД где возможно - Проверка активных статусов:
["answer_status", "IN", ["pending", "processing", "completed"]] - Проверка финальных статусов:
["answer_status", "IN", ["completed", "failed"]]
Серии vs Standalone
- Серии захватываются целиком (все вопросы сразу)
- Standalone вопросы захватываются по одному
- История очищается перед началом новой серии
- Целостность серий проверяется при финализации