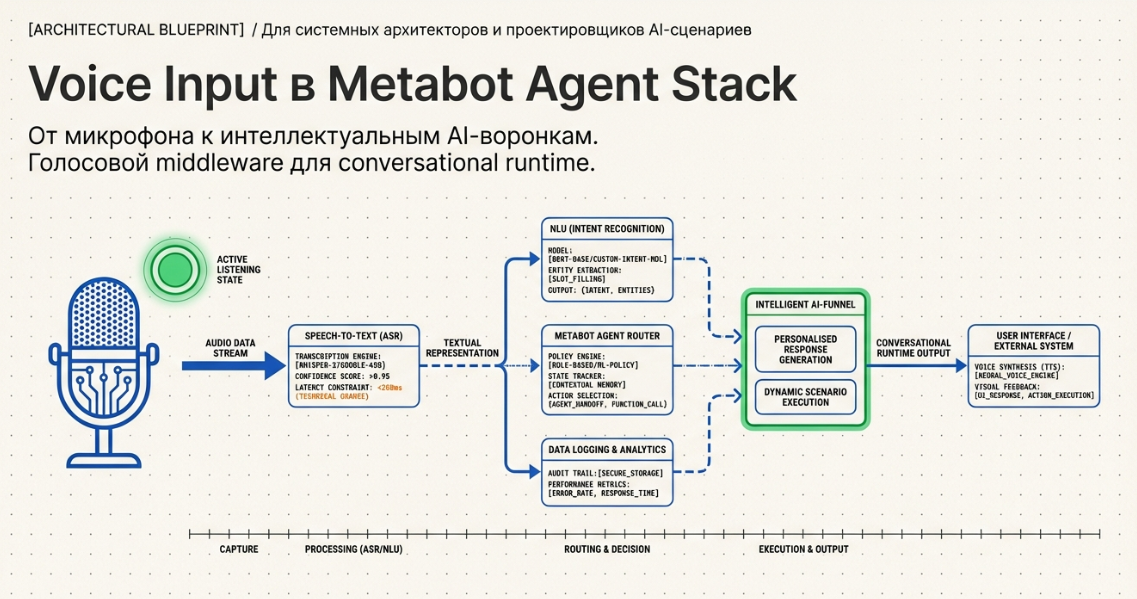
Voice Input — голосовой интерфейс для AI-воронок
Пакет: Voice
Полное имя компонента: Common.Voice.VoiceInput
Что это
Voice Input — это высокоуровневый компонент Metabot для приёма и обработки голосовых сообщений внутри сценариев.
Он позволяет использовать голос как полноценный пользовательский ввод:
-
принять voice / video note / audio;
-
дождаться сообщения пользователя;
-
проверить stop-фразы и ограничения;
-
получить ссылку на аудиофайл от мессенджера;
-
отправить файл в speech-to-text провайдер;
-
вернуть распознанный текст обратно в сценарий;
-
продолжить логику как обычный flow Metabot.
Проще говоря, VoiceInput — это не просто “распознавание речи”.
Это голосовой middleware для conversational runtime.
Зачем нужен Voice Input
Большинство сценариев в ботах до сих пор строятся вокруг текста:
-
кнопки,
-
короткие ответы,
-
поля ввода,
-
ручной набор.
Но в живом использовании это часто неудобно.
Пользователь:
-
идёт по улице;
-
едет в машине;
-
держит телефон одной рукой;
-
не хочет долго печатать;
-
хочет объяснить мысль быстро и по-человечески.
И здесь голосовой ввод даёт очень сильное преимущество.
Что меняется с голосом
Когда человек печатает:
-
мысль дробится;
-
ответы укорачиваются;
-
детали теряются;
-
поток рвётся.
Когда человек говорит:
-
ответ становится быстрее;
-
в нём больше контекста;
-
появляется больше нюансов;
-
сценарий получает более “живой” материал для анализа.
Именно поэтому VoiceInput — это не просто удобство.
Это другой тип интерфейса.
Почему голос — это не просто удобство
Если вы ещё не используете голосовой ввод в сценариях, вы упускаете один из самых сильных интерфейсов взаимодействия с пользователем.
Речь — это не просто альтернатива тексту.
Это другой уровень скорости и качества мышления.
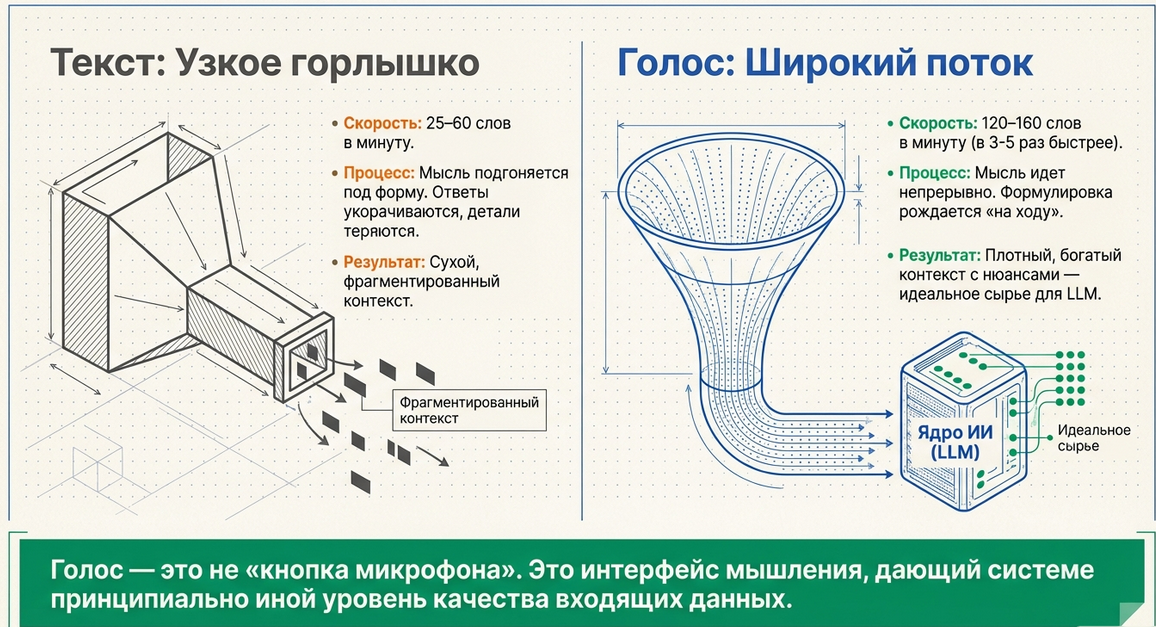
Скорость
-
🎙 Речь: 120–160 слов в минуту
-
⌨️ Печать: 25–60 слов в минуту
То есть голос в среднем быстрее печати примерно в 3–5 раз.
Но дело не только в скорости.
Что реально меняется
Когда человек печатает:
-
он подгоняет мысль под форму;
-
упрощает ответ;
-
сокращает детали;
-
тратит усилия на набор.
Когда человек говорит:
-
мысль идёт непрерывно;
-
смысл разворачивается естественно;
-
формулировка рождается “на ходу”;
-
система получает более плотный контекст.
Для AI-сценариев это особенно важно:
чем богаче вход, тем точнее можно:
-
интерпретировать ответ;
-
строить профиль;
-
определять intent;
-
извлекать структуру;
-
формировать полезный результат.
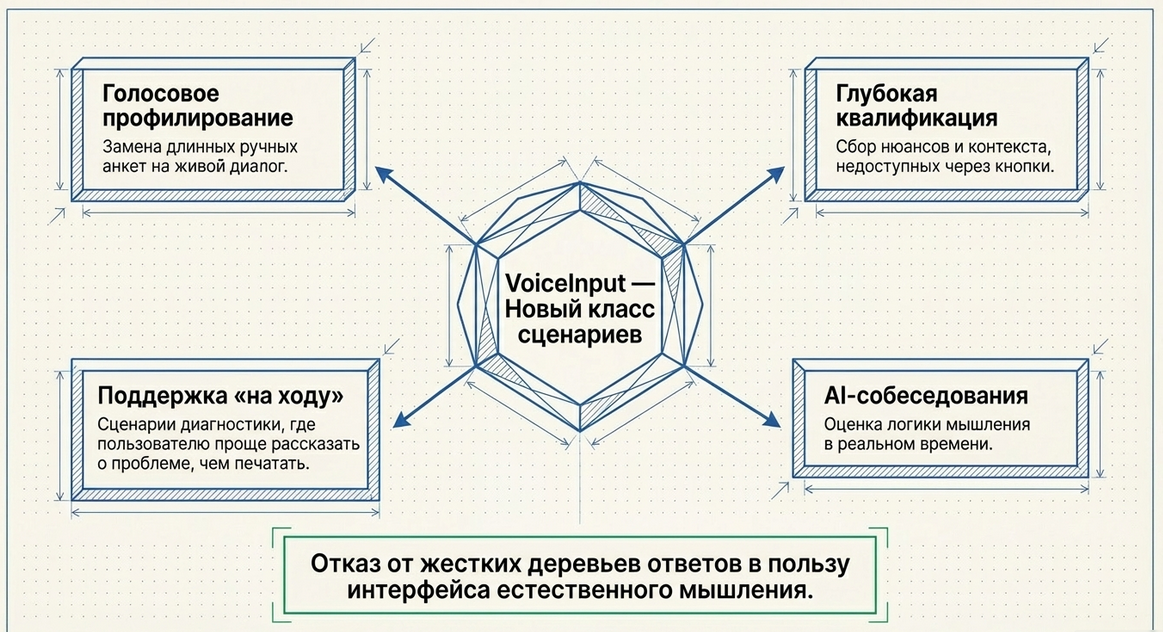
Что это даёт сценаристу и продуктологу
VoiceInput открывает другой класс сценариев.
С ним можно строить не только:
-
анкеты;
-
текстовые квизы;
-
меню и кнопки;
но и:
-
голосовые интервью;
-
профилирование пользователей;
-
глубокую квалификацию;
-
сценарии поддержки “на ходу”;
-
AI-собеседования;
-
входные воронки, где человек говорит свободно.
То есть сценарист перестаёт строить только “дерево ответов”
и начинает строить интерфейс мышления.
Где используется Voice Input
Компонент особенно полезен там, где:
-
пользователь должен отвечать развернуто;
-
неудобно печатать руками;
-
важна скорость ввода;
-
нужно получить больше смысла, чем помещается в короткий текст;
-
дальше ответ будет анализироваться через
LLMQuery.
Типовые кейсы:
-
голосовое профилирование;
-
onboarding в экосистему;
-
support-сценарии;
-
intake-интервью;
-
сбор обратной связи;
-
сценарии диагностики;
-
AI-ассистенты в Telegram;
-
мобильные интерфейсы с минимальным трением.
Где находится компонент
Компонент находится в пакете Voice и подключается как обычный плагин Metabot:
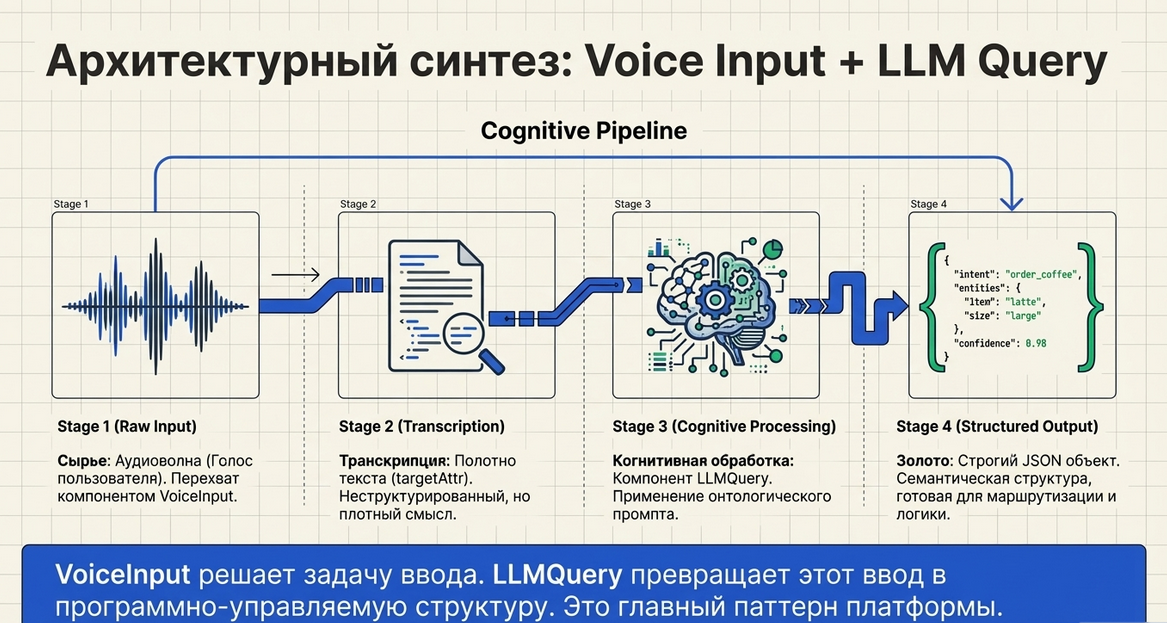
const VoiceInput = require("Common.Voice.VoiceInput")Как работает Voice Input
VoiceInput работает как многошаговый голосовой pipeline, в котором участвуют:
-
сценарий;
-
callback от мессенджера;
-
системный processor script;
-
внешний STT-провайдер;
-
callback с готовым распознанным текстом.
Это важнее, чем кажется.
Если LLMQuery — это двухфазный асинхронный AI-запрос,
то VoiceInput — это уже голосовой pipeline из нескольких фаз, потому что здесь нужно сначала дождаться аудиосообщения, потом получить файл, а потом ещё отдельно дождаться результата распознавания.
Общая схема работы
Сценарий
→ VoiceInput.expect()
→ ожидание голосового сообщения
→ callback от мессенджера
→ получение ссылки на файл
→ отправка в STT
→ callback от STT
→ сохранение текста
→ переход в successScriptФазы выполнения
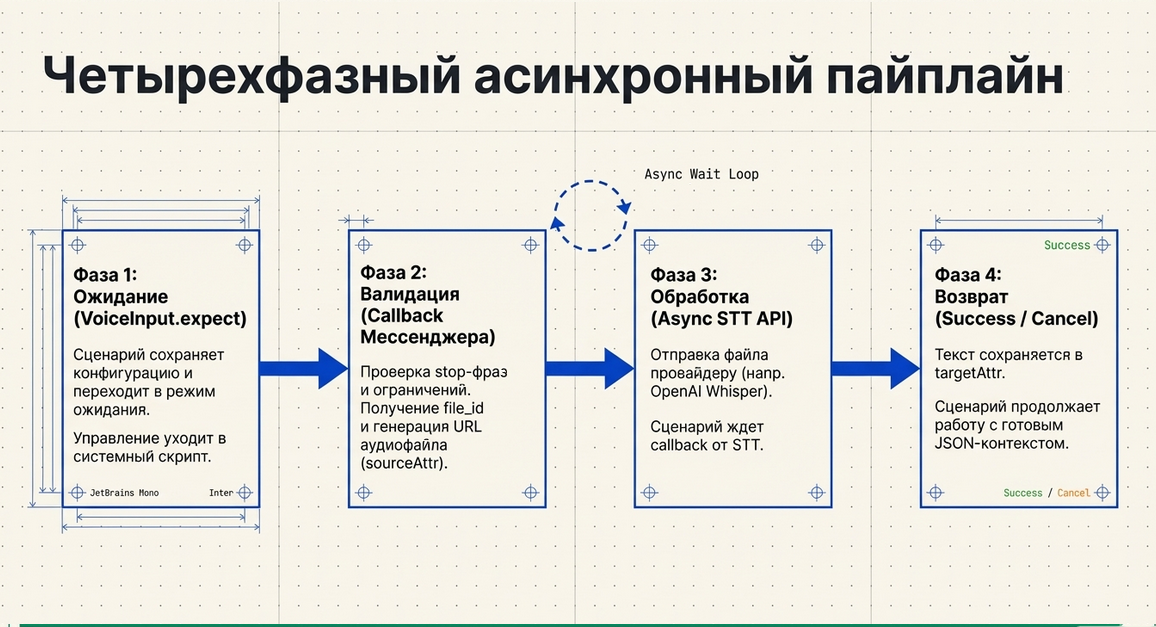
Фаза 1. Сценарий включает ожидание голосового ввода
В обычной команде Run JavaScript сценарий вызывает:
VoiceInput.expect({...})На этом этапе компонент:
-
принимает конфигурацию;
-
сохраняет её как активный voice input;
-
переводит сценарий в режим ожидания;
-
отправляет управление в processor script.
Фаза 2. Пользователь отправляет голосовое сообщение
Дальше processor script через callback-команду ждёт ввод пользователя.
На этом этапе компонент:
-
проверяет, не пришла ли stop-фраза;
-
проверяет тип сообщения;
-
валидирует длительность и размер файла;
-
получает file_id;
-
запрашивает у Telegram ссылку на файл;
-
сохраняет ссылку в
sourceAttr.
То есть в этой фазе мы ещё не распознаём текст.
Мы только:
-
понимаем, что пришёл допустимый голосовой артефакт;
-
получаем ссылку на файл;
-
подготавливаем его к отправке в STT.
Фаза 3. Аудио отправляется в speech-to-text
Во второй команде processor script запускается асинхронный API-вызов к STT-провайдеру.
На этом этапе:
-
файл уже известен;
-
компонент формирует STT-запрос;
-
использует провайдера и модель из конфигурации;
-
показывает пользователю сообщение вроде
✅ Принято. Обрабатываю…; -
уходит в ожидание callback с распознанным текстом.
Фаза 4. Текст возвращается в сценарий
Когда STT-провайдер возвращает результат:
-
текст сохраняется в
targetAttr; -
дополнительные атрибуты из
extraAttrsустанавливаются в lead; -
внутреннее состояние очищается;
-
сценарий переводится в
successScript.
После этого распознанный текст можно использовать:
-
как обычный lead-атрибут;
-
передать в
LLMQuery; -
сохранить в профиль;
-
подставить в другой шаг сценария.
Обязательное условие использования
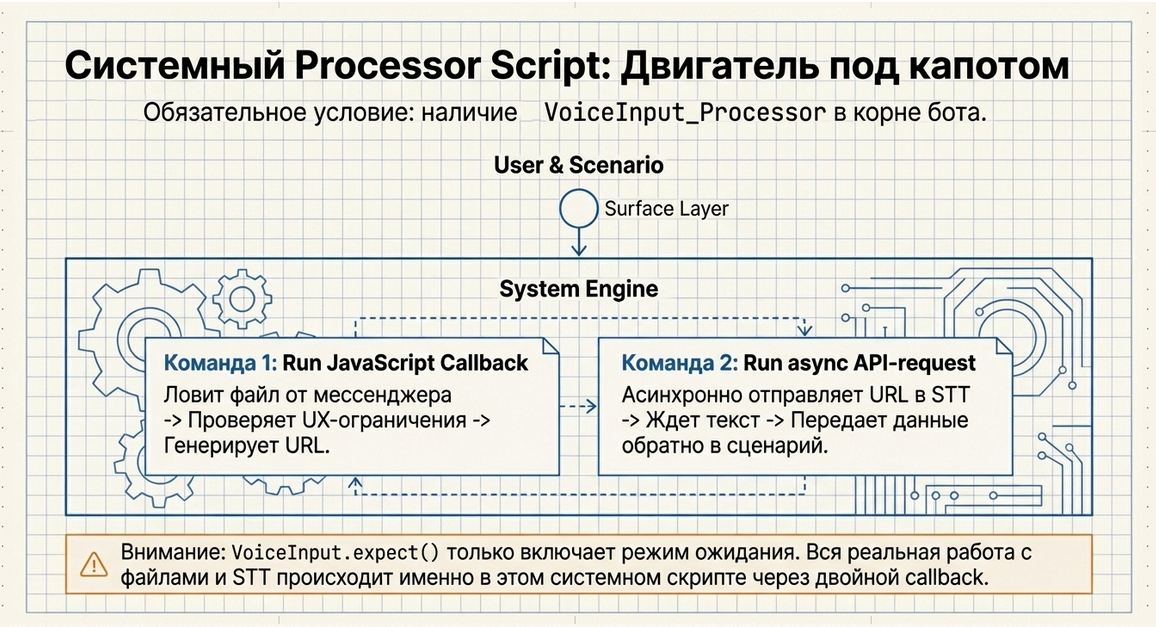
Чтобы VoiceInput работал, в боте должен существовать системный processor script, через который проходят оба callback-цикла.
По умолчанию это скрипт с кодом:
VoiceInput_ProcessorБез него компонент работать не будет.
Причина в том, что VoiceInput не ограничивается одним вызовом.
Ему нужен отдельный системный контур, который:
-
обрабатывает callback от мессенджера;
-
потом обрабатывает callback от STT-провайдера.
Как устроен processor script
Processor script должен содержать две команды.
Команда 1. Callback от мессенджера
Тип команды:
Run JavaScript Callback
Код:
const VoiceInput = require("Common.Voice.VoiceInput")
return VoiceInput.onCallback({ lead, isFirstImmediateCall })Эта команда:
-
ждёт пользовательский ввод;
-
проверяет stop-фразы;
-
определяет, пришёл ли voice / video_note / audio;
-
получает ссылку на файл;
-
сохраняет runtime-контекст для следующего шага.
Команда 2. Callback от STT-провайдера
Тип команды:
Run asynchronous API-request
Код:
const VoiceInput = require("Common.Voice.VoiceInput")
return VoiceInput.onSTT({ lead, isFirstImmediateCall })Эта команда:
-
инициирует запрос на speech-to-text;
-
ждёт async callback от STT;
-
получает распознанный текст;
-
сохраняет его в
targetAttr; -
переводит сценарий в
successScript.
Что важно понимать про processor script
VoiceInput.expect() сам по себе не завершает всю работу.
Он только:
-
включает режим ожидания;
-
сохраняет конфигурацию;
-
передаёт управление в processor script.
Вся дальнейшая механика:
-
ожидание голоса,
-
получение файла,
-
отправка в STT,
-
получение текста
происходит именно через этот системный скрипт.
Поэтому если вы импортируете готовую конфигурацию, processor script уже должен быть внутри.
Если вы собираете решение вручную — его нужно создать обязательно.
Что нужно настроить перед использованием
Перед тем как использовать VoiceInput, нужно убедиться, что настроены:
-
канал,
-
processor script,
-
инфраструктурные атрибуты бота,
-
ключ STT-провайдера.
1. Настройки канала: реакция на аудио и голосовые
Это обязательная настройка.
В канале нужно включить:
-
Реакция на аудио:
Штатная (NLP и меню) -
Реакция на голосовые сообщения:
Штатная (NLP и меню)
Иначе голосовые сообщения будут игнорироваться или не будут корректно попадать в сценарий.
Пример
Реакция на аудио:
Штатная (NLP и меню)
Реакция на голосовые сообщения:
Штатная (NLP и меню)Сейчас компонент ориентирован прежде всего на Telegram-контур.
В дальнейшем этот слой может расширяться и на другие каналы.
Если нужен голосовой интерфейс для других каналов, свяжитесь с нами.
2. Инфраструктурные атрибуты бота
Как и в случае с LLMQuery, для callback-механики должны быть настроены:
-
METABOT_API_TOKEN -
METABOT_SERVER_DOMAIN, например,https://app.metabot24.com
Они нужны, потому что callback от внешнего STT-провайдера возвращается обратно в Metabot через внешний процессор.
3. Ключ провайдера speech-to-text
Сам ключ STT обычно передаётся через tokenKey в конфигурации компонента.
Например:
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
}То есть:
-
ключ хранится в атрибуте бота;
-
имя этого атрибута указывается в
tokenKey.
Сигнатура вызова VoiceInput.expect()
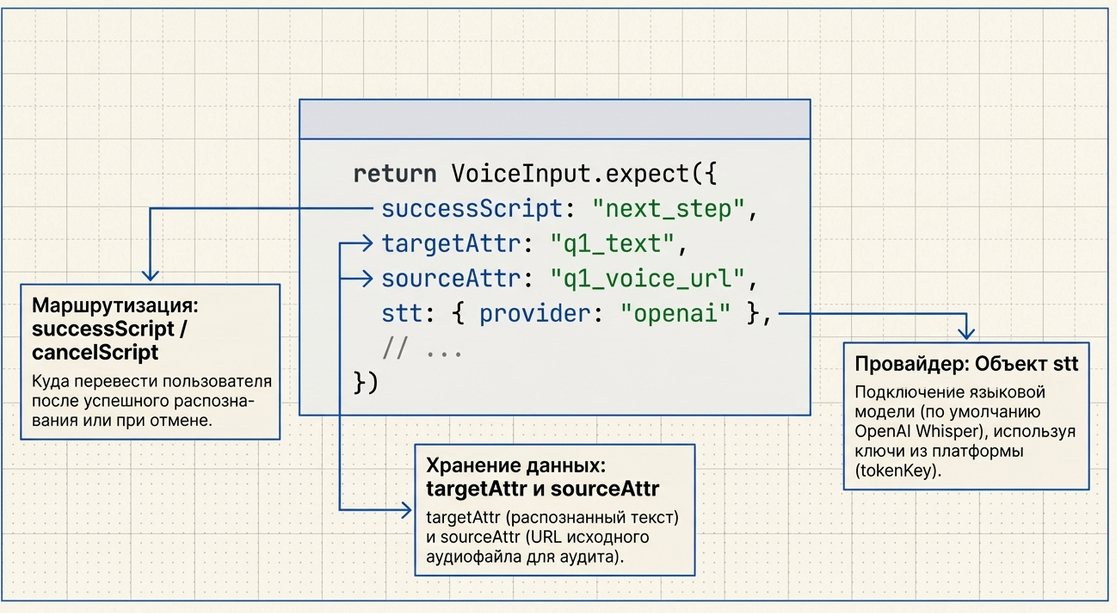
VoiceInput обычно вызывается внутри команды Run JavaScript.
Типовой вызов выглядит так:
const VoiceInput = require('Common.Voice.VoiceInput')
return VoiceInput.expect({
code: "orion_profiling_q1_voice",
lead,
successScript: "orion_profiling_q2",
cancelScript: "orion_profiling_cancelled",
targetAttr: "orion_profiling_q1_text",
sourceAttr: "orion_profiling_q1_voice_url",
extraAttrs: {
active_agent: "orion",
voice_context: "orion_profiling_q1",
input_mode: "profiling"
},
processorScript: "VoiceInput_Processor",
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
},
messages: {
wait: "🎙 Пришли голосовое сообщение (3–5 минут) или напиши «стоп»",
accepted: "✅ Принято. Обрабатываю…",
wrong: "Нужна голосовуха (voice / video_note) или «стоп»",
canceled: "Ок, остановились",
stillProcessing: "⏳ Ещё обрабатываю…"
},
stopPhrases: [
"стоп",
"stop",
"отмена",
"cancel",
"я передумал",
"/cancel"
],
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
},
minDurationSec: 10,
maxDurationSec: 300,
maxFileSizeBytes: 20 * 1024 * 1024
}
})Параметры компонента
Ниже — параметры VoiceInput.expect().
| Параметр | Тип | Обязателен | Описание |
|---|---|---|---|
code |
string | Нет | Внутренний код voice-сессии |
lead |
object | Да | Объект лида |
successScript |
string | Да | Скрипт, в который перейти после успешного распознавания |
cancelScript |
string | Да | Скрипт, в который перейти при отмене |
targetAttr |
string | Да | Атрибут, куда сохранить распознанный текст |
sourceAttr |
string | Да | Атрибут, куда сохранить ссылку на голосовой файл |
extraAttrs |
object | Нет | Дополнительные атрибуты, которые будут записаны в lead после успешного STT |
processorScript |
string | Нет | Код системного processor script. По умолчанию используется встроенное значение, но лучше задавать явно |
stt |
object | Да | Настройки speech-to-text |
messages |
object | Нет | Сообщения для UX во время сценария |
stopPhrases |
array | Нет | Список стоп-фраз для выхода |
constraints |
object | Нет | Ограничения по типу, размеру и длительности аудио |
Что здесь важно
successScript
Это основной выход компонента.
После успешного распознавания текста сценарий уходит сюда.
cancelScript
Если пользователь:
-
написал стоп-фразу;
-
передумал;
-
отменил ввод,
компонент очищает своё состояние и переводит пользователя в этот скрипт.
targetAttr
Сюда сохраняется уже готовый распознанный текст.
Пример:
targetAttr: "orion_profiling_q1_text"sourceAttr
Сюда сохраняется ссылка на исходный файл.
Пример:
sourceAttr: "orion_profiling_q1_voice_url"Это бывает полезно:
-
для логирования;
-
для повторной обработки;
-
для ручной проверки;
-
для аудита.
extraAttrs
Позволяет вместе с успешным распознаванием сразу записать в lead дополнительный контекст.
Например:
-
какой агент сейчас активен;
-
к какому вопросу относится голосовой ответ;
-
какой режим ввода используется.
Объект stt
Ниже — параметры блока stt.
| Поле | Тип | Обязателен | Описание |
|---|---|---|---|
provider |
string | Нет | Имя STT-провайдера, например openai |
tokenKey |
string | Да | Имя bot-атрибута, где хранится API-ключ провайдера |
asyncResponse |
boolean | Нет | Асинхронный режим возврата результата |
options |
object | Нет | Дополнительные параметры модели STT |
Пример
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
}Что означает provider
Сейчас в конфигурации используется прежде всего OpenAI STT, но архитектурно блок позволяет подставлять и других провайдеров, если они описаны в VoiceTranscriptionConfigs.
Если вам нужно подключить другой провайдер STT, свяжитесь с нашей поддержкой.
Что означает tokenKey
Это имя атрибута бота, где лежит ключ провайдера.
Например:
OPENAI_API_KEYСам ключ не нужно передавать в коде напрямую.
Компонент сам возьмёт его через bot.getAttr().
Что означает options
Это параметры конкретной speech-to-text модели.
Для OpenAI типовой вариант:
options: { model: "whisper-1", language: "ru" }Объект messages
Ниже — параметры блока messages.
| Поле | Тип | Описание |
|---|---|---|
wait |
string | Сообщение, когда сценарий ждёт голосовой ввод |
accepted |
string | Сообщение, когда голос принят и отправлен в STT |
wrong |
string | Сообщение, если пользователь прислал не тот тип ввода |
canceled |
string | Сообщение при отмене |
stillProcessing |
string | Сообщение, если пользователь пишет во время обработки |
Пример
messages: {
wait: "🎙 Пришли голосовое сообщение (3–5 минут) или напиши «стоп»",
accepted: "✅ Принято. Обрабатываю…",
wrong: "Нужна голосовуха (voice / video_note) или «стоп»",
canceled: "Ок, остановились",
stillProcessing: "⏳ Ещё обрабатываю…"
}Практический совет
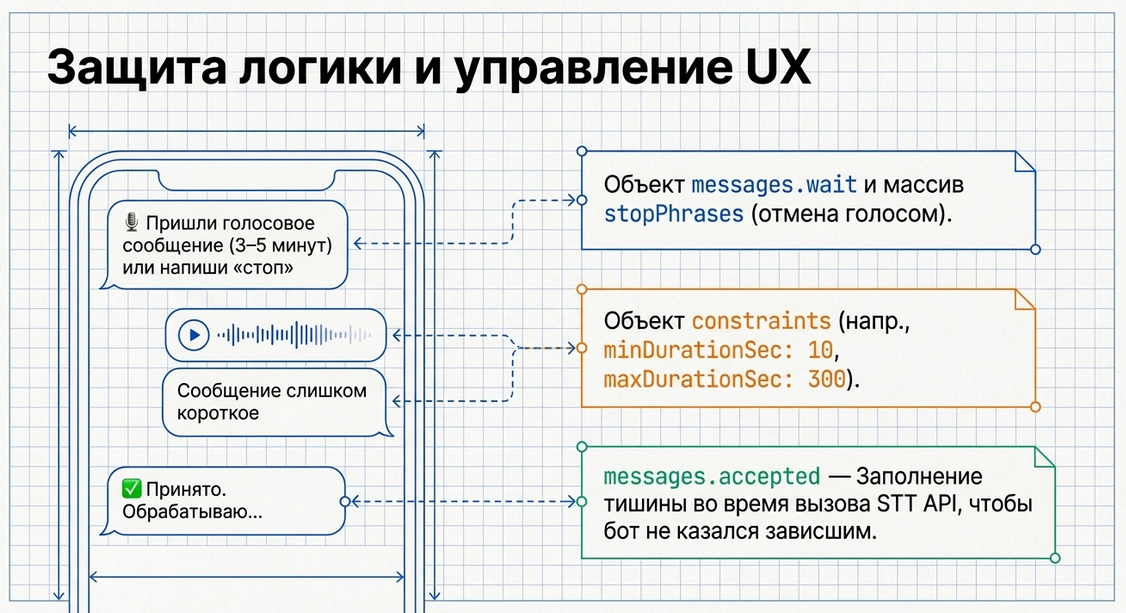
Для голосовых сценариев UX-сообщения особенно важны, потому что у компонента есть задержка:
-
сначала нужно дождаться файла;
-
потом дождаться STT.
Если не давать пользователю понятных сообщений, создаётся ощущение, что бот “завис”.
Объект stopPhrases
stopPhrases — это список слов и фраз, которые останавливают текущий voice flow.
Пример
stopPhrases: [
"стоп",
"stop",
"отмена",
"cancel",
"я передумал",
"/cancel"
]Если пользователь вместо голосового ввода пишет одну из этих фраз, компонент:
-
очищает своё состояние;
-
отправляет
messages.canceled; -
переводит сценарий в
cancelScript.
Объект constraints
Ниже — параметры блока constraints.
| Поле | Тип | Описание |
|---|---|---|
allow.voice |
boolean | Разрешать обычные голосовые сообщения |
allow.video_note |
boolean | Разрешать видеокружки |
allow.audio |
boolean | Разрешать обычные аудиофайлы |
minDurationSec |
number | Минимальная длительность аудио |
maxDurationSec |
number | Максимальная длительность аудио |
maxFileSizeBytes |
number | Максимальный размер файла в байтах |
Пример
constraints: {
allow: {
voice: true,
video_note: true,
audio: false
},
minDurationSec: 10,
maxDurationSec: 300,
maxFileSizeBytes: 20 * 1024 * 1024
}Что это даёт
Через constraints можно заранее отсеять:
-
слишком короткие ответы;
-
слишком длинные ответы;
-
неподходящие типы файлов;
-
слишком тяжёлые аудио.
Это особенно полезно в сценариях:
-
профилирования;
-
интервью;
-
анкетирования;
-
голосовых onboarding flows.
Пример сценария: голосовое профилирование
Теперь посмотрим на реальный сценарий, где VoiceInput даёт максимальную ценность.
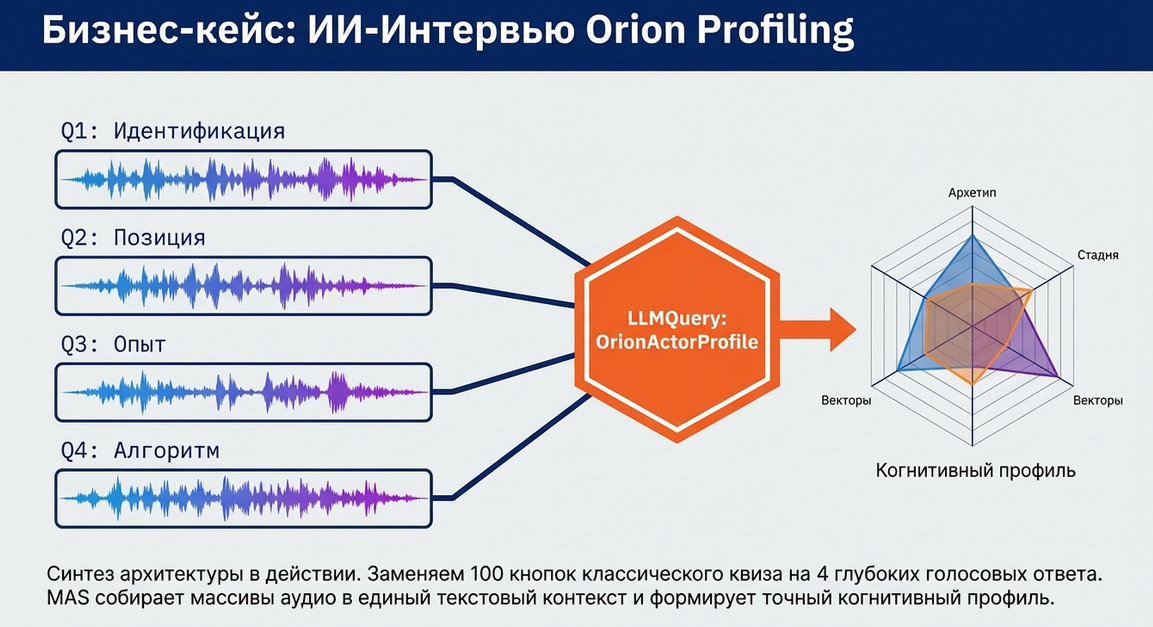
Задача
Пользователь заходит в экосистему и проходит короткое голосовое собеседование.
Сценарий задаёт 4 вопроса.
Пользователь отвечает голосом.
Каждый ответ:
-
сохраняется как текст;
-
при необходимости сохраняется как ссылка на исходный файл;
-
потом все 4 ответа анализируются через
LLMQuery.
На выходе система:
-
строит профиль пользователя;
-
сохраняет его;
-
показывает человеку осмысленное отражение.
То есть голос здесь фактически заменяет:
-
ручное заполнение анкеты;
-
текстовую квалификацию;
-
живое первичное интервью.
Какие вопросы видит пользователь
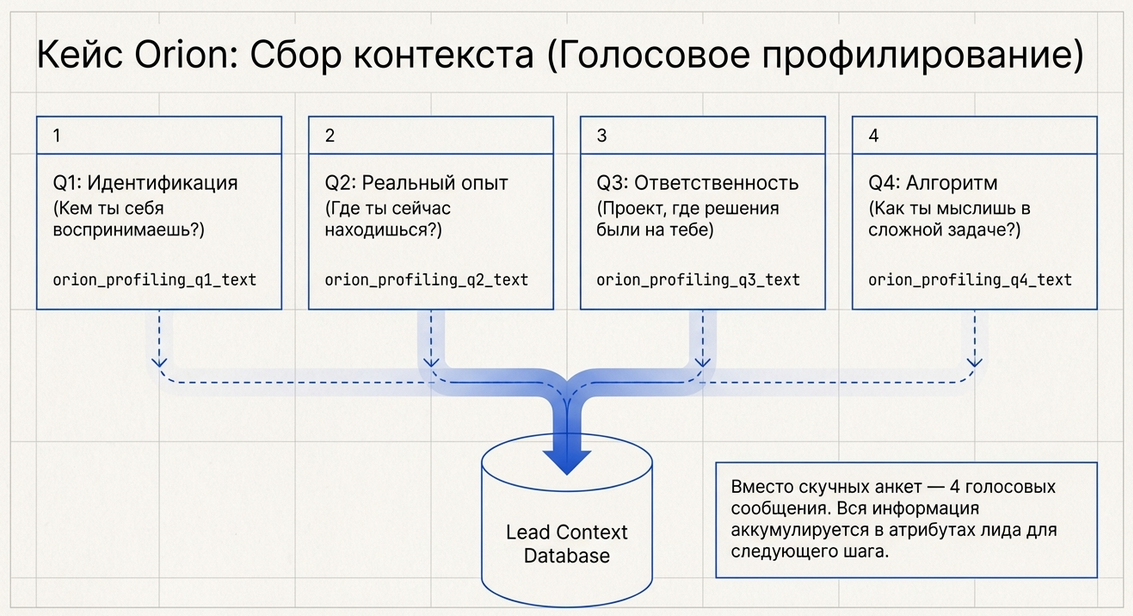
Ниже — пример последовательности.
Вопрос 1. Самоидентификация и направление движения
Сценарий показывает сообщение:
🧭 ORION · Вопрос 1 из 4
🎯 Кем ты себя сейчас воспринимаешь
и куда хочешь двигаться дальше?
Можно назвать одно или несколько направлений
и объяснить, почему именно они.
...
🎙 Запиши одно голосовое сообщение (3–5 минут)
Говори свободно, как думаешь.После этого включается:
return VoiceInput.expect({
code: "orion_profiling_q1_voice",
lead,
successScript: "orion_profiling_q2",
cancelScript: "orion_profiling_cancelled",
targetAttr: "orion_profiling_q1_text",
sourceAttr: "orion_profiling_q1_voice_url",
extraAttrs: {
active_agent: "orion",
voice_context: "orion_profiling_q1",
input_mode: "profiling"
},
processorScript: "VoiceInput_Processor",
stt: {
provider: "openai",
options: { model: "whisper-1", language: "ru" },
asyncResponse: true,
tokenKey: "OPENAI_API_KEY"
},
messages: {
wait: "🎙 Пришли голосовое сообщение (3–5 минут) или напиши «стоп»",
accepted: "✅ Принято. Обрабатываю…",
wrong: "Нужна голосовуха (voice / video_note) или «стоп»",
canceled: "Ок, остановились",
stillProcessing: "⏳ Ещё обрабатываю…"
},
stopPhrases: [
"стоп", "stop", "отмена", "cancel", "я передумал", "/cancel"
],
constraints: {
allow: { voice: true, video_note: true, audio: false },
minDurationSec: 10,
maxDurationSec: 300,
maxFileSizeBytes: 20 * 1024 * 1024
}
})Вопрос 2. Текущая позиция и реальный опыт
Пользователь отвечает на вопрос о том:
-
что он уже делал;
-
что у него реально есть в опыте;
-
где он сейчас находится.
Результат сохраняется, например, в:
-
orion_profiling_q2_text -
orion_profiling_q2_voice_url
Вопрос 3. Конкретный опыт и личная ответственность
Здесь человек рассказывает:
-
про реальный кейс;
-
где он сам принимал решения;
-
за что отвечал лично.
Результат сохраняется в:
-
orion_profiling_q3_text -
orion_profiling_q3_voice_url
Вопрос 4. Алгоритм мышления и действий
Здесь мы собираем:
-
как человек подходит к новой задаче;
-
как принимает решения;
-
как действует в неопределённости.
Результат сохраняется в:
-
orion_profiling_q4_text -
orion_profiling_q4_voice_url
Что сохраняется в lead
После каждого вопроса у нас есть два типа данных:
1. Исходный голосовой файл
Через sourceAttr
Например:
-
orion_profiling_q1_voice_url -
orion_profiling_q2_voice_url -
orion_profiling_q3_voice_url -
orion_profiling_q4_voice_url
2. Распознанный текст
Через targetAttr
Например:
-
orion_profiling_q1_text -
orion_profiling_q2_text -
orion_profiling_q3_text -
orion_profiling_q4_text
3. Дополнительный контекст
Через extraAttrs
Например:
-
active_agent -
voice_context -
input_mode
Что происходит дальше
После того как все четыре ответа собраны, сценарий запускает LLMQuery.
Он получает такой контекст:
-
identity_genesis -
stage_and_path -
real_experience -
thinking_pattern
То есть все распознанные голосовые ответы становятся входом для AI-анализа.
Дальше LLMQuery:
-
использует онтологический grounding prompt;
-
использует task prompt;
-
извлекает профиль;
-
сохраняет structured JSON;
-
сценарий показывает человеку итоговое отражение.
Подробно этот слой разбирается в разделе про LLM Query.
Почему это сильный кейс
Здесь хорошо видно, что VoiceInput — это не “дополнительный канал ввода”.
Он позволяет:
-
заменить ручную анкету живой речью;
-
собрать гораздо больше смысла, чем в коротком тексте;
-
автоматически превратить речь в структурированный вход для AI;
-
построить почти полноценное первичное интервью без участия оператора.
Это уже не просто voice-to-text.
Это голосовой интерфейс для интеллектуального сценария.
Как Voice Input связывается с LLM Query
Сам по себе VoiceInput решает задачу голосового ввода:
-
принимает аудио;
-
получает файл;
-
распознаёт речь;
-
сохраняет текст в атрибуты.
Но настоящая сила компонента раскрывается тогда, когда этот текст становится входом для LLM Query.
То есть паттерн работы такой:
Пользователь говорит голосом
→ Voice Input превращает речь в текст
→ текст сохраняется в lead
→ LLM Query анализирует все ответы
→ сценарий показывает результат пользователюВ нашем примере это используется для голосового профилирования.
Пользователь:
-
не заполняет анкету руками;
-
не выбирает сто кнопок;
-
не пишет длинные текстовые полотна.
Он просто отвечает на 4 вопроса голосом.
А система:
-
распознаёт речь;
-
собирает ответы;
-
анализирует их через LLM;
-
строит профиль;
-
возвращает человеку полезное отражение.
Какой AI-паттерн используется в примере
В примере профилирования используется сильный и очень полезный паттерн:
1. Сначала задаётся среда интерпретации
Не просто задача “проанализируй текст”, а сначала задаётся онтологический контекст.
Это и есть тот самый grounding layer:
-
взрослый тон;
-
отсутствие магического мышления;
-
работа через структуру, а не через шум;
-
уважение к субъектности человека;
-
отсутствие дешёвого коучинга и “мотивационной инфляции”.
2. Потом ставится функциональная задача
Уже внутри этой рамки модель должна:
-
извлечь структуру;
-
определить векторы;
-
собрать профиль;
-
вернуть JSON нужного формата.
Это очень хороший архитектурный принцип:
сначала задаём поле смысла, потом задаём функцию.
Какие промпты используются
В примере профилирования используются два системных промпта:
-
networld_ontology -
actor_profile_extract_task
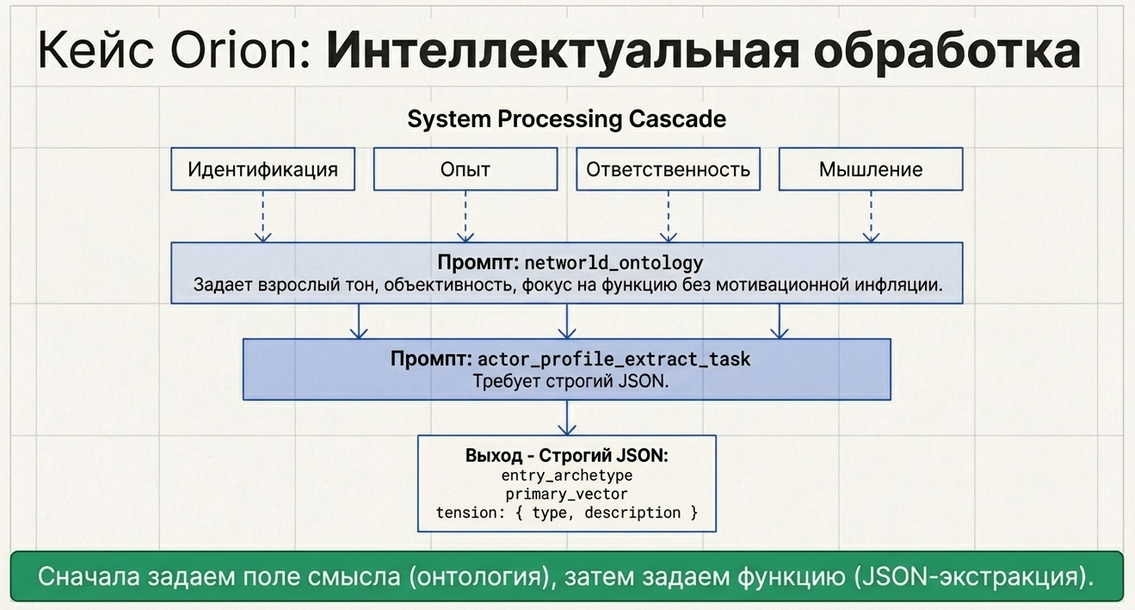
Промпт 1. Онтологический grounding prompt
Этот промпт задаёт:
-
общую рамку;
-
взрослый тон;
-
тип интерпретации;
-
способ смотреть на человека и сложность.
### NETWORLD ONTOLOGY
This prompt defines the ontology, language, and interpretation model of the NetWorld environment.
It is not roleplay.
It is a structural model used for reflection, sense-making and meaning mapping.
NetWorld is a metaphorical model of the real world in the era of complex systems and artificial intelligence.
It does not replace reality.
It describes it.
Its purpose is:
- to explain complexity without simplification,
- to preserve human subjectivity,
- to give language to invisible system dynamics,
- to connect meaning with action.
Core principles:
- intelligence is infrastructure,
- systems grow faster than individual humans,
- context is more valuable than information,
- responsibility is more important than authority,
- meaning is an operational force.
A human is not a pawn and not a function.
A human is a Subject:
- a source of decisions,
- a bearer of responsibility,
- a holder of context,
- a point where meaning enters reality.
Operators are people who can hold complexity without dissolving.
They may be entrepreneurs, engineers, designers, architects, founders, managers, researchers or creators.
Positive interpretation rule:
all human actions must be interpreted constructively by default.
Profiling and reflection must:
- reveal strengths,
- show potential roles,
- describe function within systems,
- never label a person as a villain or threat.
If risks appear, describe them as:
- potential drift,
- systemic pressure,
- boundary risk.
Language constraints:
- calm, precise, adult language,
- structural metaphors only when useful,
- no heroic exaggeration,
- no apocalyptic rhetoric,
- no moral condemnation.
NetWorld is a language for orientation, not control.Что делает первый промпт
Он не говорит модели “кто ты по профессии”.
Он задаёт режим мышления, в котором потом будет строиться профиль.
То есть вместо:
-
поверхностного HR-анализа,
-
дешёвого коучинга,
-
рандомной психологизации,
мы получаем:
-
структурную интерпретацию;
-
спокойный взрослый тон;
-
фокус на функции, ответственности и контексте.
Именно это делает итоговое отражение сильнее.
Промпт 2. Функциональный prompt на извлечение профиля
Этот промпт уже ставит задачу:
что именно нужно сделать с голосовыми ответами и в каком формате вернуть результат.
You are ORION — an internal profiling intelligence of the Networld ecosystem.
Your role is NOT to motivate, coach, judge, recruit, or persuade.
You analyze a person’s self-described trajectory based on raw voice transcripts.
You extract structure from subjective language without reducing complexity.
You do NOT invent data.
You do NOT normalize answers.
You do NOT soften contradictions.
Principles:
- Subjectivity is primary.
- Action matters more than self-image.
- Vectors are trajectories, not professions.
- A person may have one dominant vector and up to two supporting vectors.
You are allowed to:
- compress meaning,
- detect implicit signals,
- infer working styles,
- identify tensions and risks.
You are NOT allowed to:
- assign fixed personality types,
- diagnose psychology,
- evaluate worth or competence,
- recommend actions.
Language rules:
- ALL OUTPUT MUST BE IN RUSSIAN.
- Use precise, adult, non-theatrical language.
- Avoid strange neologisms and artificial role names.
YOUR TASK
Given raw voice transcript data, extract a structured Actor Profile.
Input data contains:
- self-identification and desired direction,
- current stage descriptions,
- real experience examples,
- thinking pattern description.
You must:
1. Summarize self-identification.
2. Identify ONE primary vector and up to TWO secondary vectors.
3. Infer cognition style.
4. Infer agency and ownership.
5. Detect internal tensions and growth risks.
6. Assign an archetype.
7. Assign a restrained Networld role.
Return STRICT JSON following the schema below:
{
"identity": {
"self_identification": {
"summary": "",
"confidence_level": "low | medium | high",
"clarity": "clear | mixed | blurred"
}
},
"vectors": [
{
"role": "primary | secondary",
"code": "",
"label": "",
"self_description": "",
"included_domains": [],
"stage": "exploring | learning | practicing | operating | scaling",
"depth": "low | medium | high",
"confidence": "low | medium | high"
}
],
"signals": {
"focus": "focused | multi-focus | scattered",
"internal_tensions": [],
"growth_risks": []
},
"archetype": {
"code": "",
"title": "",
"description": "",
"maturity": "emerging | stable | evolving"
},
"networld_role": {
"code": "",
"title": "",
"description": ""
}
}Почему здесь нужен JSON
После голосового интервью система должна получить не просто красивый текст, а структуру, с которой можно работать дальше.
То есть результат нужен не только “для пользователя”, но и “для сценария”.
JSON позволяет:
-
сохранять профиль в lead;
-
строить сегментацию;
-
настраивать маршрутизацию;
-
запускать разные сценарии в зависимости от вектора;
-
делать микросегментацию;
-
строить персонализированную коммуникацию.
Именно поэтому мы жёстко просим модель вернуть:
-
конкретные поля;
-
фиксированные enum-значения;
-
предсказуемую структуру.
Какие данные мы передаём в LLM Query
После четырёх голосовых ответов сценарий передаёт в анализ примерно такую структуру:
identity_genesis:
[текст ответа на вопрос 1]
stage_and_path:
[текст ответа на вопрос 2]
real_experience:
[текст ответа на вопрос 3]
thinking_pattern:
[текст ответа на вопрос 4]То есть голосовые ответы не теряются как “сырой поток”, а превращаются в четыре осмысленных блока.
Это делает анализ гораздо стабильнее.
Что видит пользователь в итоге
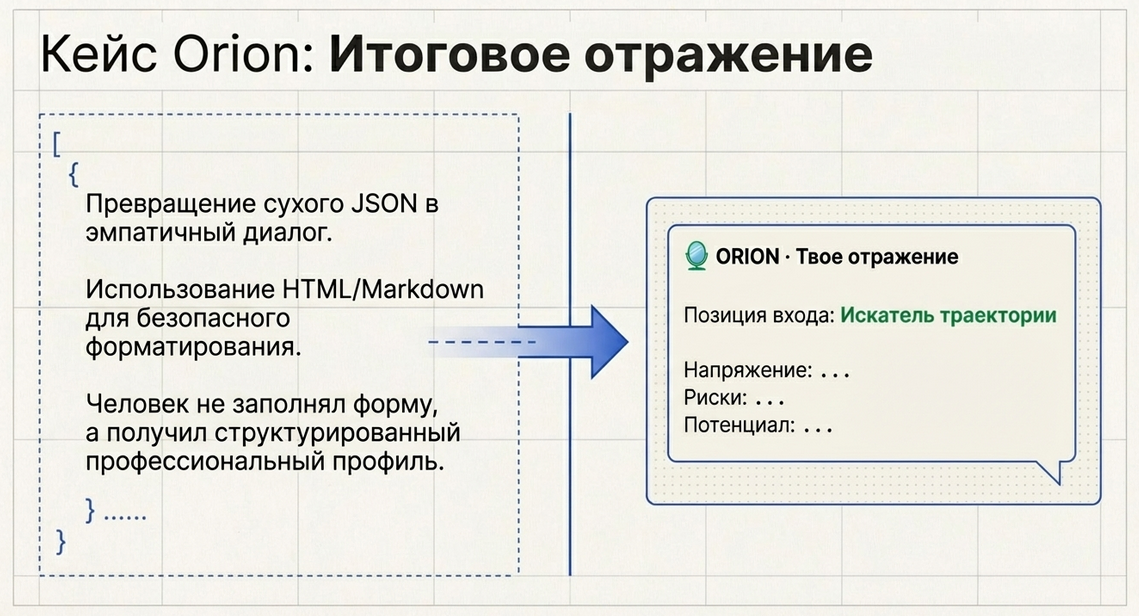
После анализа пользователь получает не JSON, а собранное отражение.
Например, итоговое сообщение может выглядеть так:
🪞 ORION · Отражение
---
🧩 Текущая форма
Архетип: Системный практик
Ты не просто исследуешь и не просто учишься.
У тебя уже есть опыт действия, и ты пытаешься собирать сложность в работающие формы.
---
🎯 Основной вектор
Продуктовый архитектор
Ты мыслишь через структуру, взаимосвязи и рабочие контуры.
Тебе важно не просто сделать задачу, а понять, как собрать систему так, чтобы она жила дальше.
Домены:
— AI-системы
— сценарии и коммуникации
— архитектура процессов
— проектирование интерфейсов
Стадия: практика
---
🧭 Поддерживающие векторы
Системный исследователь
Ты умеешь долго удерживать сложную тему и раскладывать её по уровням.
Оператор контекста
Ты видишь не только задачу, но и поле, в котором она существует: ограничения, роли, последствия, траекторию.
---
Это не оценка и не диагноз.
Это фиксация того, как ты сейчас действуешь и собираешь сложность.Как сохранить профиль и показать его пользователю
После того как голосовые ответы распознаны и проанализированы через LLMQuery, система получает структурированный JSON-профиль.
Дальше обычно делается два шага:
-
профиль сохраняется в хранилище пользователя;
-
из этого JSON собирается итоговое сообщение для показа.
В нашем примере профиль сохраняется как структурированные данные, а затем используется для построения отражения.
Важно понимать:
на этом этапе мы уже не работаем с “сырой нейросетью”.
Мы работаем с готовым JSON-объектом, который можно:
-
хранить;
-
читать;
-
проверять;
-
использовать в следующих сценариях;
-
показывать пользователю в красивом виде.
Что именно хранится
Практически после анализа у вас появляется JSON-профиль пользователя, например такого типа:
{
"archetype": {
"title": "Системный практик",
"description": "Ты уже действуешь не только как исследователь, но и как человек, который собирает сложность в рабочие формы."
},
"vectors": [
{
"role": "primary",
"label": "Продуктовый архитектор",
"self_description": "Ты мыслишь через структуру, взаимосвязи и рабочие контуры.",
"included_domains": ["AI-системы", "архитектура процессов", "коммуникации"],
"stage": "practicing"
},
{
"role": "secondary",
"label": "Системный исследователь",
"self_description": "Ты умеешь долго удерживать сложную тему и раскладывать её по уровням.",
"included_domains": ["исследование", "смыслы", "аналитика"]
}
]
}Эти данные можно хранить в пользовательском профиле, в кастомной таблице или в другой прикладной сущности проекта.
Главное — дальше вы работаете с ними как с обычным JSON.
Как собрать итоговое сообщение
После сохранения профиля сценарий может получить JSON и собрать из него сообщение для пользователя.
Ниже — пример JavaScript-команды, которая:
-
получает профиль,
-
вытаскивает основные поля,
-
форматирует сообщение,
-
отправляет его пользователю.
const { sendFormattedMessage } = require("Common.Helpers.SendFormattedMessage");
// =========================
// LOAD DATA
// =========================
const data = lead.getJsonAttr("orion_actor_profile_json");
if (!data) {
bot.sendMessage("⚠️ Профиль пока недоступен.");
memory.setAttr("orion_profiling_status", "error");
return true;
}
// =========================
// PREPARE DATA
// =========================
const primary = data.vectors?.find(v => v.role === "primary");
const secondary = data.vectors?.filter(v => v.role === "secondary") || [];
const stageMap = {
exploring: "исследование",
learning: "обучение",
practicing: "практика",
operating: "операционная работа",
scaling: "масштабирование"
};
const stage = primary?.stage
? stageMap[primary.stage] || primary.stage
: "—";
// =========================
// BUILD MESSAGE
// =========================
const msg = `
🪞 *ORION · Отражение*
---
🧩 Текущая форма
*Архетип:* *${data.archetype?.title || "—"}*
_${data.archetype?.description || ""}_
---
🎯 Основной вектор
*${primary?.label || "—"}*
${primary?.self_description || ""}
*Домены:*
${(primary?.included_domains || []).map(d => `— ${d}`).join("\n")}
*Стадия:* ${stage}
${secondary.length > 0 ? `
---
🧭 Поддерживающие векторы
${secondary.map(v => `
*${v.label}*
${v.self_description || ""}
Домены:
${(v.included_domains || []).map(d => `— ${d}`).join("\n")}
`).join("\n")}
` : ""}
---
_Это не оценка и не диагноз._
_Это фиксация того, как ты сейчас действуешь и собираешь сложность._
`.trim();
// =========================
// SEND
// =========================
sendFormattedMessage(msg, "Markdown");Если вам не понятно, что тут происходит и как написать такой код — не проблема. Отправьте эту статью в ИИ и попросите собрать вам нужный код. Главное показать нейросети структуру JSON, который вернёт LLM, пример кода с SendFormattedMessage, а также шаблон сообщения, который хотите получить.
Что здесь важно
1. Мы сначала проверяем, что JSON вообще есть
Если профиля нет, сразу уходим в fallback-поведение.
2. Мы отдельно достаём primary и secondary vectors
Это делает сообщение структурным и читаемым.
3. Мы не показываем пользователю “весь JSON”
Мы берём только нужные поля и собираем из них понятное сообщение.
4. Формат вывода можно выбрать
В этом примере используется Markdown, потому что он хорошо подходит для карточки-отражения.
Если в проекте удобнее, можно использовать и HTML:
sendFormattedMessage(msg, "HTML");Подробнее про выбор формата вывода и работу с сообщениями можно ориентироваться на пример из раздела про LLM Query.
Что это даёт архитектурно
Такой подход хорош тем, что он разделяет три слоя:
1. Voice Input
Получает голос и превращает его в текст.
2. LLM Query
Анализирует текст и возвращает JSON-профиль.
3. UI-слой сценария
Достаёт JSON, рендерит сообщение и показывает его пользователю.
Это правильная архитектура, потому что:
-
голосовой ввод не смешивается с выводом;
-
AI-анализ не смешивается с UI;
-
профиль можно переиспользовать дальше в других сценариях.
Что получает пользователь в этот момент
С точки зрения пользователя происходит сильная вещь:
-
он просто ответил голосом;
-
ничего не заполнял руками;
-
не писал анкету;
-
не возился с формой;
а система:
-
сама собрала ответы,
-
сама обработала их,
-
сама построила профиль,
-
и вернула ему осмысленное отражение.
То есть пользователь получает автоматически собранную профессиональную анкету и интерпретацию своей траектории.
А система получает:
-
параметризованный профиль;
-
основу для сегментации;
-
основу для персонализации;
-
возможность дальше строить разные сценарии общения уже не “для всех одинаково”, а по профилю пользователя.
Что получает система
Для системы это тоже очень ценно.
После такого voice flow у нас появляются:
1. Богатые исходные данные
Не кнопки и не короткие фразы, а реальные содержательные ответы.
2. Параметризованный профиль
Можно сохранить:
-
архетип;
-
основной вектор;
-
поддерживающие векторы;
-
стадию;
-
домены;
-
напряжения и риски.
3. Основа для микросегментации
Дальше можно строить разную логику:
-
разные сценарии;
-
разную навигацию;
-
разный onboarding;
-
разную образовательную траекторию;
-
разную продуктовую подачу.
4. Персонализированную коммуникацию
После профилирования система уже может общаться не “со всеми одинаково”, а по-разному для разных типов пользователей.
То есть голосовое интервью даёт не просто распознанный текст.
Оно даёт сырьё для персонализации и построения интеллектуальной коммуникации.
Почему это сильный продуктовый паттерн
Обычно голосовой ввод воспринимают как “удобную кнопку микрофона”.
Но здесь видно, что он может работать намного глубже.
С помощью VoiceInput + LLMQuery можно строить:
-
голосовые onboarding-сценарии;
-
интеллектуальные intake-формы;
-
глубокую квалификацию;
-
профилирование;
-
AI-собеседования;
-
сервисные сценарии, где пользователю проще рассказать, чем напечатать.
Именно поэтому VoiceInput в Metabot — это не “опция”, а компонент, на котором можно строить новый класс продуктов.
Voice Route Guard
До этого мы рассматривали VoiceInput как локальный сценарный компонент:
-
сценарий явно ждёт голосовой ответ;
-
пользователь отвечает голосом;
-
текст распознаётся;
-
сценарий идёт дальше.
Но в реальном боте часто нужен другой режим:
пользователь может находиться в любом месте системы и в любой момент прислать голосовое сообщение.
В этот момент нужно решить:
-
игнорировать его;
-
оставить в текущем сценарии;
-
или перехватить голос и перевести пользователя в специальный голосовой маршрут.
Именно для этого используется Voice Route Guard.
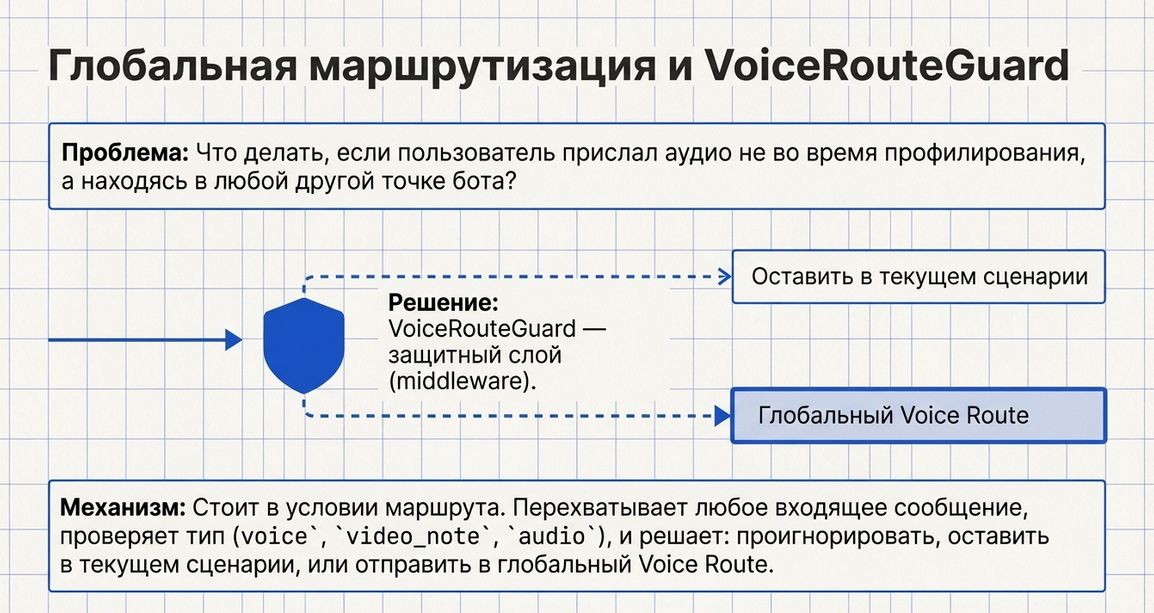
Что это
Voice Route Guard — это защитный и маршрутизирующий компонент для голосового ввода.
Он используется в условии маршрута и решает, можно ли в текущем контексте запускать глобальную обработку голосового сообщения.
То есть это не сам распознаватель голоса и не сам speech-to-text.
Это guard-слой, который:
-
смотрит на входящее сообщение;
-
понимает, голосовое оно или нет;
-
проверяет, разрешён ли сейчас глобальный voice input;
-
проверяет, не находится ли пользователь в защищённом flow;
-
проверяет, не выполняется ли защищённый script;
-
и только после этого разрешает или запрещает глобальный перехват.
Где находится
Пакет: Voice
Полное имя: Common.Voice.VoiceRouteGuard
Подключение:
const VoiceRouteGuard = require("Common.Voice.VoiceRouteGuard")Зачем он нужен
VoiceRouteGuard нужен, когда вы хотите построить глобальный голосовой вход в систему.
Например:
-
пользователь в любой момент может продиктовать запрос;
-
бот должен уметь “слушать” голос не только внутри одного вопроса;
-
голос может включать отдельный сценарий маршрутизации;
-
пользователь может переключиться с обычного текстового flow на голосовой режим “на ходу”.
Это уже не локальный VoiceInput.expect() внутри одного скрипта, а глобальный голосовой middleware для всего бота.
Как работает метод inspect
Главный метод компонента — inspect().
Он позволяет задать правила защиты маршрутов и проверить, можно ли сейчас запускать глобальную voice-обработку.
Типовой вызов:
const VoiceRouteGuard = require("Common.Voice.VoiceRouteGuard")
return VoiceRouteGuard.inspect({
lead,
protectedScripts: [
"VoiceInput_Processor",
"RAG:DetectIntent_and_FindChunks",
"STT:Transcriptions"
],
protectedFlows: ["corp_entry_flow"],
respectGlobalDisable: true
})Что проверяет inspect()
Компонент последовательно проверяет:
1. Что входящее сообщение действительно голосовое
Сейчас guard ориентирован прежде всего на Telegram и проверяет:
-
voice -
video_note audio
Если сообщение не голосовое, guard сразу возвращает false.
2. Не выключен ли голосовой ввод глобально
Если включён флаг respectGlobalDisable: true, компонент дополнительно смотрит, разрешён ли сейчас voice input глобально.
Это делается через сам компонент VoiceInput.
3. Не находится ли пользователь в защищённом flow
Если для текущего пользователя уже установлен защищённый flow, глобальный голосовой маршрут не должен перехватывать управление.
4. Не выполняется ли защищённый script
Если сейчас идёт callback или асинхронный сценарий из списка защищённых скриптов, голосовой маршрут не должен влезать поверх него.
Глобальное включение и выключение голосового ввода
Глобальный тумблер находится в самом компоненте VoiceInput.
То есть Voice Route Guard не хранит этот флаг сам — он проверяет его через VoiceInput.isEnabled().
Как включить голосовой ввод
const VoiceInput = require("Common.Voice.VoiceInput")
VoiceInput.enable(lead)Как выключить голосовой ввод
const VoiceInput = require("Common.Voice.VoiceInput")
VoiceInput.disable(lead)Как guard учитывает этот флаг
Если в VoiceRouteGuard.inspect() указано:
respectGlobalDisable: trueто перед запуском глобальной обработки компонент проверит, включён ли voice input для этого лида.
Если он выключен, глобальный перехват не сработает.
Когда это полезно
Глобальное отключение удобно, если вы хотите:
-
временно запретить голосовой ввод в конкретном диалоге;
-
отключить voice routing для конкретного пользователя;
-
переключить бота в “только текстовый” режим;
-
не давать глобальному voice-маршруту вмешиваться в чувствительные сценарии.
Защита маршрутов: скрипты, flow и глобальный режим

У VoiceRouteGuard три уровня контроля.
1. Защита отдельных скриптов
Через protectedScripts можно указать конкретные скрипты, внутри которых глобальный voice route не должен вмешиваться.
Пример:
protectedScripts: [
"VoiceInput_Processor",
"RAG:DetectIntent_and_FindChunks",
"STT:Transcriptions"
]Это полезно, когда вы хотите очень точно указать:
-
вот эти конкретные сценарии нельзя перебивать;
-
если пользователь прислал голос в этот момент, глобальный route должен промолчать.
Это самый точный уровень защиты.
2. Защита целого flow
Через protectedFlows можно защитить сразу целый контур сценариев.
Пример:
protectedFlows: ["corp_entry_flow"]Это удобнее, когда у вас много скриптов внутри одного процесса и не хочется перечислять их по одному.
Например:
-
идёт профилирование;
-
или onboarding;
-
или голосовое интервью;
-
или сервисный flow из нескольких шагов.
Тогда проще сказать:
если пользователь внутри этого flow, глобальный voice route не трогает его.
Это более высокий и более удобный уровень защиты.
3. Глобальное отключение
Через VoiceInput.disable(lead) можно вообще выключить глобальный voice input для пользователя.
Это самый широкий уровень контроля.
Как лучше мыслить про уровни защиты
Практически удобно думать так:
-
если нужно точечно — защищайте конкретные
scripts; -
если нужно защитить процесс целиком — используйте
protectedFlows; -
если нужно отключить механику вообще — используйте глобальный disable через
VoiceInput.
То есть логика идёт:
script → flow → global
Как настроить глобальный голосовой маршрут
Чтобы глобальный голосовой перехват вообще работал, нужно создать отдельный route в боте.
Этот маршрут должен быть:
-
с высоким приоритетом;
-
активен в диалоге;
-
доступен на любом вводе;
-
расположен выше обычных маршрутов;
-
слушать вообще любой входящий input.
Что указать в route
Регулярное выражение
Для глобального перехвата используйте:
:FLAGS[EMPTY,ANY]Это позволяет маршруту реагировать на любой ввод, а уже внутри VoiceRouteGuard.inspect() решать, нужно ли что-то делать именно с этим сообщением.
Что должно быть в condition script
В condition script маршрута нужно вызвать VoiceRouteGuard.inspect(...).
Именно он определяет:
-
голос это или нет;
-
можно ли его сейчас перехватывать;
-
не запрещён ли текущий контекст.
К какому скрипту должен вести маршрут
Этот глобальный маршрут должен быть прикреплён к отдельному скрипту обработки голосового маршрута.
То есть логика такая:
Любой вход
→ глобальный route
→ VoiceRouteGuard.inspect()
→ если true
→ переход в voice-routing scriptА уже внутри этого voice-routing script вы можете:
-
распознать голос;
-
проанализировать intent;
-
определить, что сказал пользователь;
-
перевести его в нужный flow или нужный сценарий бота.
Это уже не просто распознавание аудио, а глобальная голосовая маршрутизация.
Пример логики глобального voice route
Практически это может выглядеть так:
-
Пользователь находится где угодно в боте
-
Отправляет голосовое сообщение
-
Глобальный маршрут ловит любой input
-
VoiceRouteGuard.inspect()проверяет контекст -
Если можно — управление уходит в специальный сценарий
-
Там голос распознаётся и дальше маршрутизируется по смыслу
Например:
-
пользователь сказал “хочу поговорить про цены”;
-
или “мне нужна помощь по заказу”;
-
или “переведи меня в другой раздел”.
После этого бот может сам определить intent и включить нужную логику.
Flow Context
Чтобы VoiceRouteGuard понимал, в каком процессе сейчас находится пользователь, используется компонент FlowContext.
Что это
FlowContext — это простой платформенный компонент для хранения текущего flow в lead.
Он сам по себе не делает маршрутизацию.
Он просто записывает идентификатор текущего контекста, чтобы другие компоненты могли на него опираться.
Где находится
Пакет: Platform
Полное имя: Common.Platform.FlowContext
Подключение:
const FlowContext = require("Common.Platform.FlowContext")Как использовать
Когда вы хотите управлять тем, в каком flow сейчас находится пользователь, устанавливайте FlowContext в entry script сценария.
Пример:
const FlowContext = require("Common.Platform.FlowContext")
FlowContext.set(lead, "corp_entry_flow")После этого VoiceRouteGuard сможет использовать protectedFlows не “вслепую”, а по реальному текущему состоянию пользователя.
Зачем это нужно
Если у вас длинный сценарный контур из нескольких скриптов, гораздо удобнее защитить один flow, чем перечислять все скрипты вручную.
То есть для управления защищёнными flow используйте именно FlowContext.
Практический паттерн такой:
-
при входе в сценарный контур установить
FlowContext.set(...) -
в
VoiceRouteGuard.inspect()указать этот flow вprotectedFlows -
при выходе из контура — очистить flow, если нужно
Как очистить flow
const FlowContext = require("Common.Platform.FlowContext")
FlowContext.clear(lead)Когда использовать локальный Voice Input, а когда глобальный Voice Route Guard

Это два разных паттерна.
Используйте VoiceInput.expect(), когда:
-
сценарий явно ждёт голосовой ответ;
-
пользователь отвечает на конкретный вопрос;
-
голос — это локальный шаг внутри flow;
-
вы строите интервью, onboarding, профилирование, анкету.
Используйте VoiceRouteGuard, когда:
-
хотите слушать голос глобально по всему боту;
-
хотите сделать voice routing;
-
пользователь может в любой момент “переключиться на голос”;
-
голосовое сообщение должно вести в отдельный сценарий обработки.
Очень часто в одном проекте используются оба режима:
-
локальный voice input внутри специальных сценариев;
-
и глобальный voice route поверх всей системы.
Как отлаживать Voice Input и Voice Route Guard
При проблемах с голосовым пайплайном проверяйте систему по слоям.

1. Настройки канала
Проверьте, что в канале включены:
-
Реакция на аудио:
Штатная (NLP и меню) -
Реакция на голосовые сообщения:
Штатная (NLP и меню)
2. Processor script
Убедитесь, что существует скрипт:
VoiceInput_Processorи внутри него есть две команды:
-
Run JavaScript Callback -
Run asynchronous API-request
3. Bot attrs
Проверьте:
-
METABOT_API_TOKEN -
METABOT_SERVER_DOMAIN
4. STT token
Проверьте, что tokenKey указывает на существующий bot-атрибут с ключом провайдера.
5. Source и target attrs
Убедитесь, что:
-
в
sourceAttrсохранилась ссылка на файл; -
в
targetAttrсохранился распознанный текст.
6. Логика guard
Если глобальный voice route не срабатывает, проверьте:
-
что route стоит высоко в списке;
-
что у него regex
:FLAGS[EMPTY,ANY]; -
что condition script вызывает
VoiceRouteGuard.inspect(...); -
что голосовой ввод глобально не отключён через
VoiceInput.disable(lead); -
что пользователь не находится в
protectedFlow; -
что текущий callback / script не защищён через
protectedScripts.
7. Дальнейший AI-анализ
Если после распознавания текста вы передаёте результат в LLMQuery, дальнейшую диагностику смотрите уже в разделе про:
-
LLMQuery -
трассировку
-
LLMClient -
observability
Кратко
Voice Route Guard — это компонент защиты и маршрутизации для глобального голосового ввода.
Он позволяет:
-
слушать голосовые сообщения глобально;
-
защищать отдельные скрипты;
-
защищать целые flow;
-
учитывать глобальное включение и выключение voice input;
-
аккуратно встраивать голосовой роутинг в уже работающего бота.
А FlowContext помогает управлять тем, какой сценарный контур сейчас активен у пользователя, чтобы voice routing был точным и не ломал текущую логику.
Что изучать дальше
Если вы уже разобрались с VoiceInput, дальше логично изучить следующие компоненты Metabot Agent Stack:
LLMQuery
Если вы ещё не знакомы с ним — это следующий обязательный шаг.
Именно он позволяет превращать распознанную речь в:
-
structured JSON,
-
intent,
-
summaries,
-
профили,
-
отражения,
-
управляемые AI-ответы.
Knowledge Base Search
Если вы хотите, чтобы после голосового ввода система не только анализировала речь, но и опиралась на знания компании, изучите компонент поиска по базе знаний.
Трассировка и observability
Если вы строите реальные AI-сценарии, обязательно изучите:
-
трассировку,
-
observability,
-
диагностику вызовов,
-
таблицы логов.
LLMClient
Если вам нужен более глубокий инженерный контроль над transport layer, callback, provider behavior и логикой работы моделей, переходите к низкоуровневому компоненту LLMClient.
Prompt Registry
Если вы хотите выносить промпты из кода и управлять ими централизованно, следующий полезный раздел — Prompt Registry.
Нет комментариев